CentOS 7 + Hadoop3.2 搭建集群
软件环境: VMware:VMware® Workstation 15 Pro 永久许可证:ZC10K-8EF57-084QZ-VXYXE-ZF2XF
CentOS7:CentOS-7-x86_64-DVD-1810.iso
JDK:jdk-8u211-linux-x64.tar.gz
Hadoop:hadoop-3.1.2.tar.gz
准备工作:
一、配置虚拟机网络(VMware-编辑-虚拟网络编辑器-VMnet8 设置子网ip、网关ip)
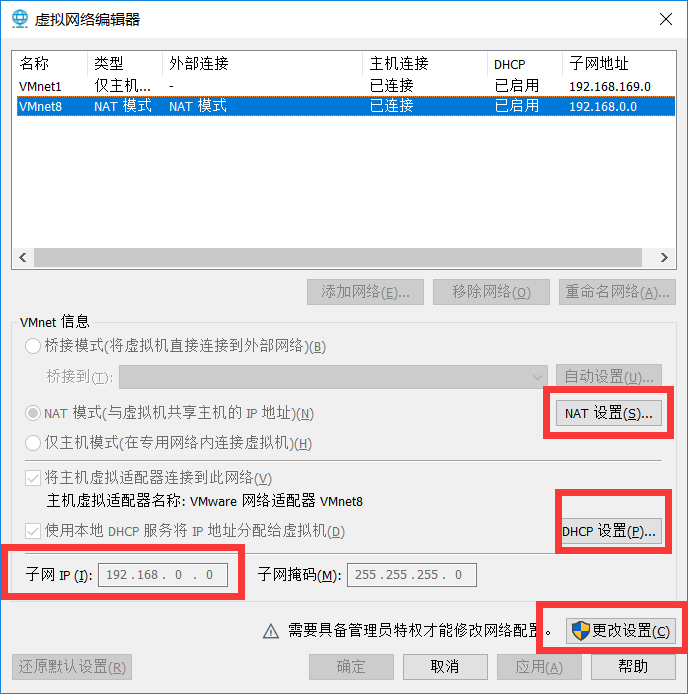
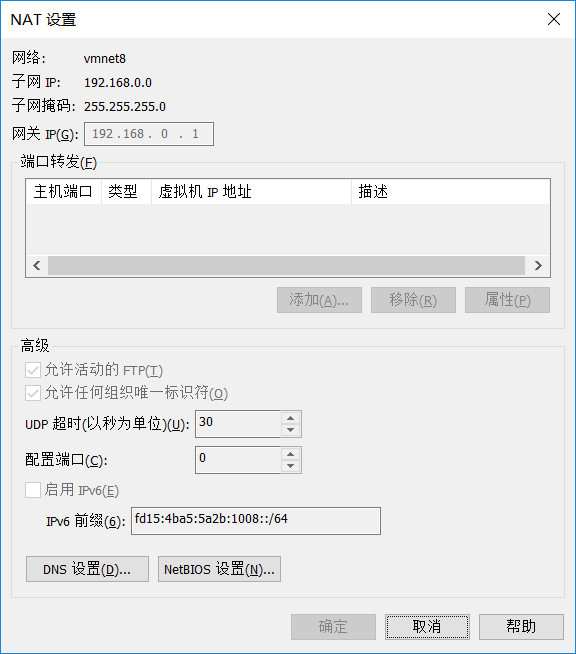
二、配置Linux网络(安装linux时使用默认设置即可):
命令: vi /etc/sysconfig/network-scripts/ifcfg-ens33 不一定是 ifcfg-ens33
TYPE="Ethernet" PROXY_METHOD="none" BROWSER_ONLY="no" BOOTPROTO="dhcp" DEFROUTE="yes" IPV4_FAILURE_FATAL="no" IPV6INIT="yes" IPV6_AUTOCONF="yes" IPV6_DEFROUTE="yes" IPV6_FAILURE_FATAL="no" IPV6_ADDR_GEN_MODE="stable-privacy" NAME="ens33" UUID="383fd573-d981-4554-8e53-f07a98904a12" DEVICE="ens33" ONBOOT="yes"
命令: service network restart
三、安装 lrzsz lrzsz是一款在linux里可代替ftp上传和下载的程序。lrzsz是一个unix通信套件提供的X,Y,和ZModem文件传输协议。
命令: yum install lrzsz
关闭防火墙
查看防火墙状态 : sudo firewall-cmd --state
关闭防火墙: sudo systemctl stop firewalld.service
禁止开机时防火墙自启: sudo systemctl disable firewalld.service
安装jdk(节点node01安装,克隆虚拟机后就不需要再安装)
下载解压
tar -zxvf jdk-8u161-linux-x64.tar.gz -C ~/home/java
进入 bin 目录下 ./java -version 看是否成功安装
配置环境变量PATH
vi /etc/profile
在最末尾处添加两行
export JAVA_HOME=/root/jdk1.8/jdk1.8.0_201 export PATH=$PATH:$JAVA_HOME/bin
使其生效: source /etc/profile ,然后输入 java -version 看到能够使用
四、克隆2个虚拟机,克隆时选择完整克隆
五、分别修改机器名和hosts文件
命令: vi /etc/hostname 修改机器名
命令: vi /etc/hosts 修改hosts

六、3台虚拟机设置ssh无密码登录
[root@node01 .ssh]# ssh-keygen -t dsa -P ''
[root@node01 .ssh]# cp id_dsa.pub authorized_keys
[root@node01 .ssh]# chmod 600 authorized_keys
[root@node01 .ssh]# scp authorized_keys node02:/root/.ssh/authorized_keys
[root@node01 .ssh]# scp authorized_keys node03:/root/.ssh/authorized_keys
安装Hadoop 在node01安装
解压安装包: tar -zxvf hadoop-3.2.0-src.tar.gz -C /home/hadoop
一、配置Hadoop环境变量
编辑: vi /etc/profile
export HADOOP_HOME=/root/hadoop
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
使更改生效 source /etc/profile
配置文件目录: /root/hadoop/etc/hadoop 需要修改的配置文件:hadoop-env.sh,core-site.xml, hdfs-site.xml ,(配置mapreduce)yarn-site.xml,mapred-site.xml ,workers
二、配置 hadoop-env.sh vi hadoop-env.sh
配置jdk的home路径
export JAVA_HOME=/root/jdk1.8/jdk1.8.0_201 export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root export HADOOP_PID_DIR=/root/hadoop/data/pids export HADOOP_LOG_DIR=/root/hadoop/data/logs
三、配置 core-site.xml vi core-site.xml
核心配置文件,例如HDFS、MapReduce和YARN查用的I/O设置
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.52.128:8888</value>
</property>
<property>
<!--HDFS的存储目录--> <name>hadoop.tmp.dir</name> <value>/root/hadoop/tmp</value> </property>
四、配置 hdfs-site.xml vi hdfs-site.xml
分布式文件系统的核心配置 决定了数据存放在哪个路径,数据的副本,数据的block块大小等等
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/root/hadoop/data/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/root/hadoop/data/data</value>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>node101:50070</value>
</property>
五、配置 mapred-site.xml vi mapred-site.xml
关于mapreduce运行的一些参数
<property>
<name>mapred.job.tracker</name>
<value>node101:9001</value>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>/root/hadoop-3.1.2/share/hadoop/mapreduce/*, /root/hadoop-3.1.2/share/hadoop/mapreduce/lib/*</value>
</property>
六、配置 yarn-site.xml vi yarn-site.xml
定义我们的yarn集群
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node01</value>
</property>
七、配置workers vi workers
把所有从节点的主机名写到这儿就可以,这是告诉hadoop进程哪些机器是从节点 每行写一个
node02
node03
将文件分发到其他节点
scp -r hadoop node02:/root scp -r hadoop node03:/root
启动Hadoop
一、初始化 hadoop namenode -format
二、启动
start-dfs.sh start-yarn.sh
然后输入 jps 查看已成功启动的进程
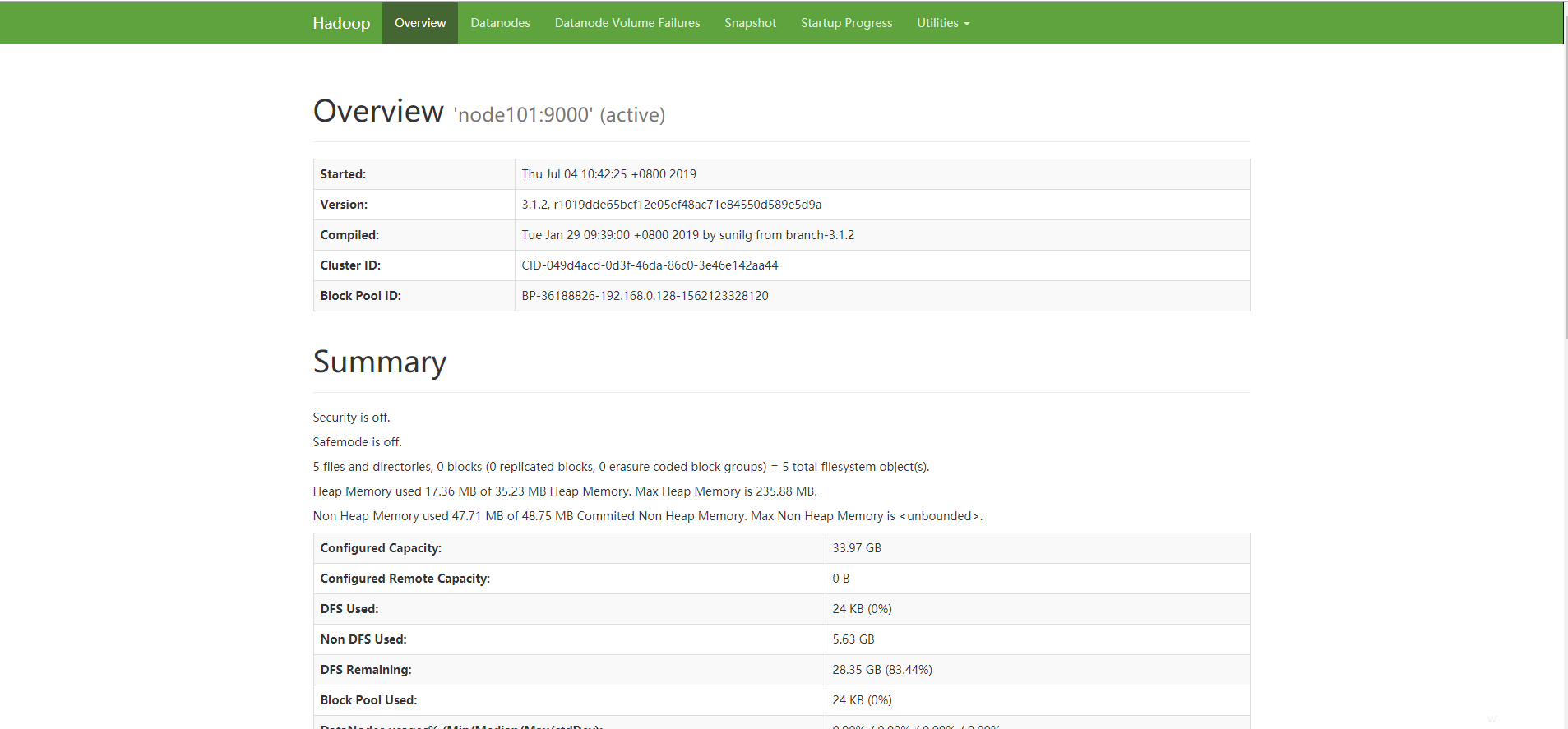
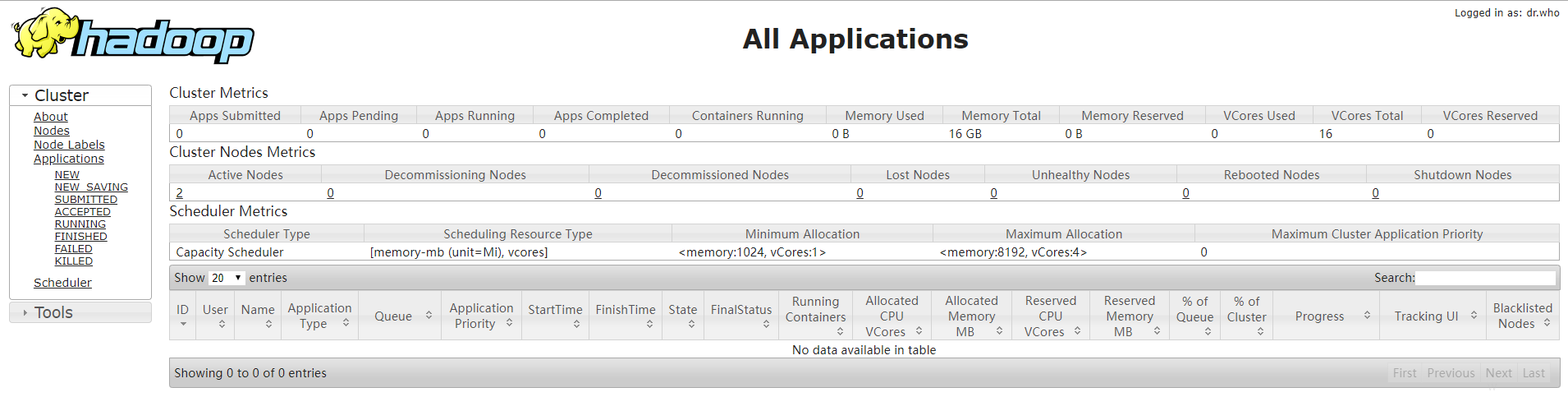
主节点:Namenode、SecondaryNamenode、ResourceManager
从节点:Datanode、NodeManager

 浙公网安备 33010602011771号
浙公网安备 33010602011771号