
负载均衡
概述
负载均衡构建在原有网络结构之上,它提供了一种透明且廉价有效的方法扩展服务器和网络设备的带宽、加强网络数据处理能力、增加吞吐量、提高网络的可用性和灵活性。
分类
从负载均衡设备的角度来看,分为硬件负载均衡和软件负载均衡:
硬件负载均衡
硬件负载均衡解决方案是直接在服务器和外部网络间安装负载均衡设备,这种设备通常称之为负载均衡器,由于专门的设备完成专门的任务,独立于操作系统,整体性能得到大量提高,加上多样化的负载均衡策略,智能化的流量管理,可达到最佳的负载均衡需求。
- 硬件负载均衡:比如最常见的F5,还有Array等,这些负载均衡是商业的负载均衡器,性能比较好,毕竟他们的就是为了负载均衡而生的,背后也有非常成熟的团队,可以提供各种解决方案,但是价格比较昂贵,所以没有充足的理由,充足的软妹币是不会考虑的。
软件负载均衡
- 软件负载均衡:包括我们耳熟能详的Nginx,LVS,Tengine(阿里对Nginx进行的改造)等。优点就是成本比较低,但是也需要有比较专业的团队去维护,要自己去踩坑,去DIY。
负载均衡器有多种多样的形式,除了作为独立意义上的负载均衡器外,有些负载均衡器集成在交换设备中,置于服务器与Internet链接之间,有些则以两块网络适配器将这一功能集成到PC中,一块连接到Internet上,一块连接到后端服务器群的内部网络上。一般而言,硬件负载均衡在功能、性能上优于软件方式,不过成本昂贵。
从负载均衡的技术来看,分为服务端负载均衡和客户端负载均衡:
服务器负载均衡
服务器负载均衡就是我们平时说的负载均衡,是指在服务器上游做服务分发。
当我们访问一个服务,请求会先到另外一台服务器,然后这台服务器会把请求分发到提供这个服务的服务器,当然如果只有一台服务器,那好说,直接把请求给那一台服务器就可以了,但是如果有多台服务器呢?这时候,就会根据一定的算法选择一台服务器。
常用的方式有一下几种:
- DNS域名解析负载均衡;假设我们的域名指向了多个IP地址,当一个域名请求来时,DNS服务器机进行域名解析将域名转换为IP地址是,在1:N的映射转换中实现负载均衡。DNS服务器提供简单的负载均衡算法,但当其中某台服务器出现故障时,通知DNS服务器移除当前故障IP。
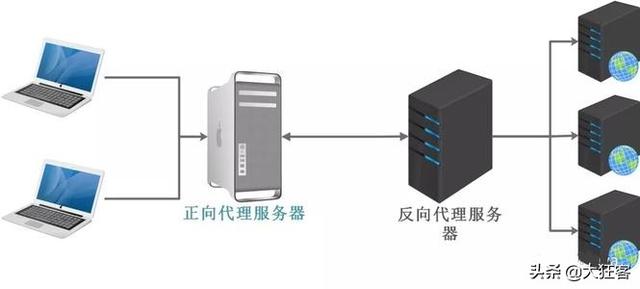
- 反向代理负载均衡;反向代理只值对服务器的代理,代理服务器接受请求,通过负载均衡算法,将请求转发给后端服务器,后端服务返回给代理服务器然后代理服务器返回到客户端。反向代理服务器的优点是隔离后端服务器和客户端,使用双网卡屏蔽真实服务器网络,安全性更好,相比较于DNS域名解决负载均衡,反向代理在故障处理方面更灵活,支持负载均衡算法的横向扩展。目前使用非常广泛。当然反向代理也需要考虑很多问题,比如单点故障,集群部署等。
- IP负载均衡;我们都知道反向代理工作到HTTP层,本身开销相对大一些,对性能有一定影响,LVS-NAT是一种卫浴传输层的负载均衡,它通过修改接受的数据包目标地址的方式实现负载均衡。Linux2.6.x以后版本内置了IPVS,专注用于实现IP负载均衡,故而在Linux上IP负载均衡使用非常广泛。LVS-DR工作在数据链路层,比LVS-NAT更霸道的时候它直接修改数据包的MAC地址。LVS-TUN——基于IP隧道的请求转发机制,将调度器收到的IP数据包进行封装,转交给服务器,然后服务器返回数据,通过调度器实现负载均衡。这种方式支持跨网段调度。总结一下,LVS-DR和LVS-TUN都适合响应和请求不对称的Web服务器,如何从它们中做出选择,取决于你的网络部署需要,因为LVS-TUN可具有跨地域性,有类似这种需求的,就应该选择LVS-TUN。
客户端负载均衡
客户端负载均衡:客户端服务均衡的概念貌似是有了服务治理才产生的,简单的来说,就是在一台服务器上维护着所有服务的ip,名称等信息,当我们在代码中访问一个服务,是通过一个组件访问的,这个组件会从那台服务器上取到所有提供这个服务的服务器的信息,然后通过一定的算法,选择一台服务器进行请求。
相比较服务器负载均衡而言,客户端负载均衡是一个非常小众的概念,但是面试在问道负载均衡相关知识的时候却会刻意了解候选人的知识广度。客户端负载均衡是在spring-cloud分布式框架组件Ribbon中定义的。我们在使用spring-cloud分布式框架时,同一个service大概率同时启动多个,当一个请求奔过来时,那么这多个service,Ribbon通过策略决定本次请求使用哪个service的方式就是客户端负载均衡。在spring-cloud分布式框架中客户端负载均衡对开发者是透明的,添加@LoadBalanced注解就可以了。客户端负载均衡和服务器负载均衡的核心差异在服务列表本身,客户端负载均衡服务列表在通过客户端维护,服务器负载均衡服务列表由中间服务单独维护。
通过对以上知识的理解,大家能够对负载均衡有的较为全面的认识,下来我再简单的和面试官聊一聊常见的负载均衡算法:
- 随机,通过随机选择服务进行执行,一般这种方式使用较少;
- 轮训,负载均衡默认实现方式,请求来之后排队处理;
- 加权轮训,通过对服务器性能的分型,给高配置,低负载的服务器分配更高的权重,均衡各个服务器的压力;
- 地址Hash,通过客户端请求的地址的HASH值取模映射进行服务器调度。
- 最小链接数;即使请求均衡了,压力不一定会均衡,最小连接数法就是根据服务器的情况,比如请求积压数等参数,将请求分配到当前压力最小的服务器上。
- 其他若干方式。
https://www.cnblogs.com/gucb/p/11237765.html
从负载均衡的算法来看,又分为 随机,轮询,哈希,最小压力,当然可能还会加上权重的概念,负载均衡的算法就是本文的重点了。
https://www.cnblogs.com/CodeBear/archive/2019/03/11/10508880.html
负载均衡算法
介绍
分类
选择一台当前最“悠闲”的服务器,如果A服务器有100个请求,B服务器有5个请求,而C服务器只有3个请求,那么毫无疑问会选择C服务器,这种负载均衡算法是比较科学的。但是遗憾的在当前的场景下无法模拟出来“原汁原味”的最小压力负载均衡算法的。
当然在实际的负载均衡下,可能会将多个负载均衡算法合在一起实现,比如先根据最小压力算法,当有几台服务器的压力一样小的时候,再根据权重取出一台服务器,如果权重也一样,再随机取一台,等等。
4、哈希
负载均衡算法中的哈希算法,就是根据某个值生成一个哈希值,然后对应到某台服务器上去,当然可以根据用户,也可以根据请求参数,或者根据其他,想怎么来就怎么来。如果根据用户,就比较巧妙的解决了负载均衡下Session共享的问题,用户小明走的永远是A服务器,用户小笨永远走的是B服务器。
那么如何用代码实现呢,这里又需要引出一个新的概念:哈希环。
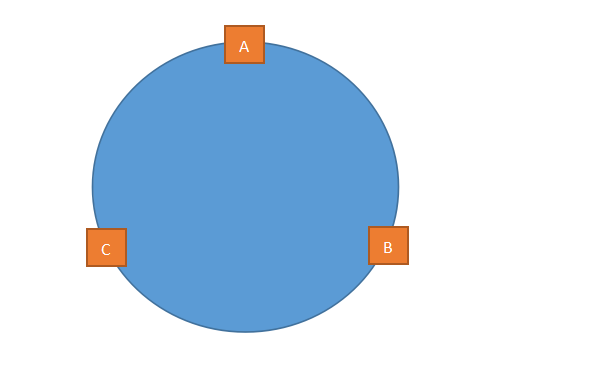
一个圆是由无数个点组成的,这是最简单的数学知识,相信大家都可以理解吧,哈希环也一样,哈希环也是有无数个“哈希点”构成的,当然并没有“哈希点”这样的说法,只是为了便于大家理解。
我们先计算出服务器的哈希值,比如根据IP,然后把这个哈希值放到环里,如上图所示。
来了一个请求,我们再根据某个值进行哈希,如果计算出来的哈希值落到了A和B的中间,那么按照顺时针算法,这个请求给B服务器。
理想很丰满,现实很孤单,可能三台服务器掌管的“区域”大小相差很大很大,或者干脆其中一台服务器坏了,会出现如下的情况:
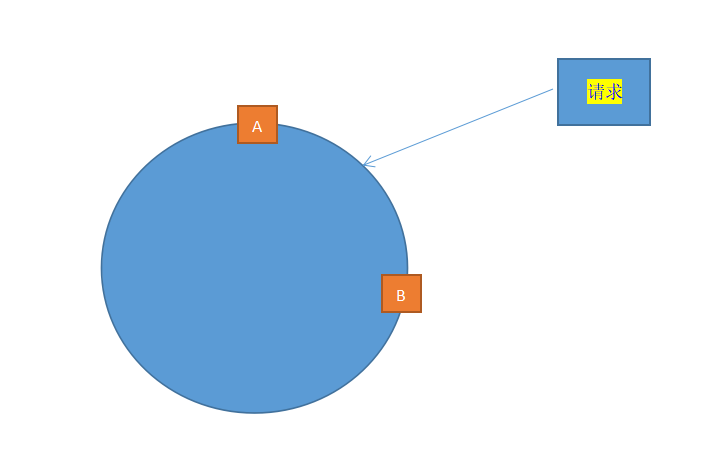
可以看出,A掌管的“区域”实在是太大,B可以说是“很悠闲,喝着咖啡,看着电影”,像这种情况,就叫“哈希倾斜”。
那么怎么避免这种情况呢?虚拟节点。
什么是虚拟节点呢,说白了,就是虚拟的节点...好像..没解释啊...还是上一张丑到爆炸的图吧:
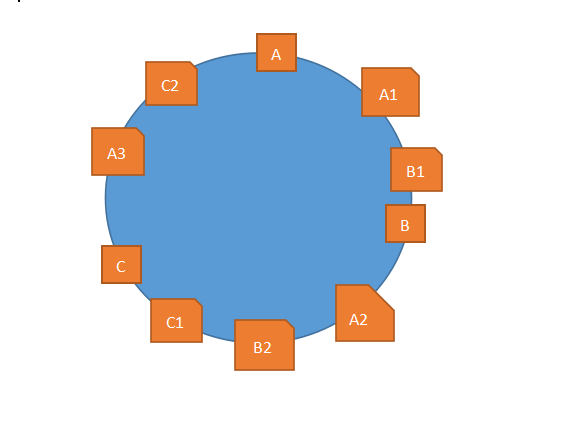
其中,正方形的是真实的节点,或者说真实的服务器,五边形的是虚拟节点,或者说是虚拟的服务器,当一个请求过来,落到了A1和B1之间,那么按照顺时针的规则,应该由B1服务器进行处理,但是B1服务器是虚拟的,它是从B服务器映射出来的,所以再交给B服务器进行处理。
要实现此种负载均衡算法,需要用到一个平时不怎么常用的Map:TreeMap,对TreeMap不了解的朋友可以先去了解下TreeMap,下面放出代码:
private static String go(String client) {
int nodeCount = 20;
TreeMap<Integer, String> treeMap = new TreeMap();
for (String s : new Servers().list) {
for (int i = 0; i < nodeCount; i++)
treeMap.put((s + "--服务器---" + i).hashCode(), s);
}
int clientHash = client.hashCode();
SortedMap<Integer, String> subMap = treeMap.tailMap(clientHash);
Integer firstHash;
if (subMap.size() > 0) {
firstHash = subMap.firstKey();
} else {
firstHash = treeMap.firstKey();
}
String s = treeMap.get(firstHash);
return s;
}
public static void main(String[] args) {
System.out.println(go("今天天气不错啊"));
System.out.println(go("192.168.5.258"));
System.out.println(go("0"));
System.out.println(go("-110000"));
System.out.println(go("风雨交加"));
}
运行结果:
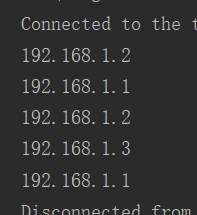
哈希负载均衡算法到这里就结束了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号