
计网Quizzes学习记录
写在前面
这篇是计网练习记录,包含错题和需要注意的点。
网址点这里,直接进去改chapter后面的数字就可以换章
发现一个网站有对应的答案解析
chapter1

星形中间的那一个不算在这六台里……
chapter2

端口号标识的是进程,运输层负责的就是进程到进程的传输。
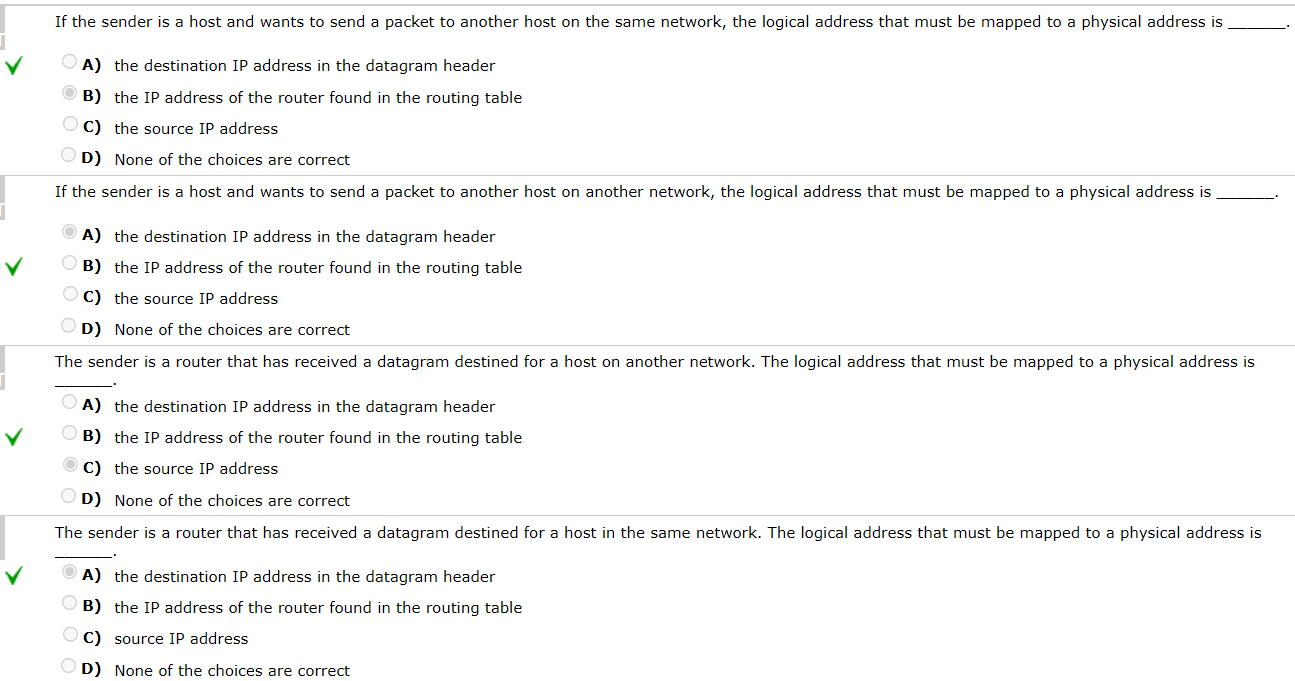
这里的logical address指的就是ip地址。

OSI七层模型(自顶向下):应用层、表示层、会话层、运输层、网络层、数据链路层、物理层。
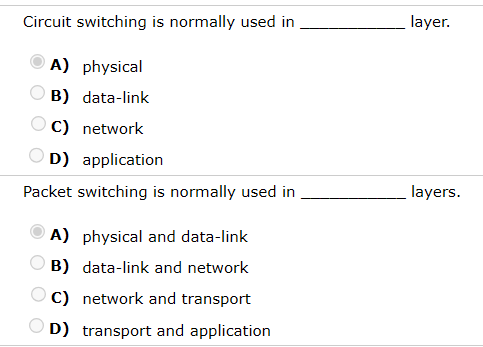
chapter8 电路交换 分组交换
-
物理层与数据链路层的区别?
物理层:肉眼可见的,包括光纤、电缆、调制解调器、编码器解码器等设备和信号传输介质
数据链路层:包括二层交换机、网卡、网桥等
-
电路交换的三种状态:建立连接;传输数据;断开连接

这题答案和解析有冲突,因为说的目的地址,没说是IP还是MAC,总之分组转发过程中(考虑没有使用NAT技术的情况),源IP和目的IP全程不变,源MAC和目的MAC会在每一跳改变。
chapter9 链路层
- point-to-point(unicast) & multicast & broadcast
- 单播(点对点)是一个节点对另一个节点的单独通信,不与其他节点共享链路
- 多播(组播)可以用于网络视频会议或视频点播可以一次性将数据传给所有请求了该数据的节点,而不是对每个目标节点单独传送一次。
- 广播只能在同一子网内进行,会占用当前子网内的几乎全部带宽。广播与多播的区别在于,广播会把数据传给当前子网内所有节点,多播能区分哪些节点请求了该数据并进行一次性传送。

ARP协议,全称是Address Resolution Protocol地址解析协议,用于通过IP地址获取对应主机的MAC地址。
每台电脑里都有一个ARP缓存表,标识主机名及其对应的IP地址和MAC地址。
当主机A要向主机B(只知道IP)发送数据,A首先在自己的缓存表里找有没有B的记录,若有则直接发送;若没有,A向网络中发送一个广播(ARP reequest),目的IP是B的IP,目的MAC是FF.FF.FF.FF.FF.FF,所有与A同网段的主机都会收到这条请求。其他主机看到这个IP不是自己的,会丢弃这个请求,只有B会接收,并向A做出回应,因为B可以从A的请求中拿到A的IP和MAC,所以B采用单播(ARP response)对A做出回应,并更新自己的ARP缓存表。A拿到B的回应后,也会更新自己的ARP缓存表。
- 感觉这个描述好绕……
chapter10 错误检测
-
汉明码,想要检测d位错误,需要汉明距离至少是d+1;想要纠正d位错误,需要汉明距离至少是2d+1
-
单比特错误


+0的原码、反码、补码都是00000000
-0的原码是10000000,反码是11111111,补码是00000000
是因为8位原码能表示的最大正数就是127(因为最高位是符号位)
接收方计算结果全为1时表示没有出现错误(或者有两位错误但被抵消)
chapter13 MAC

preamble是物理层头部,7个字节,每个字节固定为0xAA
chapter18 网络层

流量控制是数据链路层(点到点)和传输层(端到端)进行的

因为ipv4总共32位,用.分隔的表达形式就是4个十进制数,所以相当于8位二进制数用一个数字表达

chapter19 IP

因为IP的首部长度是20-60字节,这个字段是4bit,所以最大表示十进制的15,所以首部长度字段的值+1,相当于实际上的首部长度+4字节。所以这个值是十进制的10,意味着真正的长度是4 * 10 = 40

标志字段中的最低为是MF(More Fragment),MF = 1表示后面还有分片的数据报,MF = 0表示当前的就是最后一个分片数据报。所以MF与偏移量和总长度都有关。IP数据报长度是首部加上数据的总长度。

fragment offset字段的计算方法:
假设IP首部是20字节,MTU为1500,数据长度1480字节
第一个包:偏移量0 / 8 = 0,MF = 1
第二个包:偏移量1480 / 8 = 185,MF = 1
第三个包:偏移量2 * 1480 / 8 = 370,MF = 0
偏移量表示的就是当前分片在这些分片中的偏移量
所以偏移量的值乘上8的结果,表示的是当前数据包的第一个字节是当前数据段中的第几个字节。

可以确定的是A和C必然不正确。根据ICMP的RFC文档和其他一些教科书的描述(黑皮书没有详细地写),B应该是应选答案,因为ICMP应该可以且仅可以为第一个分片数据包产生错误信息,而不是不能为分片产生错误信息。但答案不知道为什么给的是D,我倾向于认为答案有错。
- 就随便看一眼吧 貌似书上也是没讲



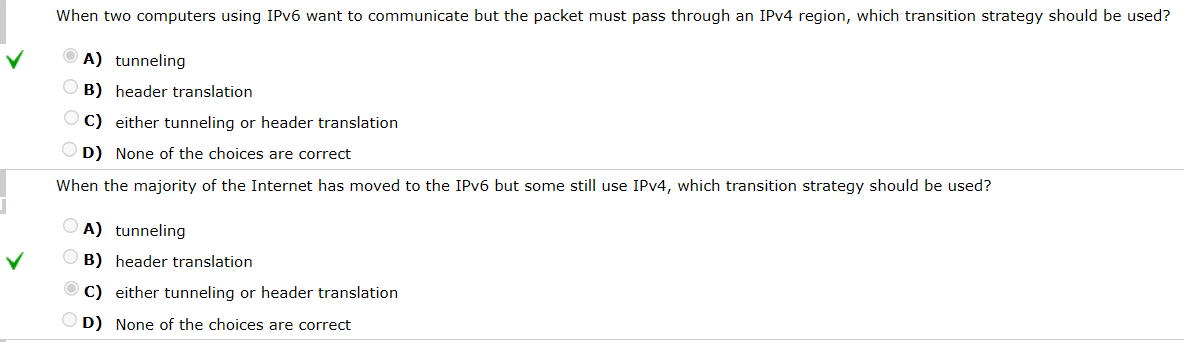
chapter22 IPv6

以太网帧最小长度是64字节,NIC位数是48bit
这一节第4、5题应该是题目放反了。
chapter23 GBN SR

没太弄懂,但SR对每个包都维护一个计时器,若出现超时,只重传超时的那一个包。
chapter24 TCP UDP

虽然运输层数据分组被称作segment,但是UDP的分组常被称为数据报(datagram),UDP本身就是User Datagram Protocol的缩写。
-
UDP的首部是固定的8个字节,TCP首部是20字节。

TCP半开连接是指已建立连接的两端中的一端突然崩溃或者在未通知对方的前提下关闭连接。这种情况下无法正常收发数据。
半闭连接是指只有一方发送了FIN,另一方没有发出FIN包,仍然可以在一个方向上正常发送数据。
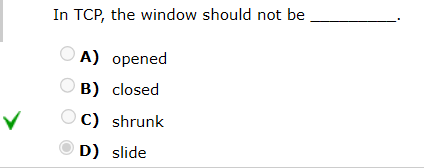
RFC不建议/不允许窗口收缩,必须保证窗口的右边沿永远不向左移动。

ACK不消耗序列号(因为ACK不需要被某个包确认),SYN/SYN+ACK/FIN/FIN+ACK消耗1个序列号。


其实这句话中文我没太懂,但这应该是RFC的原句。
-
这两道题是连着的


这个offset位就是用来标识TCP报头的总长度的(因为TCP报头长度是可变的)。offset的值在[5,15],offset增加1位,TCP的报头长度增加4个字节。 -
三道题是连着的,都是关于Reno TCP的快速恢复

主要是要注意英文表述 -
TCP——以字节为单位的


chapter25 Java网络编程(不重要 顺便做一下)
-
下面这几个有关Java的 确实不知道

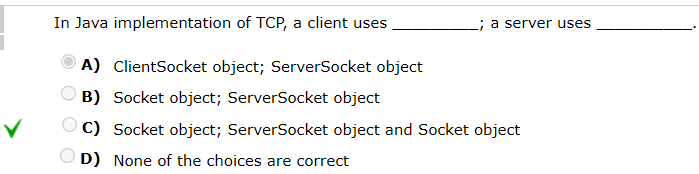

-
这个课上没有明确讲,但是可以自己理解

chapter26 应用层各种协议

-
关于编码方式的特点


这个题其实网上查到的是Teletype Network
-
这个确实没注意过



DNS用UDP进行名称查询,用TCP进行区域传输
- 注意区分这俩
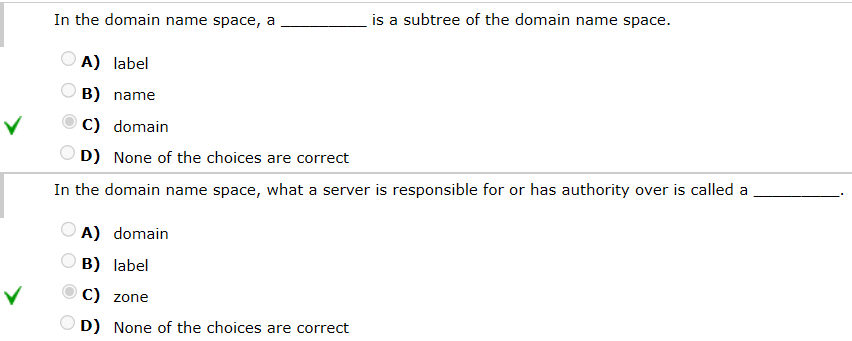
chapter29 p2p

书上说的是:在BitTorrent中,DHT得到了广泛实现。
所以他是结构化p2p。
- 关于DHT

p2p的分类
- 集中目录式
出现最早。仍有中心化特点,被称为非纯粹的p2p。用户注册与文件检索过程类似于CS模式,但所有资料不集中存储在中心服务器上,而是分散存在各个节点中。
例子:Napster - 纯p2p/广播式/非结构化p2p
取消中央服务器,用户随机接入,每个用户与自己的相邻节点构成端到端网络。泛洪搜索,导致网络不稳定和堵塞。
例子:Gnutella、eDonkey - 结构化p2p
采用DHT。各节点不需要维护整个网络的信息,只维护与其相邻的后继节点信息。取消了泛洪算法。
例子:Kademlia、CAN、Chord、Pastry - 混合式p2p
在非结构化基础上引入了超级节点,综合了去中心化和快速查找的优势。
例子:BitTorrent


 浙公网安备 33010602011771号
浙公网安备 33010602011771号