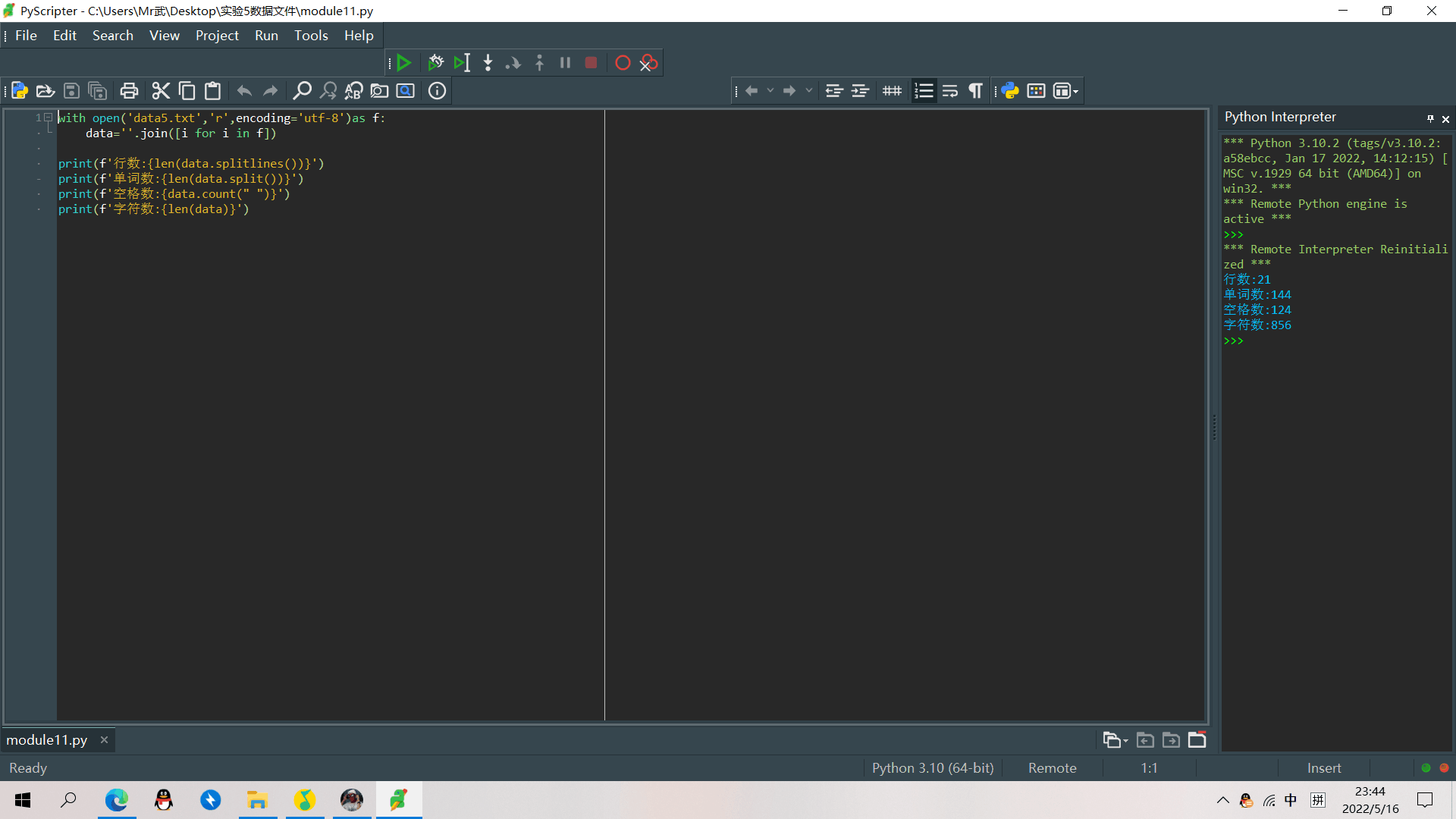
with open('data3.txt', 'r', encoding='utf-8') as f:
data = f.read().split('\n')
yuanshishuju = data.pop(0)
data1 = [eval(i) for i in data]
data2 = [round(i) for i in data1]
print(f'{yuanshishuju}:\n{data1}')
print(f'四舍五入后数据:\n{data2}')
with open('jishiben.txt','w',encoding='utf-8') as f:
list=['原始数据']+[str(i) for i in data1]
list1=['四舍五入后数据']+[str(i) for i in data2]
for i in range(len(data)):
f.write(f'{list[i]}\t{list1[i]}\n')
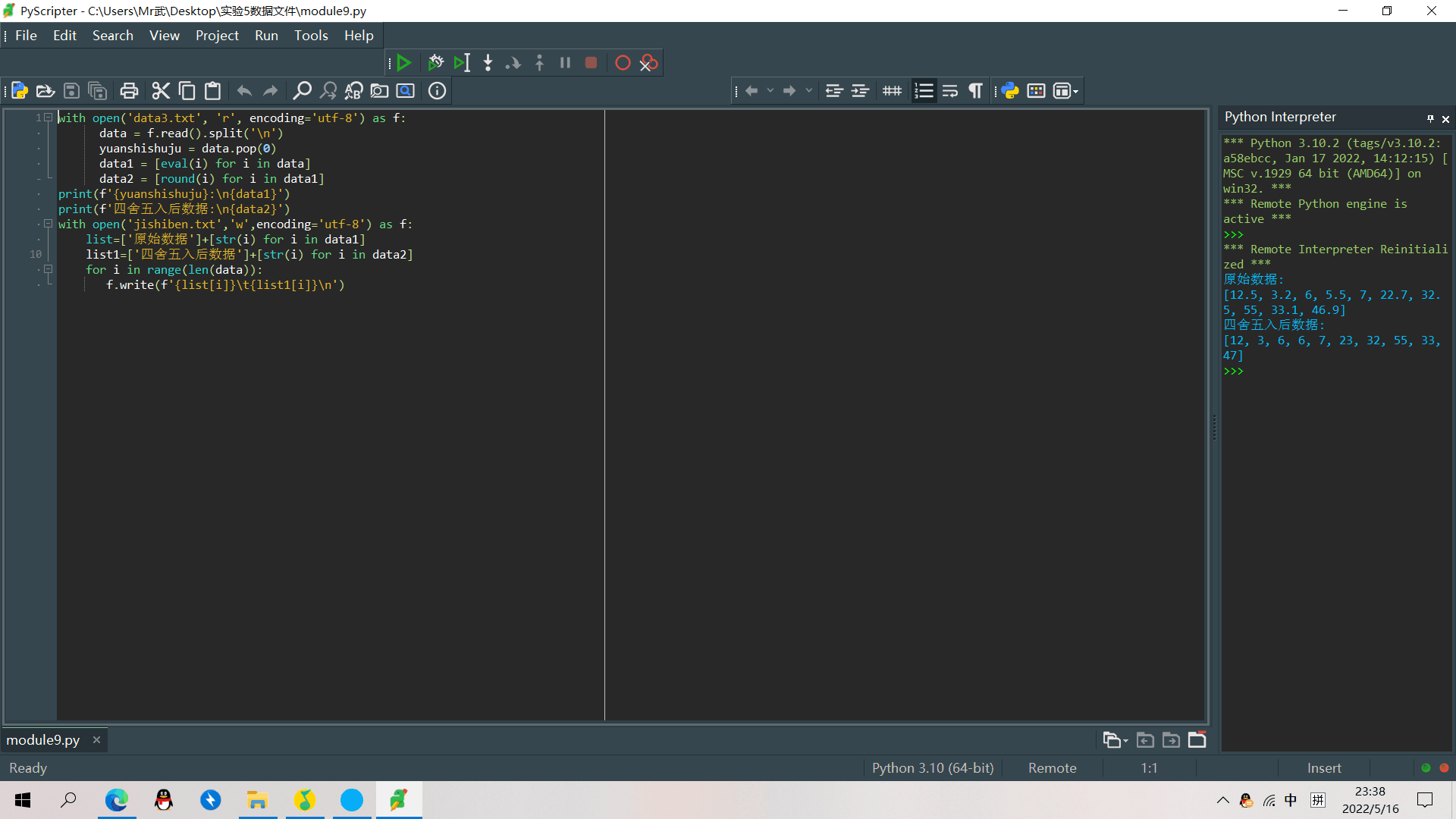
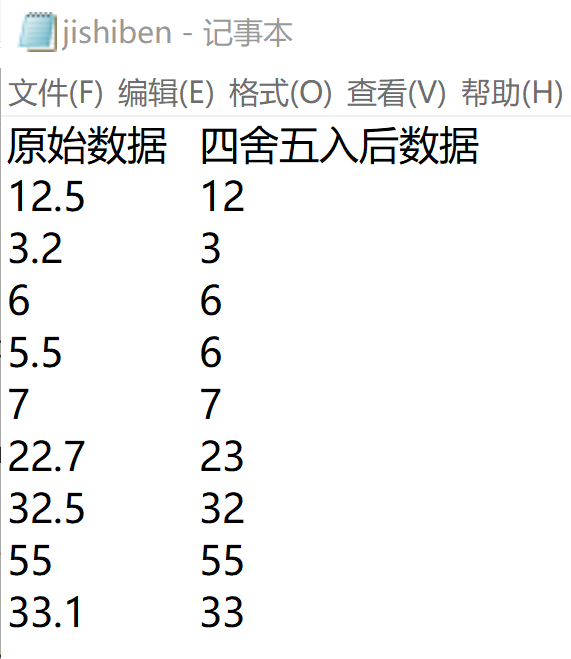
with open('data4.txt','r',encoding='utf-8') as f:
list=[i.strip('\n').split('\t') for i in f]
a=list.pop(0)
list.sort(key=lambda x:(x[2],-int(x[3])))
print('\t'.join(a))
for i in list:
print('\t'.join(i))
with open('data4jishiben.txt','w',encoding='utf-8')as f:
f.write('\t'.join(a))
f.write('\n')
for i in list:
f.write('\t'.join(i))
f.write('\n')

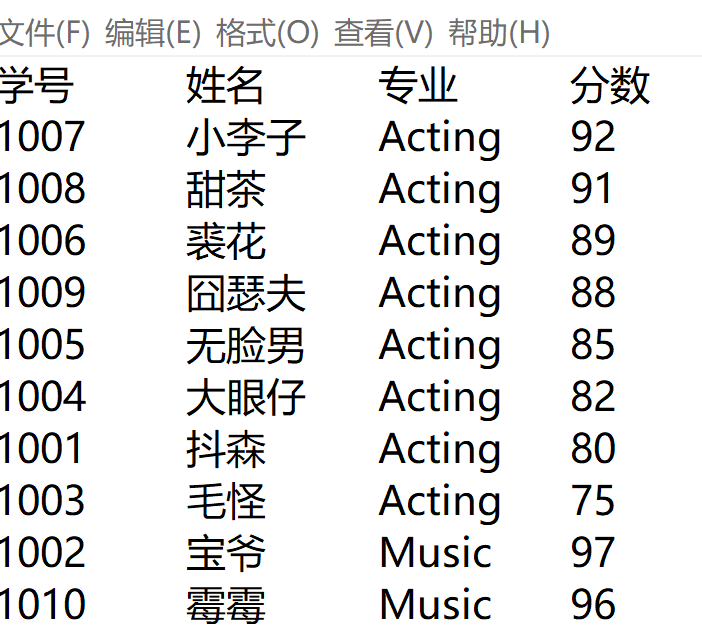
with open('data5.txt','r',encoding='utf-8')as f:
data=''.join([i for i in f])
print(f'行数:{len(data.splitlines())}')
print(f'单词数:{len(data.split())}')
print(f'空格数:{data.count(" ")}')
print(f'字符数:{len(data)}')