爬虫大作业
1.主题:
爬取传智播客的技术论坛信息,这里我主要对标题信息进行了爬取,爬取信息之后通过jieba分词生成词云并且进行分析;
2.爬取过程:
第一步:
首先打开传智播客,进入Java技术信息交流版块
第一页:http://bbs.itheima.com/forum-231-1.html
因此爬取java技术信息交流版块标题的所有链接可写为:
for i in range(2,10): pages = i; nexturl = 'http://bbs.itheima.com/forum-231-%s.html' % (pages) reslist = requests.get(nexturl) reslist.encoding = 'utf-8' soup_list = BeautifulSoup(reslist.text, 'html.parser') for news in soup_list.find_all('a',class_='s xst'): print(news.text) f = open('wuwencheng.txt', 'a', encoding='utf-8') f.write(news.text) f.close()
第二步:
获取java技术信息交流版块标题:f12打开开发者工具,通过审查,不难发现,我要找的内容在tbody的类下的a标签里
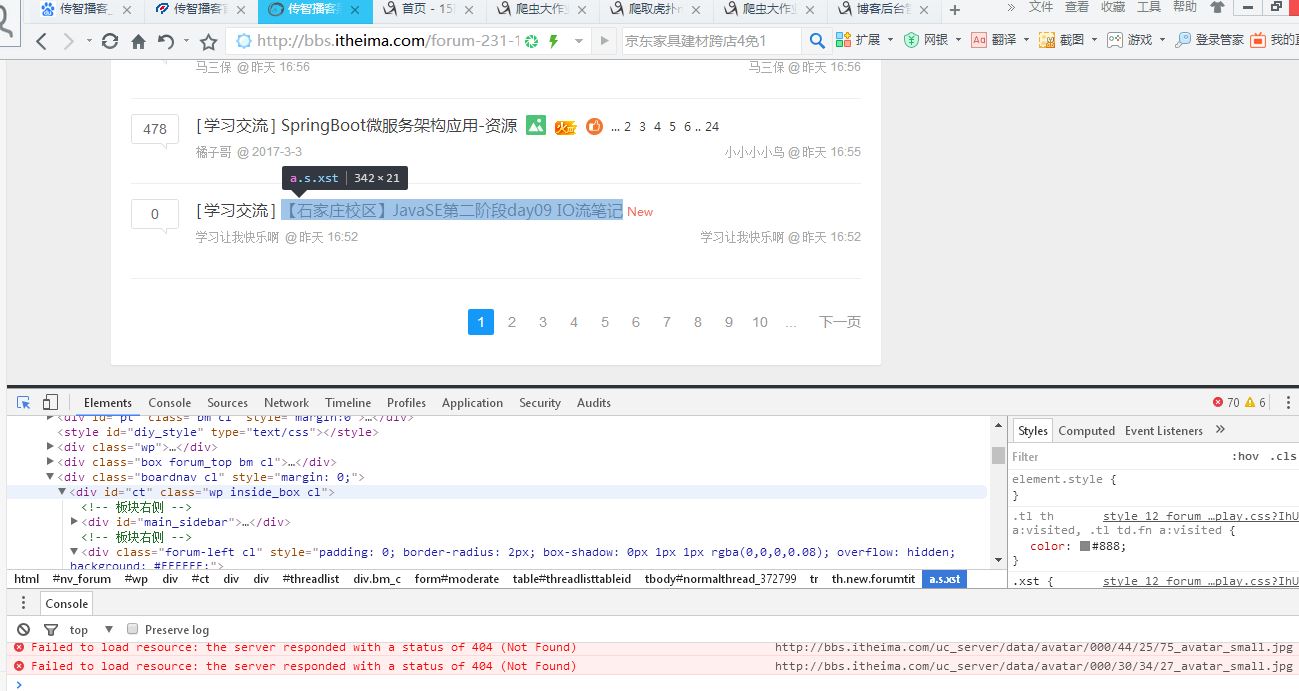
3.把数据保存成文本:
保存成文本代码:
for news in soup_list.find_all('a',class_='s xst'): print(news.text) f = open('wuwencheng.txt', 'a', encoding='utf-8') f.write(news.text) f.close()

4.生成词云:
def changeTitleToDict(): f = open("wuwencheng.txt", "r", encoding='utf-8') str = f.read() stringList = list(jieba.cut(str)) delWord = {"+", "/", "(", ")", "【", "】", " ", ";", "!", "、"} stringSet = set(stringList) - delWord title_dict = {} for i in stringSet: title_dict[i] = stringList.count(i) print(title_dict) return title_dict # 生成词云 from PIL import Image,ImageSequence import numpy as np import matplotlib.pyplot as plt from wordcloud import WordCloud,ImageColorGenerator # 获取上面保存的字典 title_dict = changeTitleToDict() graph = np.array(title_dict) font = r'C:\Windows\Fonts\simhei.ttf' # backgroud_Image代表自定义显示图片,这里我使用默认的 # backgroud_Image = plt.imread("C:\\Users\\jie\\Desktop\\1.jpg") # wc = WordCloud(background_color='white',max_words=500,font_path=font, mask=backgroud_Image) wc = WordCloud(background_color='white',max_words=500,font_path=font) wc.generate_from_frequencies(title_dict) plt.imshow(wc) plt.axis("off") plt.show()
生成的词云图片:

5.遇到的问题:
本来我是这样生成词典的,但是不行
def getWord(): lyric = '' f = open('wuwencheng.txt', 'r', encoding='utf-8') # 将文档里面的数据进行单个读取,便于生成词云 for i in f: lyric += f.read() print(i) # 进行分析 result = jieba.analyse.textrank(lyric, topK=2, withWeight=True) keywords = dict() for i in result: keywords[i[0]] = i[1] print(keywords)
后来,我改了另一种写法,就可以了:
def changeTitleToDict(): f = open("wuwencheng.txt", "r", encoding='utf-8') str = f.read() stringList = list(jieba.cut(str)) delWord = {"+", "/", "(", ")", "【", "】", " ", ";", "!", "、"} stringSet = set(stringList) - delWord title_dict = {} for i in stringSet: title_dict[i] = stringList.count(i) print(title_dict) return title_dict
安装词云出现的问题:
安装wordcloud库时候回发生报错
解决方法是:
- 安装提示报错去官网下载vc++的工具,但是安装的内存太大只是几个G
- 去https://www.lfd.uci.edu/~gohlke/pythonlibs/#wordcloud下载whl文件,选取对应python的版本号和系统位数
6.全部代码:
import requests import jieba.analyse import jieba from bs4 import BeautifulSoup url="http://bbs.itheima.com/forum-231-1.html" def getcontent(url): reslist=requests.get(url) reslist.encoding = 'utf-8' soup_list = BeautifulSoup(reslist.text, 'html.parser') # print(soup_list.select('table .s xst')) for news in soup_list.find_all('a',class_='s xst'): # print(news.select('tbody')[0].text)wuwencheng # a=news.get('a').text print(news.text) f = open('wuwencheng.txt', 'a', encoding='utf-8') f.write(news.text+' ') f.close() for i in range(2,10): pages = i; nexturl = 'http://bbs.itheima.com/forum-231-%s.html' % (pages) reslist = requests.get(nexturl) reslist.encoding = 'utf-8' soup_list = BeautifulSoup(reslist.text, 'html.parser') for news in soup_list.find_all('a',class_='s xst'): print(news.text) f = open('wuwencheng.txt', 'a', encoding='utf-8') f.write(news.text) f.close() def changeTitleToDict(): f = open("wuwencheng.txt", "r", encoding='utf-8') str = f.read() stringList = list(jieba.cut(str)) delWord = {"+", "/", "(", ")", "【", "】", " ", ";", "!", "、"} stringSet = set(stringList) - delWord title_dict = {} for i in stringSet: title_dict[i] = stringList.count(i) print(title_dict) return title_dict # 生成词云 from PIL import Image,ImageSequence import numpy as np import matplotlib.pyplot as plt from wordcloud import WordCloud,ImageColorGenerator # 获取上面保存的字典 title_dict = changeTitleToDict() graph = np.array(title_dict) font = r'C:\Windows\Fonts\simhei.ttf' # backgroud_Image代表自定义显示图片,这里我使用默认的 # backgroud_Image = plt.imread("C:\\Users\\jie\\Desktop\\1.jpg") # wc = WordCloud(background_color='white',max_words=500,font_path=font, mask=backgroud_Image) wc = WordCloud(background_color='white',max_words=500,font_path=font) wc.generate_from_frequencies(title_dict) plt.imshow(wc) plt.axis("off") plt.show()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号