【《超标量处理器基础》学习笔记一】处理器设计
本系列为《超标量处理器基础》学习笔记,多数为书中内容,摘取感兴趣的部分稍作整理。
体系结构指指令集体系结构,即指令集的规范,而微体系结构是指体系结构的具体逻辑实现,同一种指令集体系结构可以用不同的微体系结构,并采用不同的流水线设计,不同的分支预测算法等。
微体系结构的多样性使得同一种体系结构能够不断地推陈出新,并利用新出现的微体系结果技术来提高微处理器的性能,同时又保持代码的兼容性。
微处理器是指令集处理器(ISP, Instruction Set Processor)。ISP执行预先定义指令集中的指令。微处理器的功能几乎完全取决于指令集,从而表明了它的执行能力。所有运行于微处理器上的程序都要基于指令集进行编码。预定义的指令集称为指令集体系结构(ISA, Instruction Set Architecture)。ISA是软件与硬件之间的接口,或者是程序与处理器之间的接口。ISA是设计的规范,而微处理器或ISP是设计的实现。
微处理器的发展符合摩尔定律,即在单个芯片上的器件集成度将以每18个月到24个月的速度翻一番。

体系结构、逻辑实现和物理实现
体系结构规定了处理器的功能性行为,逻辑实现是实现体系结构的逻辑结构和组织,物理实现是逻辑实现的物理结构和具体表现形式。
体系结构对指令集处理器的指令集合进行说明。为了能被处理器执行,所有的软件都必须与指令集匹配、或者用该指令集进行编码。每个程序都被编译成这个指令集的一个指令序列。
逻辑实现就是体系结构的具体设计,也称为微体系结构。某种体系结构在它的ISA生命周期内可以有许多逻辑实现。对于在这个ISA上编写的任何程序,同一体系结构的所有逻辑实现都可以执行。与逻辑实现相关的一些概念包括流水线设计、cache存储器和分支预测器。
物理实现是设计的具体物理表现形式,通常是单芯片或多芯片的封装。对于一个逻辑实现,可以有许多不同的物理实现,按时钟频率、cache存储器容量、总线接口、结构技术及封装等方面的差异而具有不同的形式。
ISA
1.指令集体系结构将软件与硬件或者程序与处理器之间的开发独立开来。程序可以根据ISA的规定进行开发,而不理会实际机器的实现细节,反之亦然。ISA较少重新编译和开发,对于新出现的ISA,开发与其相配套的编译器和操作系统将需要花费10年以上的时间。ISA存在的时间越长,基于这个ISA的软件应用基础将越大,将来取代这个ISA的困难就越大。
2.ISA是微处理器设计的规范,所有的实现必须满足这个规范并支持ISA规定的功能。相反,微体系结构的发展非常迅速。
3.每个ISA中有个内在的接口(动态-静态接口 DSI,Dynamic-Static Interface)定义,区别哪些是在编译时静态完成的,哪些时在运行时动态完成的,如下图:

通常所有在编译时由软件和编译器静态完成的人物和优化,在DSI之上。相反,所有在运行是由硬件动态完成的任务以及优化,认为是在DSI之下。所有的体系结构的特性都在ISA中规定,因此都处于静态区域。处于DSI之上的软件和DSI之下的微体系结构的发展是相互独立的。
ISA 设计中的关键问题是DSI放置的位置,DSI可以将高级语言编写的应用程序与底层机器的实际硬件放置到不同的抽象层次。可以通过编译器优化DSI上的内容,或者在微体系结构中优化DSI下的内容。(例如精简指令集的DSI位置放的比复杂指令集CISC更低,希望更多的通过运行DSI上的编译器完成优化,减小硬件复杂度,从而获得更快的机器速度。)
一个缺点
ISA不断发展的过程中加入了许多新的特性,可以将以前的实现特征提升到体系结构的层次,将某些原始的微体系结构特征暴露给软件,有助于编译器的优化,从而减小硬件复杂度,DSI的位置降低。这些特征成为ISA的一部分,则未来的实现必须满足这部分特征规范。但是随着硬件的发展,这些陈旧的特征可能低效过时,从而不利于性能提升,因此体系结构和微体系结构必须严格分离。理想情况下ISA应只包含表达功能或者软件算法语义所必须的特征,而不管那些优化程序性能的所有特征应该归入实现还是归入微体系结构领域。
处理器性能法则
处理器性能公式

处理器性能是根据执行一段特殊代码所需要的时间来衡量的(时间/程序, Time/Program),又可分为三项
(1)指令数:特定程序需要执行的动态指令的数目;
(2)平均(在整个程序的执行范围内进行平均)执行每条指令需要耗费多少个始终周期,用CPI(Cycles Per Instruction)表示;
(3)机器的时钟周期,每个时钟周期需要的时间
由公式1.1,可减少任一项来提升性能,但上述不是相互独立的,性能的提升需要权衡和折中。书本第7页1.3.2节处理器性能优化中描述了一些例子。
性能评价方法
功能仿真器:模拟体系结构的机器,用于验证程序能否被正确执行。
性能仿真器:模拟微体系架构,测量执行一个程序所需要的时钟周期的数目。
性能仿真器可分为路径驱动和执行驱动。
指令集并行处理
指令集并行处理可认为多条指令并行执行。串行处理一次执行一条指令,下一条指令执行之前上一条指令必须完成。
流水线处理器可重叠执行多条指令,若每个周期都有一条新的指令进入流水线,虽然每条指令的处理时间与串行的相同,但是多条指令的重叠可以让平均CPI降低到接近1。
标量处理器每个时钟周期至多只能取出一条指令并进行发射,超标量处理器则可以在每个时钟周期取出多条指令进行发射。CPI 小于1或者ICPI大于1的处理器成为超标量处理器。
改写公式1.1如下:
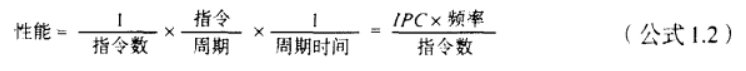
指令数由ISA、编译器和操作系统共同决定。ISA每条指令的完成工作量对指令总数由影响,编译器效率、程序执行过程中,应用程序对操作系统的功能调用将增加执行的指令总数。
平均IPC反应处理器达到的平均指令吞吐率。
减少流水线中每一段的逻辑门的级数、同时增加流水线的级数能提高时钟频率。为了获得很高的IPC,流水线必须设计的很宽,以便每一段中可以同时处理多条指令。流水线的加宽增加了硬件的复杂度,增加了流水线各段之间的信号传播延迟。因此在一个更宽的流水线中,为了维持相同的频率,流水线需要加深,这就需要在流水线究竟是要加宽还是要加深的选择中进行复杂的权衡。
并行处理器性能



指令集并行可以称为细粒度并行,粗粒度指程序段或者计算任务之间的并行。
几个名词
- 操作延迟(OL):将有一条指令产生结果后使用的机器时钟周期,即指令执行所需要的机器时钟周期
- 机器并行度(MP):机器支持的可以同时执行的最大指令数目
- 发射延迟(IL):发射两条连续的指令之间需要的机器时钟周期,发射指一条新的指令初始化后进行流水线
- 发射并行度(IP):每个时钟周期内可以发射的最大指令数
当OL = 1, MP = 4, IL = 1, IP = 1时的基准标量流水线处理器如下,4个过程表示取指、译码、执行和写回。

超流水处理器
比基准处理器有着更高的流水度,处理器的时钟周期比基准处理器短并定义为次时钟周期。一个基准处理器的时钟周期中有m个次时钟周期,OL = 1个时钟周期 = m个次时钟周期。IL = 1个次时钟周期。
即执行仍需要一个基准时钟周期并等于m个次时钟周期,但是执行时,处理器每过一个次时钟周期就发射一条新指令。IP = 1条指令/次时钟周期等于m条指令/时钟周期, MP= m * k,k为一个次时钟周期发射的指令数。
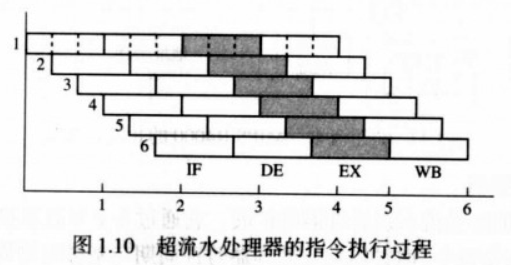
超标量处理器

超长指令字处理器
与超标量处理器的区别在于动态静态界面DSI的位置,超标量处理器中,运行时决定某n条指令发射到执行段,而超长指令字是在编译时进行的,编译器决定哪n条指令被同时发射到执行段,并将这n条指令作为一个超长指令字存放到程序存储器中。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号