Python 爬虫学习(一)
前言:
又一个寒假到来了,一直对爬虫很感兴趣但在学校没时间学(大概是太懒了(╯_╰),趁着这个寒假来学习一下(ง •_•)ง。
文章目录
一、爬虫基础简介:
1、首先 什么是爬虫?
- 学术概念:爬虫就是通过编写程序模拟浏览器上网,让其去互联网上抓取数据的过程。
- 形象概念: 爬虫,即网络爬虫,大家可以理解为在网络上爬行的一直蜘蛛,互联网就比作一张大网,而爬虫便是在这张网上爬来爬去的蜘蛛咯,如果它遇到资源,那么它就会抓取下来。想抓取什么,这个由你来控制它。
2、哪些语言可以实现爬虫?
- PHP:可以实现爬虫。php被号称是全世界最优美的语言(当然是其自己号称的😂),但是php在实现爬虫中支持多线程和多进程方面做的不好。
- C、C++:可以实现爬虫。但是使用这种方式实现爬虫纯粹是是某些人(大佬们)能力的体现,却不是明智和合理的选择。
- Java:可以实现爬虫。java可以非常好的处理和实现爬虫,是唯一可以与python并驾齐驱且是python的头号劲敌。但是java实现爬虫代码较为臃肿,重构成本较大。
- Python:可以实现爬虫。python实现和处理爬虫语法简单,代码优美,支持的模块繁多,学习成本低,具有非常强大的框架且一语难以言表的好!没有但是!
因此本次的爬虫学习是基于python实现的(并不是Java学的不好 →_→)。
3、爬虫的分类:
- 通用爬虫:通用爬虫是搜索引擎(Baidu、Google等)“抓取系统”的重要组成部分。主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份。 简单来讲就是尽可能的;把互联网上的所有的网页下载下来,放到本地服务器里形成备分,在对这些网页做相关处理(提取关键字、去掉广告),最后提供一个用户检索接口。
- 聚焦爬虫:聚焦爬虫是根据指定的需求抓取网络上指定的数据。例如:获取豆瓣上电影的名称和影评,而不是获取整张页面中所有的数据值。
- 增量式爬虫:增量式是用来检测网站数据更新的情况,且可以将网站更新的数据进行爬取。
二、requests模块:
在python实现的网络爬虫中,用于网络请求发送的模块有两种,第一种为urllib模块,第二种为requests模块。urllib模块是一种比较古老的模块,在使用的过程中较为繁琐和不便。当requests模块出现后,就快速的代替了urllib模块,因此推荐使用requests模块。
1、什么是requests?
- requests模块是python中原生的基于网络请求的模块,其主要作用是用来模拟浏览器发起请求。功能强大,用法简洁高效。在爬虫领域中占据着半壁江山的地位。
2、如何使用requests模块:
1、环境安装:
pip install requests
2、使用流程:
-
指定url
-
基于requests模块发起请求
-
获取响应对象中的数据值
-
持久化存储
3、第一个爬虫程序:
需求:爬取网易云首页的页面数据
#导包
import requests
#指定url
url = 'https://music.163.com/'
#发起请求:发起 get请求,该方法会返回一个响应对象。
response = requests.get(url=url)
#获取响应数据:通过调用响应对象的text属性,返回响应对象中存储的字符串形式的响应数据(页面源码数据)
page_text = response.text
#持久化存储
with open('./wangyiyun.html','w',encoding='utf-8') as fp:
fp.write(page_text)
print('爬取数据完成!')
运行结果:
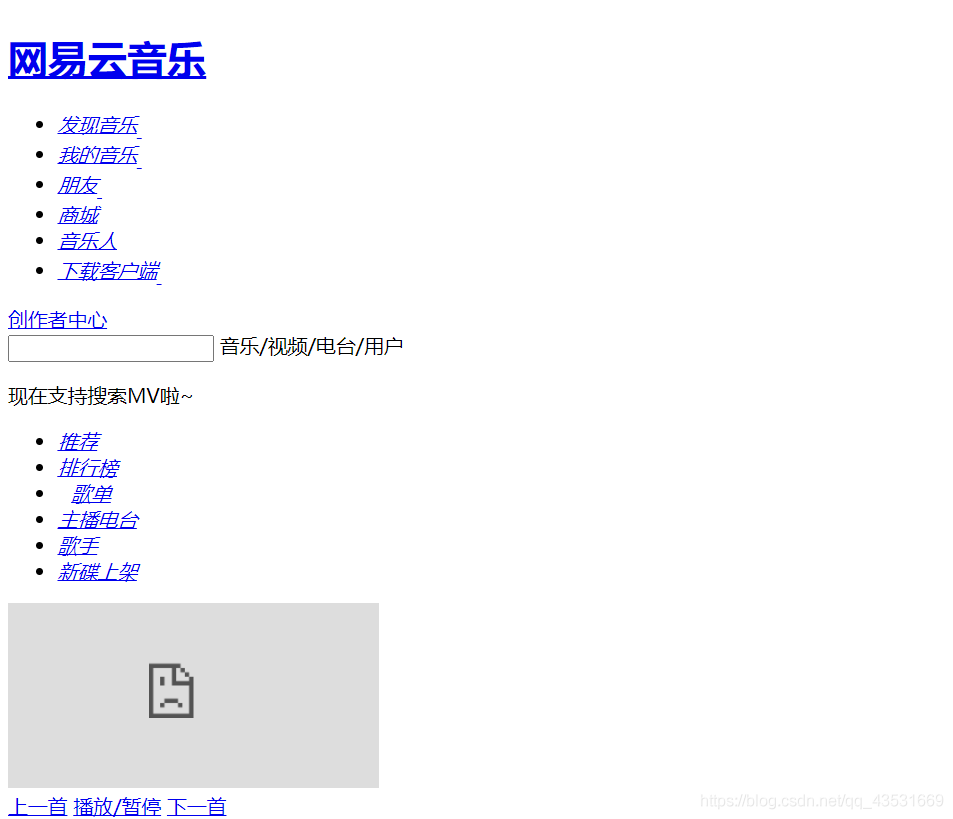
虽然和原网页不一样(没有样式),但是数据爬取成功了。
4、实例练习:
实例一:
基于requests模块的get请求:
需求:爬取搜狗指定词条对应的搜索结果页面(简易网页采集器)
反爬机制:
- User-Agent:请求载体的身份标识,使用浏览器发起的请求,请求载体的身份标识为浏览器,使用爬虫程序发起的请求,请求载体为爬虫程序。
- UA检测:相关的门户网站通过检测请求该网站的载体身份来辨别该请求是否为爬虫程序,因为正常用户对网站发起的请求的载体一定是基于某一款浏览器,如果网站检测到某一请求载体身份标识不是基于浏览器的,则让其请求失败。因此,UA检测是遇到的第二种反爬机制,第一种是robots协议。
如何绕过:
- 可以通过设置爬虫请求的User-Agent来破解UA检测这种反爬机制,具体实现见下面代码:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import requests
if __name__ == '__main__':
# UA伪装:将对应的User-Agent封装到一个字典中
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'
}
url = 'https://www.sogou.com/web'
kw = input('输入关键词:')
param = {
'query': kw
}
response = requests.get(url=url, params=param, headers=headers)
page_text = response.text
filename = kw + '.html'
with open(filename, 'w', encoding='utf-8') as fp:
fp.write(page_text)
print(filename, '保存成功!')
运行:
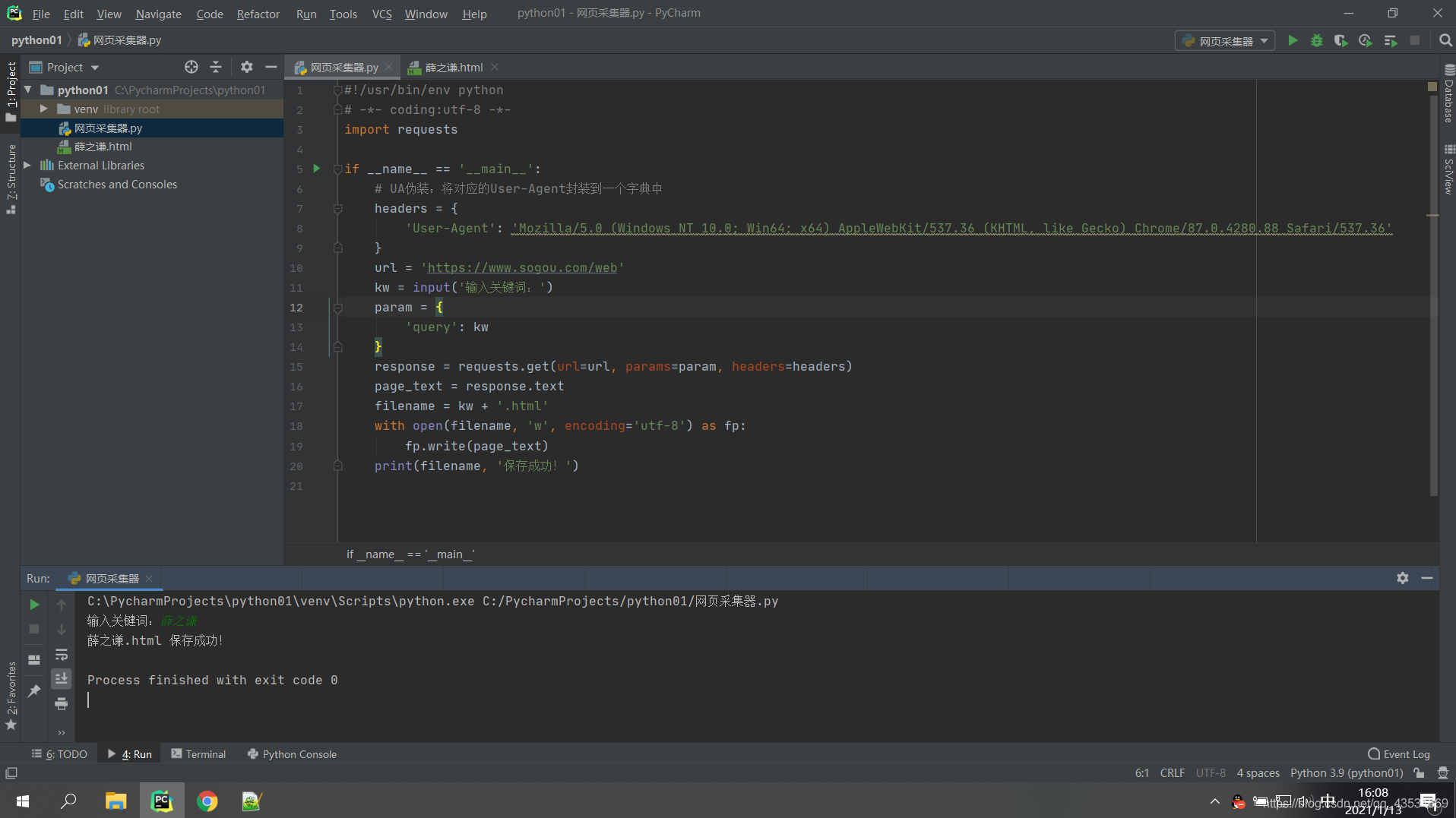
打开保存的数据:
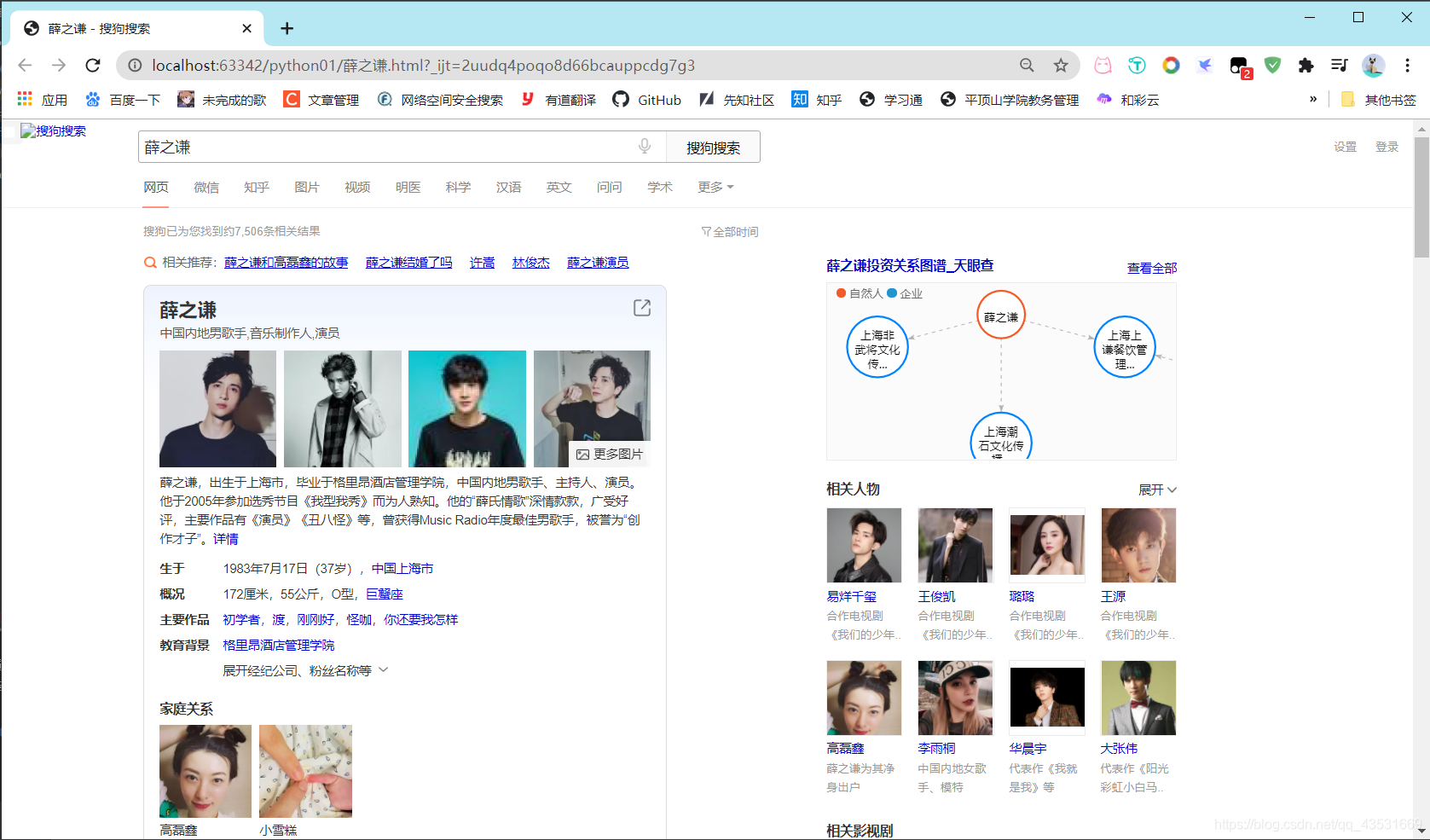
爬取成功( ̄︶ ̄)↗
如果没有设置UA数据,则会得到这样的页面:

示例二:
基于requests模块的post请求
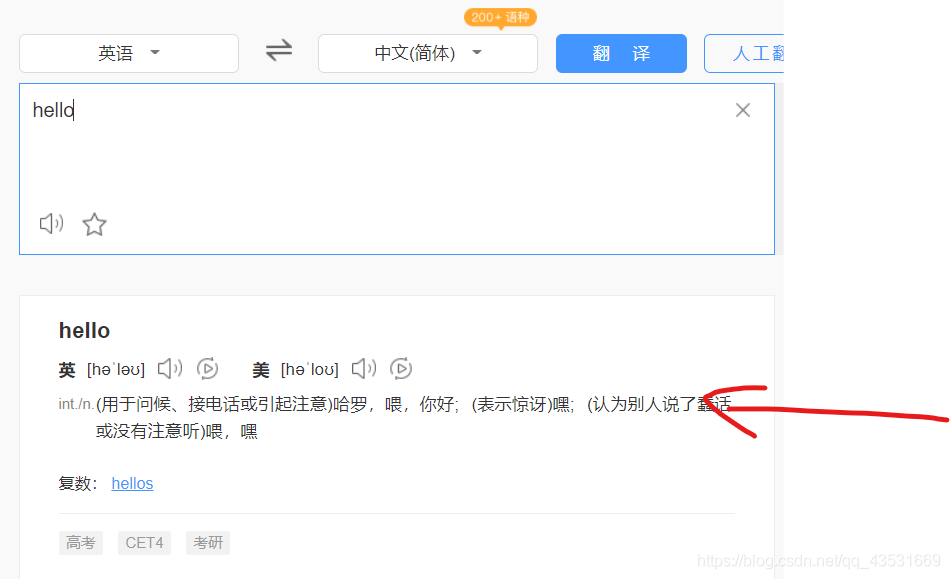
需求:破解百度翻译,即获取箭头处的数据。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import requests
import json
if __name__ == "__main__":
# 1.指定url
post_url = 'https://fanyi.baidu.com/sug'
# 2.UA伪装
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'
}
# 3.post请求参数处理
word = input('enter a word:')
data = {
'kw': word
}
# 4.请求发送
response = requests.post(url=post_url, data=data, headers=headers)
# 5.获取响应数据:json()方法返回的是obj(如果确认响应数据是json类型的,才可以使用json())
dic_obj = response.json()
# 持久化存储
fileName = word + '.json'
fp = open(fileName, 'w', encoding='utf-8')
json.dump(dic_obj, fp=fp, ensure_ascii=False)//存在中文,需要禁用ascii码
print('数据爬取完成!')
运行结果:


爬取成功!
示例三:
基于requests模块ajax的get请求
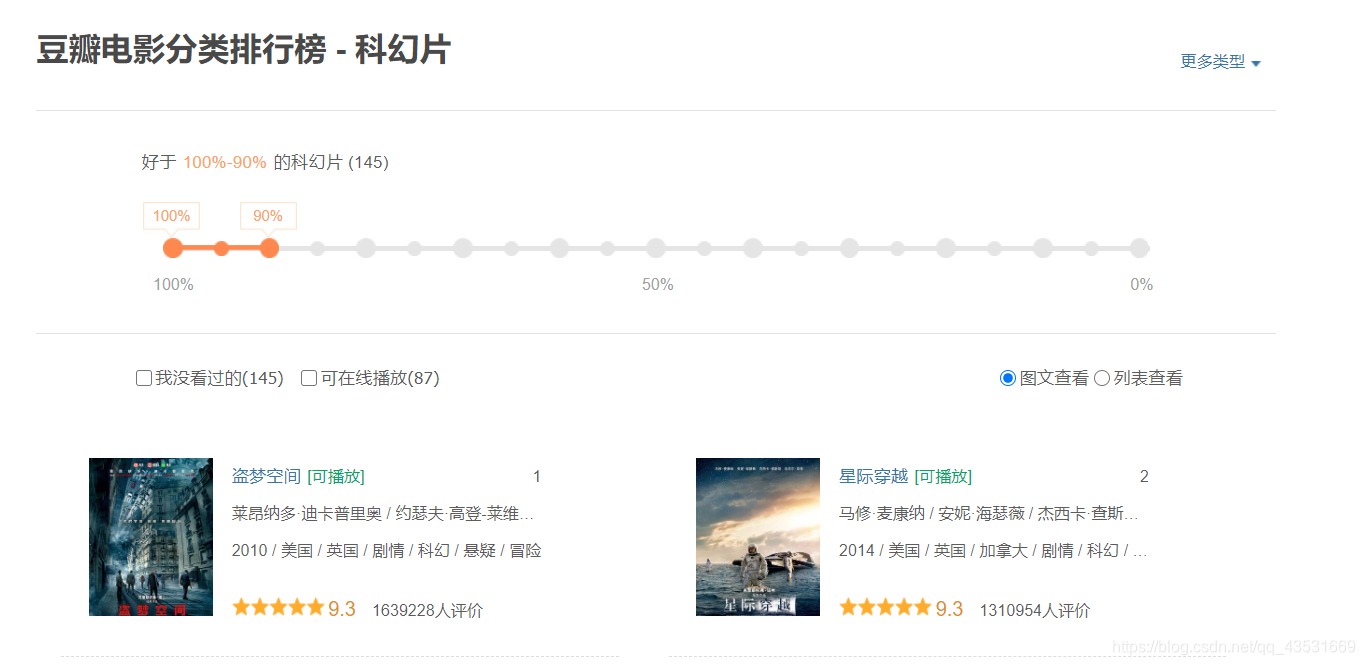
需求:爬取豆瓣电影某分类排行榜中的电影详情数据。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import requests
import json
if __name__ == '__main__':
url = 'https://movie.douban.com/j/chart/top_list'
param = {
'type': '17',
'interval_id': '100:90',
'action': '',
'start': '0', # 从库中的第几部电影去取
'limit': '20', # 一次取出的个数
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'
}
response = requests.get(url=url, params=param, headers=headers)
list_data = response.json()
fp = open('./douban.json', 'w', encoding='utf-8')
json.dump(list_data, fp=fp, ensure_ascii=False)
print('数据爬取完成!')
运行结果;

 可以看到爬取的数据是正确的。
可以看到爬取的数据是正确的。
示例四:
基于requests模块ajax的post请求
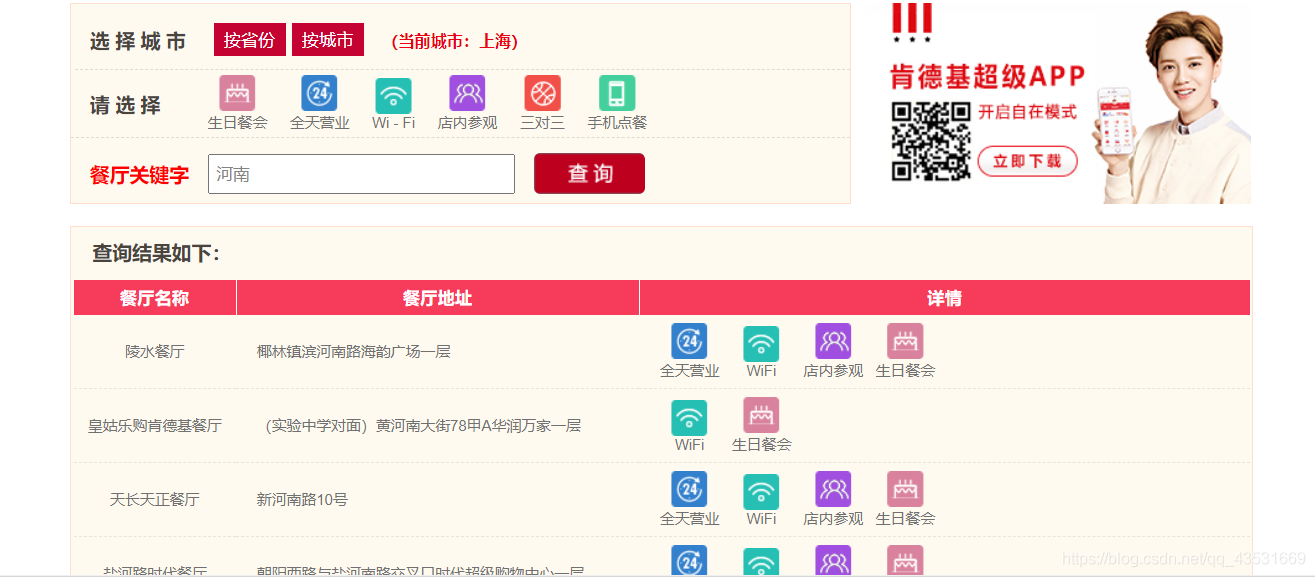
需求:爬取肯德基餐厅查询 http://www.kfc.com.cn/kfccda/index.aspx 中指定地点的餐厅数据。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import requests
if __name__ == "__main__":
url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword'
kw = input('输入地址:')
param = {
'cname': '',
'pid': '',
'keyword': kw,
'pageIndex': '1',
'pageSize': '10'
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'
}
response = requests.get(url=url, params=param, headers=headers)
page_text = response.text
filename = kw + '.html'
with open(filename, 'w', encoding='utf-8') as fp:
fp.write(page_text)
print('数据爬取完成!')
运行结果:


综合练习:
需求:爬取 国家药品监督管理局基于化妆品生产许可信息数据 http://scxk.nmpa.gov.cn:81/xk/:
网站首页:

详细信息即要爬取得的数据:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import requests
import json
if __name__ == '__main__':
id_list = [] # 储存企业id
all_date_list = [] # 储存详细信息
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'
}
url = 'http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsList'
for page in range(1, 6):
page = str(page)
data = {
'on': 'true',
'page': page,
'pageSize': '15',
'productName': '',
'conditionType': '1',
'applyname': '',
'applysn': ''
}
json_ids = requests.post(url=url, data=data, headers=headers).json()
for dic in json_ids['list']:
id_list.append(dic['ID'])
url = 'http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsById'
for id in id_list:
data = {
'id': id
}
detail_json = requests.post(url=url, headers=headers, data=data).json()
all_date_list.append(detail_json)
fp = open('./allData.json', 'w', encoding='utf-8')
json.dump(all_date_list, fp=fp, ensure_ascii=False)
print("数据爬取完成!")
运行结果:


爬取成功!
🆗,第一篇暂时先练习这么多了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号