Hive学习(四) 开窗函数
1、row_number、rank、dense_rank
ROW_NUMBER() –从1开始,按照顺序,生成分组内记录的序列
RANK() 生成数据项在分组中的排名,排名相等会在名次中留下空位
DENSE_RANK() 生成数据项在分组中的排名,排名相等会在名次中不会留下空位
row_number: 按顺序编号,不留空位
rank: 按顺序编号,相同的值编相同号,留空位
dense_rank: 按顺序编号,相同的值编相同的号,不留空位
2、sum、avg、min、max
3、ntile
NTILE(n),用于将分组数据按照顺序切分成n片,返回当前切片值
NTILE不支持ROWS BETWEEN,比如 NTILE(2) OVER(PARTITION BY cookieid ORDER BY createtime ROWS BETWEEN 3 PRECEDING AND CURRENT ROW)
4、lag、lead、first_value、last_value
LAG(col,n,DEFAULT) 用于统计窗口内往上第n行值
LEAD(col,n,DEFAULT) 用于统计窗口内往下第n行值
取分组内排序后,截止到当前行,最后一个值
5、cume_dist、percent_rank
create table if not exists imei_info ( imei string, create_time string, pv bigint ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' COLLECTION ITEMS TERMINATED BY ',' MAP KEYS TERMINATED BY ':';
select * from imei_info; OK cookie1 2015/4/10 1 cookie1 2015/4/11 5 cookie1 2015/4/12 7 cookie1 2015/4/13 7 cookie1 2015/4/14 2 cookie1 2015/4/15 2 cookie1 2015/4/16 4 cookie2 2015/4/10 2 cookie2 2015/4/11 3 cookie2 2015/4/12 5 cookie2 2015/4/13 6 cookie2 2015/4/14 3 cookie2 2015/4/15 9 cookie2 2015/4/16 7
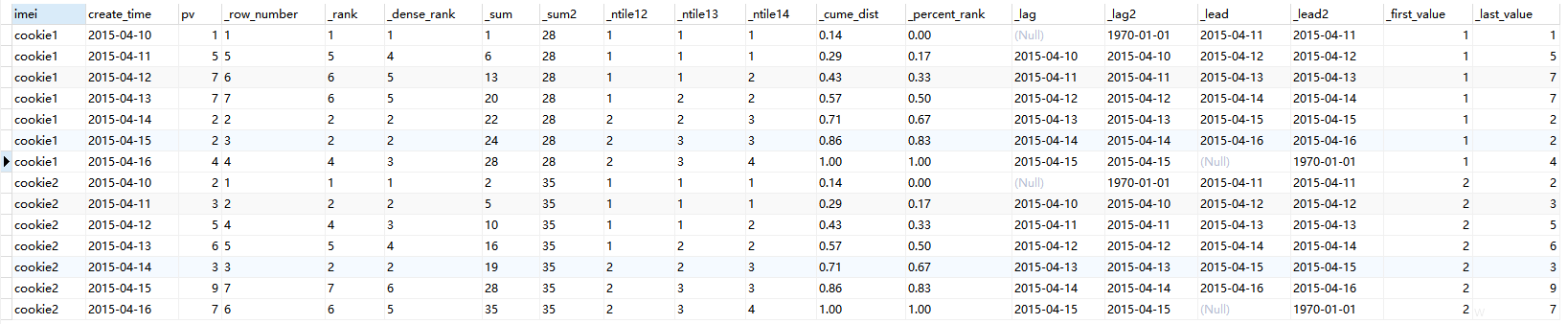
select imei ,create_time ,pv ,row_number() over(partition by imei order by pv) as _row_number -- 分组排序 ,rank() over(partition by imei order by pv) as _rank -- 分组排序(排名相等跳过) ,dense_rank() over(partition by imei order by pv) as _dense_rank -- 分组排序(排名相等不跳过) ,sum(pv) over(partition by imei order by create_time) as _sum -- 分组求和 ,sum(pv) over(partition by imei) as _sum2 -- 分组求和(没有order by) ,ntile(2) over(partition by imei order by create_time) as _ntile12 -- 分组内将数据分成2片 ,ntile(3) over(partition by imei order by create_time) as _ntile13 -- 分组内将数据分成3片 ,ntile(4) over(partition by imei order by create_time) as _ntile14 -- 分组内将数据分成4片 ,round(cume_dist() over(partition by imei order by create_time),2) as _cume_dist -- 分组行数占比(小于等于当前值的行数/分组内总行数) ,round(percent_rank() over(partition by imei order by create_time),2) as _percent_rank -- 分组行数占比2(分组内当前行的RANK值-1/分组内总行数-1) ,lag(create_time,1) over(partition by imei order by create_time) as _lag -- 统计窗口内往上第n=1行值 ,lag(create_time,1,'1970-01-01') over(partition by imei order by create_time) as _lag2 -- 统计窗口内往上第n=1行值(为null时取默认值-1970-01-01) ,lead(create_time,1) over(partition by imei order by create_time) as _lead -- 统计窗口内往下第n=1行值 ,lead(create_time,1,'1970-01-01') over(partition by imei order by create_time) as _lead2 -- 统计窗口内往下第n=1行值(为null时取默认值-1970-01-01) ,first_value(pv) over(partition by imei order by create_time) as _first_value -- 分组内排序后,截止到当前行,第一个值 ,last_value(pv) over(partition by imei order by create_time) as _last_value -- 分组内排序后,截止到当前行,最后一个值 from imei_info;
6、GROUPING SETS、GROUPING__ID、CUBE、ROLLUP
这几个分析函数通常用于OLAP中,不能累加,而且需要根据不同维度上钻和下钻的指标统计,比如,分小时、天、月的UV数
GROUPING SETS和GROUPING__ID
在一个GROUP BY查询中,根据不同的维度组合进行聚合,等价于将不同维度的GROUP BY结果集进行UNION ALL
GROUPING__ID,表示结果属于哪一个分组集合。
2015-03,2015-03-10,cookie1 2015-03,2015-03-10,cookie5 2015-03,2015-03-12,cookie7 2015-04,2015-04-12,cookie3 2015-04,2015-04-13,cookie2 2015-04,2015-04-13,cookie4 2015-04,2015-04-16,cookie4 2015-03,2015-03-10,cookie2 2015-03,2015-03-10,cookie3 2015-04,2015-04-12,cookie5 2015-04,2015-04-13,cookie6 2015-04,2015-04-15,cookie3 2015-04,2015-04-15,cookie2 2015-04,2015-04-16,cookie1
create table cookie5(month string, day string, cookieid string) row format delimited fields terminated by ',';
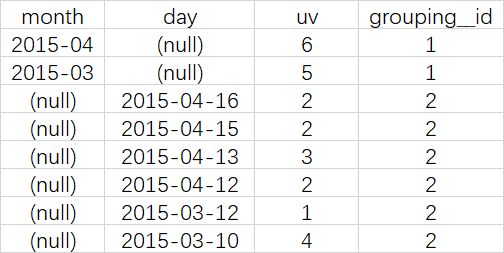
select month, day, count(distinct cookieid) as uv, GROUPING__ID from cookie5 group by month,day grouping sets (month,day) order by GROUPING__ID;
等价于
SELECT month,NULL,COUNT(DISTINCT cookieid) AS uv,1 AS GROUPING__ID FROM cookie5 GROUP BY month UNION ALL SELECT NULL,day,COUNT(DISTINCT cookieid) AS uv,2 AS GROUPING__ID FROM cookie5 GROUP BY day
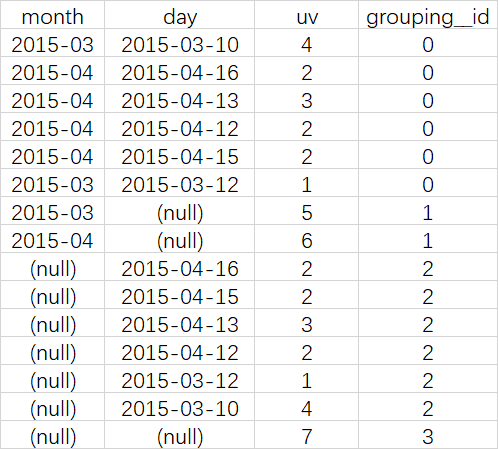
CUBE
根据GROUP BY的维度的所有组合进行聚合
SELECT month, day,
COUNT(DISTINCT cookieid) AS uv,
GROUPING__ID
FROM cookie5
GROUP BY month,day
WITH CUBE
ORDER BY GROUPING__ID;
等价于
SELECT NULL,NULL,COUNT(DISTINCT cookieid) AS uv,0 AS GROUPING__ID FROM cookie5 UNION ALL SELECT month,NULL,COUNT(DISTINCT cookieid) AS uv,1 AS GROUPING__ID FROM cookie5 GROUP BY month UNION ALL SELECT NULL,day,COUNT(DISTINCT cookieid) AS uv,2 AS GROUPING__ID FROM cookie5 GROUP BY day UNION ALL SELECT month,day,COUNT(DISTINCT cookieid) AS uv,3 AS GROUPING__ID FROM cookie5 GROUP BY month,day
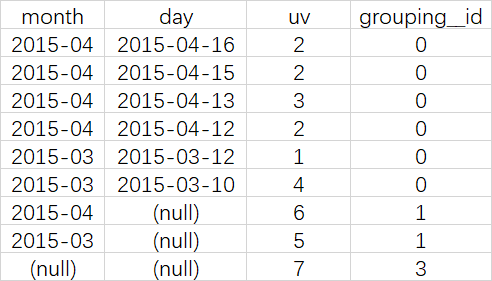
ROLLUP
是CUBE的子集,以最左侧的维度为主,从该维度进行层级聚合
SELECT month, day, COUNT(DISTINCT cookieid) AS uv, GROUPING__ID
FROM cookie5
GROUP BY month,day WITH ROLLUP ORDER BY GROUPING__ID;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号