tensorflow
此篇笔记参考来源为《莫烦Python》
tensorflow安装
在命令行模式下进入到python安装目录中的Scripts下,例如我的安装路径为:D:\Program Files (x86)\Python\Scripts
安装CPU版本的:
pip3 install --upgrade tensorflow
GPU版本:
pip3 install --upgrade tensorflow-gpu
心酸啊,一开始使用这种方法超时了,想想就试着装一个anaconda吧,成功安装好了之后,但是IDLE中导入错误,布吉岛要怎么弄,以后看看,最后还是回到上面这种方法成功啦,总之成功就很好啦嘿嘿。
Tensorflow基础架构
2.1 处理结构
Tensorflow 首先要定义神经网络的结构, 然后再把数据放入结构当中去运算和 training.
因为TensorFlow是采用数据流图(data flow graphs)来计算, 所以首先我们得创建一个数据流流图, 然后再将我们的数据(数据以张量(tensor)的形式存在)放在数据流图中计算.
节点(Nodes)在图中表示数学操作,图中的线(edges)则表示在节点间相互联系的多维数据数组, 即张量(tensor).
训练模型时tensor会不断的从数据流图中的一个节点flow到另一节点, 这就是TensorFlow名字的由来.
张量(Tensor):
- 张量有多种. 零阶张量为 纯量或标量 (scalar) 也就是一个数值. 比如
[1] - 一阶张量为 向量 (vector), 比如 一维的
[1, 2, 3] - 二阶张量为 矩阵 (matrix), 比如 二维的
[[1, 2, 3],[4, 5, 6],[7, 8, 9]] - 以此类推, 还有 三阶 三维的 …
2.2 举例
本节的例子y = weight * x + biases,其中weight应等于0.1,biases等于0.3,给定一定的范围,经过训练学习后使得这两个值接近正确值。
主要流程为:创建数据→搭建模型→计算误差→传播误差→训练
import tensorflow as tf import numpy as np #创建数据 x_data = np.random.rand(100).astype(np.float32) y_data = x_data*0.1 + 0.3 #搭建模型 Weights = tf.Variable(tf.random_uniform([1],-1.0,1.0)) biases = tf.Variable(tf.zeros([1])) y = Weights*x_data + biases #计算误差 loss = tf.reduce_mean(tf.square(y-y_data)) #传播误差 optimizer = tf.train.GradientDescentOptimizer(0.5) train = optimizer.minimize(loss) #训练 init = tf.global_variables_initializer() #初始化所有变量 sess = tf.Session() #创建会话 sess.run(init) for step in range(201): sess.run(train) if step%20 == 0: print(step,sess.run(Weights),sess.run(biases))
每20次输出:
0 [0.6186284] [0.02014087] 20 [0.24663956] [0.22072376] 40 [0.14147906] [0.2775756] 60 [0.11173292] [0.29365695] 80 [0.10331883] [0.2982058] 100 [0.10093877] [0.29949248] 120 [0.10026555] [0.29985645] 140 [0.1000751] [0.2999594] 160 [0.10002125] [0.29998854] 180 [0.10000604] [0.29999676] 200 [0.1000017] [0.2999991]
2.3 Session 会话控制
Session 是 Tensorflow 为了控制和输出文件的执行的语句. 运行 session.run() 可以获得你要得知的运算结果, 或者是你所要运算的部分
如下所示,有两种打开方式
import tensorflow as tf matrix1 = tf.constant([[3, 3]]) matrix2 = tf.constant([[2], [2]]) product = tf.matmul(matrix1, matrix2) # method 1 sess = tf.Session() result = sess.run(product) print(result) sess.close() # method 2 with tf.Session() as sess: result2 = sess.run(product) print(result2)
2.4 Variable 变量
在 Tensorflow 中,定义了某字符串是变量,它才是变量,这一点是与 Python 所不同的
如果你在 Tensorflow 中设定了变量,那么初始化变量是最重要的!!所以定义了变量以后, 一定要定义 init = tf.global_variables_initializer()
import tensorflow as tf state = tf.Variable(0,name='counter') one = tf.constant(1) new_value = tf.add(state,one) update = tf.assign(state,new_value) init = tf.global_variables_initializer() with tf.Session() as sess: sess.run(init) for _ in range(3): sess.run(update) print(sess.run(state))
注意:直接 print(state) 不起作用!!
一定要把 sess 的指针指向 state 再进行 print 才能得到想要的结果
2.5 Placeholder 传入值
Tensorflow 中的占位符,暂时储存变量
Tensorflow 如果想要从外部传入data, 那就需要用到 tf.placeholder(), 然后以这种形式传输数据 sess.run(***, feed_dict={input: **}).
import tensorflow as tf input1 = tf.placeholder(tf.float32) input2 = tf.placeholder(tf.float32) output = tf.multiply(input1, input2) with tf.Session() as sess: print(sess.run(output,feed_dict={input1:[7.],input2:[2.]})) #[14.]
建造我们第一个神经网络
3.1 添加层 + 3.2 建造神经网络
在 Tensorflow 里定义一个添加层的函数可以很容易的添加神经层,为之后的添加省下不少时间
神经层里常见的参数通常有weights、biases和激励函数
import tensorflow as tf import numpy as np #添加层函数 def add_layer(inputs,in_size,out_size,activation_function=None): #生成初始参数时,随机变量会比0好得多 #因此将weights设置为一个in_size行,out_size列的随机变量矩阵 Weights = tf.Variable(tf.random_normal([in_size,out_size])) biases = tf.Variable(tf.zeros([1, out_size]) + 0.1) #biase初始推荐值不为0,因此加上了0.1 Wx_plus_b = tf.matmul(inputs,Weights) + biases if activation_function is None: outputs = Wx_plus_b else: outputs = activation_function(Wx_plus_b) return outputs #导入数据,x_data和y_data并不是严格的一元二次的函数的关系,因为加上了noise x_data = np.linspace(-1,1,300)[:,np.newaxis] noise = np.random.normal(0, 0.05, x_data.shape).astype(np.float32) y_data = np.square(x_data)-0.5 + noise #None表示无论输入有多少都可以,1表示输入特征为1 xs = tf.placeholder(tf.float32, [None, 1]) ys = tf.placeholder(tf.float32, [None, 1]) #定义神经网络,设输入层1,隐藏层10个神经元,输出1 l1 = add_layer(xs,1,10,activation_function=tf.nn.relu) prediction = add_layer(l1, 10, 1, activation_function=None) #计算误差 对二者差的平方求和再取平均 loss = tf.reduce_mean(tf.reduce_sum(tf.square(ys - prediction), reduction_indices=[1])) #括号内为学习效率,学习效率取值一般为0-1 train_step = tf.train.GradientDescentOptimizer(0.1).minimize(loss) init = tf.global_variables_initializer() sess = tf.Session() sess.run(init) for i in range(1000): sess.run(train_step,feed_dict={xs:x_data,ys:y_data}) if i % 50 == 0: print(sess.run(loss, feed_dict={xs: x_data, ys: y_data}))
输出结果为:
0.97041506 0.09610467 0.031043218 0.0101252915 0.0061697583 0.0053026895 0.004896072 0.0045539285 0.004274694 0.0040821745 0.0039111846 0.0037767517 0.0036670212 0.0035742708 0.0035026888 0.003447328 0.0034014261 0.003367049 0.003340406 0.0033207028
3.3 结果可视化
在3.1和3.2的基础上,将结果用图形表示出来
首先,用散点图描述数据之间的真实关系
fig = plt.figure() ax = fig.add_subplot(1,1,1) ax.scatter(x_data,y_data) plt.ion() #连续显示 plt.show()
结果如下所示:

接着,显示预测数据,每隔50次训练刷新一次图像,用红色、宽度为5的先来显示预测数据和输入之间的关系
for i in range(1000): #traning sess.run(train_step,feed_dict={xs:x_data,ys:y_data}) if i % 50 == 0: try: ax.lines.remove(lines[0]) except Exception: pass prediction_value = sess.run(prediction,feed_dict={xs:x_data}) lines = ax.plot(x_data,prediction_value,'r--',lw=5) plt.pause(0.1)
最终的学习结果为: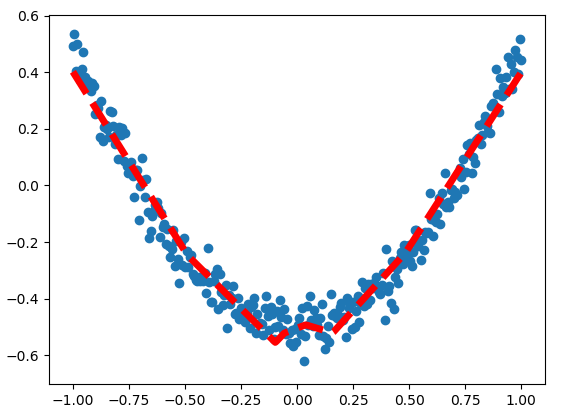
可视化好助手 Tensorboard
4.1 可视化好助手 Tensorboard1
首先从input开始,给xs和ys命名,使用with tf.name_scope('inputs')可以将xs和ys包含进来,形成一个大的图层,图层的名字就是with tf.name_scope()方法里的参数,其他的类似
完整代码如下:
import tensorflow as tf import numpy as np def add_layer(inputs,in_size,out_size,activation_function=None): with tf.name_scope('layer'): with tf.name_scope('weights'): Weights = tf.Variable(tf.random_normal([in_size,out_size])) with tf.name_scope('biases'): biases = tf.Variable(tf.zeros([1, out_size]) + 0.1) with tf.name_scope('Wx_plus_b'): Wx_plus_b = tf.matmul(inputs,Weights) + biases if activation_function is None: outputs = Wx_plus_b else: outputs = activation_function(Wx_plus_b) return outputs x_data = np.linspace(-1,1,300)[:,np.newaxis] noise = np.random.normal(0, 0.05, x_data.shape).astype(np.float32) y_data = np.square(x_data)-0.5 + noise with tf.name_scope('inputs'): xs = tf.placeholder(tf.float32, [None, 1],name='x_input') ys = tf.placeholder(tf.float32, [None, 1],name='y_input') l1 = add_layer(xs,1,10,activation_function=tf.nn.relu) prediction = add_layer(l1, 10, 1, activation_function=None) with tf.name_scope('loss'): loss = tf.reduce_mean(tf.reduce_sum(tf.square(ys - prediction), reduction_indices=[1])) with tf.name_scope('train'): train_step = tf.train.GradientDescentOptimizer(0.1).minimize(loss) init = tf.global_variables_initializer() sess = tf.Session() writer = tf.summary.FileWriter("C://Users//Administrator//Desktop//logs", sess.graph) sess.run(init)
按照教程中,在浏览器中我一直打不开,显示拒绝了连接请求。
教程中的方法为,在命令行中,到达你存放文件的上一层目录下。然后输入:
tensorboard --logdir logs
将地址复制到chrome浏览器中打开,或者使用http://localhost:6006打开
多次尝试我还是打不开,作了以下修改后能打开:
(1)将tf.summary.FileWriter中的地址写详细,如上所示
(2) 输入命令:
tensorboard --logdir="C://Users//Administrator//Desktop//logs" --port=6006

先不要通过ctrl+C退出,直接将上述地址输入到chrome浏览器中即可打开
一般将train选择
结果如下所示:
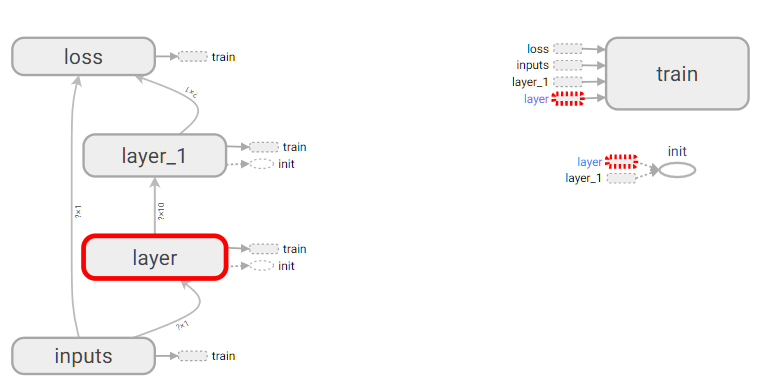
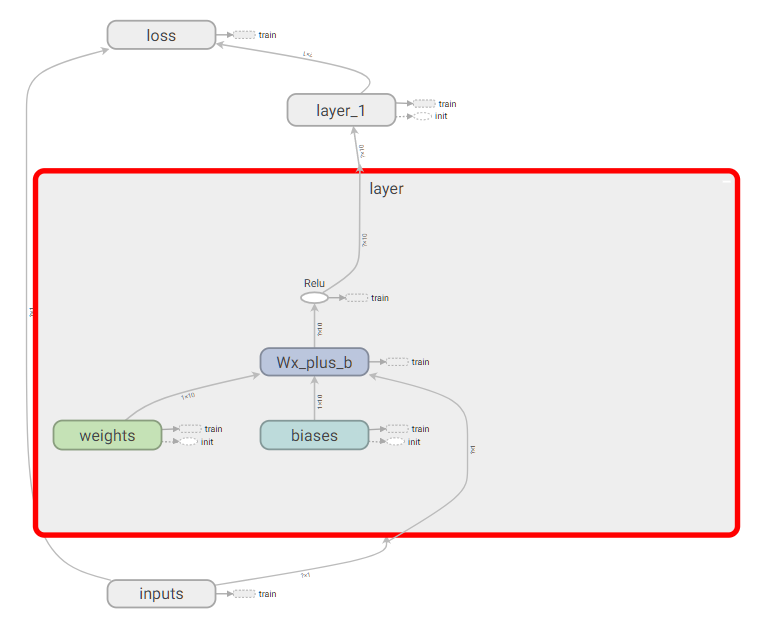
4.2 可视化好助手 Tensorboard2
本节主要讲述为Weights、biases、loss绘制变化图,并将所有训练图合并
import tensorflow as tf import numpy as np def add_layer(inputs, in_size, out_size, n_layer, activation_function=None): # add one more layer and return the output of this layer layer_name = 'layer%s' % n_layer with tf.name_scope(layer_name): with tf.name_scope('weights'): Weights = tf.Variable(tf.random_normal([in_size, out_size]), name='W') tf.summary.histogram(layer_name + '/weights', Weights) with tf.name_scope('biases'): biases = tf.Variable(tf.zeros([1, out_size]) + 0.1, name='b') tf.summary.histogram(layer_name + '/biases', biases) with tf.name_scope('Wx_plus_b'): Wx_plus_b = tf.add(tf.matmul(inputs, Weights), biases) if activation_function is None: outputs = Wx_plus_b else: outputs = activation_function(Wx_plus_b, ) tf.summary.histogram(layer_name + '/outputs', outputs) return outputs # Make up some real data x_data = np.linspace(-1, 1, 300)[:, np.newaxis] noise = np.random.normal(0, 0.05, x_data.shape) y_data = np.square(x_data) - 0.5 + noise # define placeholder for inputs to network with tf.name_scope('inputs'): xs = tf.placeholder(tf.float32, [None, 1], name='x_input') ys = tf.placeholder(tf.float32, [None, 1], name='y_input') # add hidden layer l1 = add_layer(xs, 1, 10, n_layer=1, activation_function=tf.nn.relu) # add output layer prediction = add_layer(l1, 10, 1, n_layer=2, activation_function=None) # the error between prediciton and real data with tf.name_scope('loss'): loss = tf.reduce_mean(tf.reduce_sum(tf.square(ys - prediction), reduction_indices=[1])) tf.summary.scalar('loss', loss) with tf.name_scope('train'): train_step = tf.train.GradientDescentOptimizer(0.1).minimize(loss) sess = tf.Session() merged = tf.summary.merge_all() writer = tf.summary.FileWriter("C://Users//Administrator//Desktop//logs", sess.graph) init = tf.global_variables_initializer() sess.run(init) for i in range(1000): sess.run(train_step, feed_dict={xs: x_data, ys: y_data}) if i % 50 == 0: result = sess.run(merged, feed_dict={xs: x_data, ys: y_data}) writer.add_summary(result, i)
高阶内容
Classification 分类学习
分类和回归的区别在于输出变量的类型上。
通俗理解定量输出是回归,或者说是连续变量预测; 定性输出是分类,或者说是离散变量预测。
本节使用到MNIST手写体数字库,数据中包含55000张训练图片,每张图片的分辨率是28×28,所以我们的训练网络输入应该是28×28=784个像素数据。每张图片代表一个数字,所以输出为数字0-9,共10类
搭建的训练网络结构,只有输入层和输出层。其中输入数据是784个特征,输出数据是10个特征,激励采用softmax函数,网络结构图是这样子的
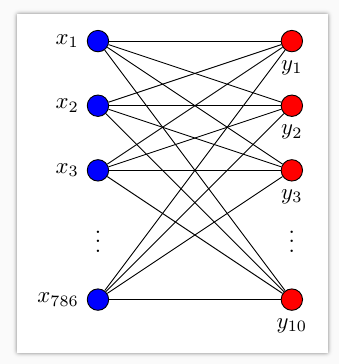
loss函数(即最优化目标函数)选用交叉熵函数。交叉熵用来衡量预测值和真实值的相似程度,如果完全相同,它们的交叉熵等于零
train方法(最优化算法)采用梯度下降法
完整代码如下:
from __future__ import print_function import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data # number 1 to 10 data mnist = input_data.read_data_sets('MNIST_data', one_hot=True) def add_layer(inputs, in_size, out_size, activation_function=None,): # add one more layer and return the output of this layer Weights = tf.Variable(tf.random_normal([in_size, out_size])) biases = tf.Variable(tf.zeros([1, out_size]) + 0.1,) Wx_plus_b = tf.matmul(inputs, Weights) + biases if activation_function is None: outputs = Wx_plus_b else: outputs = activation_function(Wx_plus_b,) return outputs def compute_accuracy(v_xs, v_ys): global prediction y_pre = sess.run(prediction, feed_dict={xs: v_xs}) correct_prediction = tf.equal(tf.argmax(y_pre,1), tf.argmax(v_ys,1)) accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32)) result = sess.run(accuracy, feed_dict={xs: v_xs, ys: v_ys}) return result # define placeholder for inputs to network xs = tf.placeholder(tf.float32, [None, 784]) # 28x28 ys = tf.placeholder(tf.float32, [None, 10]) # add output layer prediction = add_layer(xs, 784, 10, activation_function=tf.nn.softmax) # the error between prediction and real data cross_entropy = tf.reduce_mean(-tf.reduce_sum(ys * tf.log(prediction), reduction_indices=[1])) train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy) sess = tf.Session() sess.run(tf.global_variables_initializer()) for i in range(1000): batch_xs, batch_ys = mnist.train.next_batch(100) sess.run(train_step, feed_dict={xs: batch_xs, ys: batch_ys}) if i % 50 == 0: print(compute_accuracy( mnist.test.images, mnist.test.labels))
结果为
0.1444 0.655 0.743 0.7827 0.8047 0.8147 0.8291 0.8371 0.838 0.8456 0.8547 0.8514 0.86 0.8589 0.8648 0.8605 0.8649 0.8706 0.8709 0.8714
Dropout 解决 overfitting
CNN卷积神经网络
主要为通过CNN来实现一个机遇MNIST的例子,主要为定义卷积层函数、pooling函数
建立卷积层、全连接层、选择优化方法等
Saver 保存读取
import tensorflow as tf import numpy as np #保存 W = tf.Variable([[1,2,3],[3,4,5]],dtype=tf.float32,name='weights') b = tf.Variable([[1,2,3]],dtype=tf.float32,name='biases') init = tf.global_variables_initializer() saver = tf.train.Saver() with tf.Session() as sess: sess.run(init) save_path = saver.save(sess,'logs/save_net.ckpt') print("Save to path:",save_path) #提取 W = tf.Variable(np.arange(6).reshape((2, 3)), dtype=tf.float32, name="weights") b = tf.Variable(np.arange(3).reshape((1, 3)), dtype=tf.float32, name="biases") saver = tf.train.Saver() with tf.Session() as sess: saver.restore(sess,'logs/save_net.ckpt') print('Weights:',sess.run(W)) print('biases:',sess.run(b)) """ weights: [[ 1. 2. 3.] [ 3. 4. 5.]] biases: [[ 1. 2. 3.]] """
RNN LSTM 循环神经网络(分类例子)
RNN LSTM(回归例子)
自编码 Autoencoder(非监督学习)
Scope 命名方法
在 Tensorflow 当中有两种途径生成变量 variable, 一种是 tf.get_variable(), 另一种是 tf.Variable(). 如果在 tf.name_scope() 的框架下使用这两种方式, 结果如下
import tensorflow as tf with tf.name_scope("a_name_scope"): initializer = tf.constant_initializer(value=1) var1 = tf.get_variable(name='var1', shape=[1], dtype=tf.float32, initializer=initializer) var2 = tf.Variable(name='var2', initial_value=[2], dtype=tf.float32) var21 = tf.Variable(name='var2', initial_value=[2.1], dtype=tf.float32) var22 = tf.Variable(name='var2', initial_value=[2.2], dtype=tf.float32) with tf.Session() as sess: sess.run(tf.global_variables_initializer()) print(var1.name) # var1:0 print(sess.run(var1)) # [ 1.] print(var2.name) # a_name_scope/var2:0 print(sess.run(var2)) # [ 2.] print(var21.name) # a_name_scope/var2_1:0 print(sess.run(var21)) # [ 2.0999999] print(var22.name) # a_name_scope/var2_2:0 print(sess.run(var22)) # [ 2.20000005]
使用 tf.Variable() 定义的时候, 虽然 name 都一样, 但是为了不重复变量名, Tensorflow 输出的变量名并不是一样的. 所以, 本质上 var2, var21, var22 并不是一样的变量. 而另一方面, 使用tf.get_variable()定义的变量不会被tf.name_scope()当中的名字所影响
如果想要达到重复利用变量的效果, 我们就要使用 tf.variable_scope(), 并搭配 tf.get_variable()这种方式产生和提取变量. 不像 tf.Variable() 每次都会产生新的变量, tf.get_variable() 如果遇到了同样名字的变量时, 它会单纯的提取这个同样名字的变量(避免产生新变量). 而在重复使用的时候, 一定要在代码中强调 scope.reuse_variables(), 否则系统将会报错, 以为你只是单纯的不小心重复使用到了一个变量
with tf.variable_scope("a_variable_scope") as scope: initializer = tf.constant_initializer(value=3) var3 = tf.get_variable(name='var3', shape=[1], dtype=tf.float32, initializer=initializer) scope.reuse_variables() var3_reuse = tf.get_variable(name='var3',) var4 = tf.Variable(name='var4', initial_value=[4], dtype=tf.float32) var4_reuse = tf.Variable(name='var4', initial_value=[4], dtype=tf.float32) with tf.Session() as sess: sess.run(tf.global_variables_initializer()) print(var3.name) # a_variable_scope/var3:0 print(sess.run(var3)) # [ 3.] print(var3_reuse.name) # a_variable_scope/var3:0 print(sess.run(var3_reuse)) # [ 3.] print(var4.name) # a_variable_scope/var4:0 print(sess.run(var4)) # [ 4.] print(var4_reuse.name) # a_variable_scope/var4_1:0 print(sess.run(var4_reuse)) # [ 4.]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号