第二次作业
| 这个作业属于哪个课程 | 2021春软件工程实践|S班 (福州大学) |
|---|---|
| 这个作业要求在哪里 | 软工实践寒假作业(2/2) |
| 这个作业的目标 | 阅读《构建之法》;掌握开发流程 |
| 其他参考文献 | 无 |
| 本次作业首先快速完整阅读《构建之法》,并提出若干问题。 |
然后学习git版本管理工具,并完成一道词频统计编程题
目录:
关于《构建之法》的几个问题
第10章 典型用户和场景 212页
且不论这是否能覆盖所有用户,就是一味追求“最大的扩展性”也会有很多副作用。
一味追求“最大的扩展性”会有什么副作用呢?
要有最大的扩展性,开发中对产品就要有最大的抽象。这样的工作偏离了原来的方向。抽象产品、需求或者功能,与其说是生产产品,不如说是在生产产品maker。虽然这样的抽象可以方便以后产品扩展,但是抽象的产品与原本的产品之间总归有一定的距离,让人难以理解,会在一定程度上影响开发。过度最求可扩展性可以说是“过度优化”。事实上,做到“有一定的扩展性”相对来说就容易得多,这样的工作有理论支持,也有现有的框架利用。比如产品使用MVC模式就可以满足大部分扩展性要求。
以上是我能想到的一个副作用,不知其他副作用是什么。
第11章 软件设计与实现 239页
在这个领域一个比较成熟和经过实践考验的方法是Vienna Development Method(VDM)。
VDM是什么?
参考The Vienna Development Method,VDM是计算系统的形式化规范和开发的技术集合。它由一种称为VDM-SL的规范语言组成;数据和操作细化规则,允许在抽象需求规范和详细设计规范之间建立链接,直至代码级别;以及一种证明理论,在这种理论中,可以对特定系统的性质和设计决策的正确性进行严格的论证。关于如何使用VDM形式化的设计软件,除了看不懂的代码(AbstractPacemaker)外,没有更通俗的描述了。
第13章 软件测试 290页
在做效能测试的时候,的确要避免在不现实的环境中测试,例如要避免在没有任何用户、商品记录的系统上做测试;但是也没有必要为了追求真实而过分模拟随机的环境。
一般在测试的时候是怎样模拟现实的环境呢?毕竟自己手动添加记录,发出请求不太现实。就算编写小工具来实现,也还要考虑正确性,总感觉除了VSTS以外,还有其他现成工具可以帮助模拟,毕竟不是所有的开发都是在VS上进行。搜索一下,找到一个叫做LoadRunner的测试工具(百度百科)。可以利用这个工具,方便的模拟真实用户行为,还可以分析得到的数据,用于优化程序,查找问题等。
在随机的环境下,可以得到用户最可能体验到的程序效能,对程序优化有指导意义。所以随机的环境还是有价值的。
第13章 软件测试 295页
如果你的目的是让问题尽快显现,尽快找到问题,那我建议用Debug版本,“尽快发现问题”在软件开发周期的早期特别重要。如果你的目的是尽可能测试用户所看到的软件,则用Release版本,这在软件开发后期特别是执行效能和压力测试时很有价值。
这里的理由是什么?一般我在写代码的时候不会去改变解决方案配置,从来都是用默认的Debug版本。Debug和Release有什么区别,至今还没有了解过。参考VS中Debug和Release的详细区别和断点原理与实现这两篇文章,对这两者区别有了一些认识。编译器在编译时,可以利用程序中的空指令插入断点,方便断点调试和单步调试。不过在Release版本中,这些空指令会被优化掉,因此Release版本难以设置断点。为了方便调试,Debug链接的运行时库包含调试信息,这会导致性能不如Release版本。因为Debug版的运行时库对错误的检测更强,比如指针越界,导致有些错误Debug有,但是Release没有。因此,为了确保程序的正确性,或者找出程序的问题,应该用Debug版本。而Release版本一般作为发布时的版本,编译器对此作了更多优化,也最接近用户体验到的版本。还有一些Debug和Release的细节。比如,Debug版本往往会吧没有初始化的变量自动赋值为0,而Release版本会有一个随机值;Debug不会做内存优化,因此一些指针越界很有可能刚好指向数组后的变量,Release做了优化,内存分布不一定按照声明的顺序来,指针越界直接导致程序崩溃。不注意这些细节,可能导致Debug没问题,但Release确有问题。对于一开始的问题,我认为解释就是如此,不知道是否还有其他重要的理由。
第17章 人,绩效和职业道德 389页
积极的学习者
...
领导应该做的:
- 能力方面的帮助:肯定他们带来的可转化技能。要替他们设置SMART目标、优先级和检查点,循序渐进的学习计划;要定义他们在团队中的角色和范围,限制自主性发挥;提供资料让他们学习,例如:展示实际的例子和模板、已有的解决方案;提供练习机会,或者做一对一的指导(Mentor)。
积极地学习者最大的特点就是积极。但有时候太积极又不好,领导者应该怎么应对太积极的初学者。很容易遇到,实际上也遇到过这样的初学者:什么都不懂,但更糟糕的是不懂得问题的重要性,有问题就一股脑问出来。其实对初学者来说,有些问题自己解决能够让他成长得更快,全部回答他的问题会影响以后他解决问题的能力。问题更具体地说,应该怎样指导初学者学习方向?应该怎样平衡“解决疑惑”和“培养自立”?
Word Count
项目地址
https://github.com/Wuzinian/PersonalProject-C
PSP记录预计
| Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|
| 计划 | ||
| • 估计这个任务需要多少时间 | 300 | 420 |
| 开发 | ||
| • 需求分析 (包括学习新技术) | 50 | 70 |
| • 生成设计文档 | 10 | 10 |
| • 设计复审 | 5 | 5 |
| • 代码规范 (为目前的开发制定合适的规范) | 10 | 25 |
| • 具体设计 | 30 | 30 |
| • 具体编码 | 60 | 150 |
| • 代码复审 | 40 | 60 |
| • 测试(自我测试,修改代码,提交修改) | 55 | 110 |
| 报告 | ||
| • 测试报告 | 20 | 30 |
| • 计算工作量 | 20 | 10 |
| • 事后总结, 并提出过程改进计划 | 20 | 20 |
| 合计 | 320 | 520 |
解题思路
先读取文件,并按行存在字符串数组里。
分割字符串虽然可以用std::readline做,但是存在\r\n等不能舍弃,因此要自己进行分割。
字符统计种的一些特殊字符在分割的时候完成。虽然助教说输入都是ASCII字符,但是以防万一,还是遍历数组,数一数字符。
统计有效行数,只要遍历数组,看字符串是否包含非空白字符。由于回车换行等符号具有特殊性,因此会另外统计。
统计单词频率和单词数,只要遍历数组,按题目对分隔符的要求,分割成单词,进行判断(是否可判定为单词),用std::map<string, int>存放,并累加计数。
TOP10,把map转换成数组,按相应规则排序即可。
代码规范
github.com/Wuzinian/PersonalProject-C/blob/main/221801228/codestyle.md
接口的设计与实现
虽然题目可以分成4个功能,但是实际使上应该没人会分开始用,因此3个功能写在一个count函数里,
static CountResult count(const std::string &file);
这个函数放在CounterCore类里,由其他函数调用。
CountResult是一个包含字符数,有效行数,单词数和单词及频数等数据的结构
class CountResult
{
public:
int charCount;
int wordCount;
int lineCount;
std::map<std::string, int> wordOccurs;
CountResult() : charCount(0), wordCount(0), lineCount(0) { }
};
调用者获得这些数据后,自行排序输出。
auto result = Counter::count("test.txt");
writeResult(result, "out.txt");
将文件分按行分割之前,先全部读入文件
std::istreambuf_iterator<char> begin(is);
std::istreambuf_iterator<char> end;
std::string all(begin, end);
然后遍历字符串,如果遇到换行,那就把标记的开始到当前位置的字符串存入数组,回车符号不会存入字符串数组,因为对后续的单词统计没用处,不过实际上存入也不会影响,在这里是一个别扭的设计。
std::vector<std::string> lines;
std::string line;
char pre = '\0';
int start = 0;
int i;
for (i = 0; i < all.size(); i++)
{
if (all[i] == '\n')
{
if (pre == '\r')
{
lines.push_back(all.substr(start, i - start - 1));
result.charCount++;
}
else
lines.push_back(all.substr(start, i - start));
result.charCount++;
start = i + 1;
}
pre = all[i];
}
对于统计字符,只要遍历数组中字符串的每一个字符,判断是否为ASCII字符就好
void Core::Counter::countChars(std::vector<std::string> &lines)
{
std::cout << lines.size() << std::endl;
for (int i = 0; i < lines.size(); i++)
for (int j = 0; j < lines[i].size(); j++)
if (isascii(lines[i][j]))
result.charCount++;
}
对于单词数统计,只要对每行按分隔符分割,然后将判定为单词的字符串存入map
void Core::Counter::countWords(std::vector<std::string> &lines)
{
for (auto it = lines.begin(); it != lines.end(); ++it)
{
auto words = split(*it);
result.wordCount += words.size();
for (int i = 0; i < words.size(); i++)
{
result.wordOccurs[words[i]] += 1;
result.wordCount++;
}
}
}
对于有效行数,只要遍历每一行种的每个字符,判断是否存在非空白字符就好
void Core::Counter::countLines(std::vector<std::string> &lines)
{
for (int i = 0; i < lines.size(); i++)
for (int j = 0; j < lines[i].size(); j++)
if (!isspace(lines[i][j]))
{
result.lineCount++;
break;
}
}
对于统计频数前十的单词,由于c++的map默认按key也就是单词升序排序,因此只要对转换后的数组进行稳定排序,就可以做到题目要求的频数相同按字典序排序
using WordPair = std::pair<std::string, int>;
std::vector<WordPair> words(result.wordOccurs.begin(), result.wordOccurs.end());
std::stable_sort(words.begin(), words.end(),
[](const WordPair& a, const WordPair& b)
{
return a.second > b.second;
}
);
性能改进
上诉方法字符统计混乱,而且多余的遍历过多,实际上只要一个循环就能做完三个统计。
从输入流不断读取字符,根据当前的一些标志(例如,读单词标记,有效行标记,忽略标记)对统计数据进行修改.
由于遇到'\n'才会结算单词和行,文本的最后一行需要在循环结束后再次判断。std::ifstream读取字符效率存在问题,因此换成C的方式。
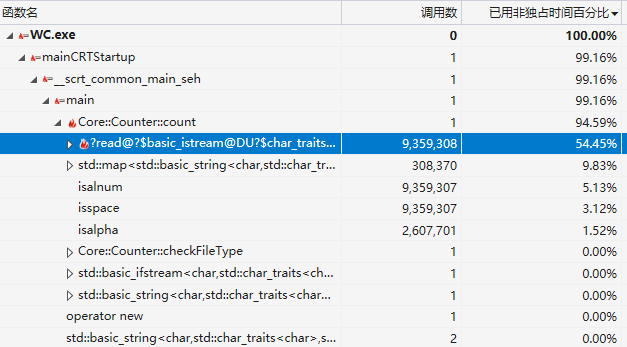
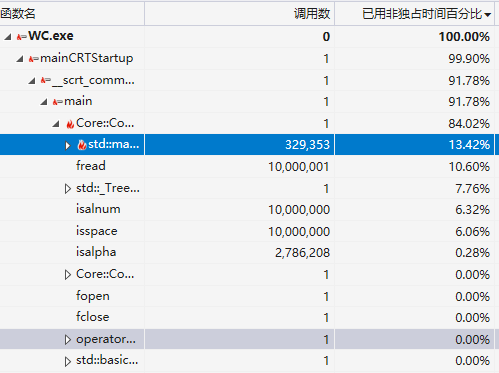
可以看到,C的方式读取时间下降很多。
改进后的分析过程
FILE* file = fopen(fileName.c_str(), "rb");
char c = '\0';
while (fread(&c, sizeof(c), 1, file) != 0)
{
if (c >= -1 && c <= 255 && isascii(c))
result.charCount++;
if (!isascii(c) || !isspace(c))
isLine = true;
if (c == '\n')
{
有效行统计
isLine = false;
}
bool isDvsn = isDivision(c);
if (!isDvsn && !ignore)
{
单词的开始
}
if (isDvsn)
ignore = false;
if (isDvsn && readingWord)
{
单词结束,统计单词
}
}
单元测试
测试数据,回车包含\r\n
2222 boundary
for444 444for fundamental
br
boundary
2222和444for针对数字开头单词的判定,for444针对至少4个字母开头, br和空行针对有效行的判定,两个boundary和一个fundamental针对单词统计。
预计输出为
characters: 63
words: 3
lines: 4
boundary: 2
fundamental: 1
单元测试设置,设置一组测试结果,两组测试不同编码文件的判定,一组测试不存在的输入文件,一组测试大文件(1亿字符)统计。测试结果如下
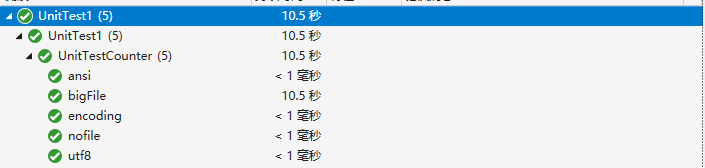
大文件测试结果如下:
characters: 100000000
words: 2098034
lines: 6593066
ckbb: 7
tokz: 7
adzg: 6
aihn: 6
bgzw: 6
cgpz: 6
dbjj: 6
dezq: 6
dygr: 6
enqw: 6
覆盖率如下

测试环境:i3-6100
关于如何提高覆盖率
进行正确的分支,即所有分支都有意义;
尽量减少分支,可以减少单元测试难度;
抛出有意义的异常;
针对分支和异常做测试可以提高覆盖率。
异常处理
在文件编码不是utf8时抛出异常
if (encoding != FileType::UTF8 && encoding != FileType::UTF8BOM)
throw std::invalid_argument(("file " + fileName + " is not an UTF-8 encoding file\n").c_str());
读写文件失败时抛出异常
std::ifstream fin(file, std::ios_base::binary);
if (!fin.is_open())
throw std::ios::failure(("open " + fileName + " failed\n").c_str());
std::ofstream os(file, std::ios_base::trunc);
if (!os.is_open())
throw std::ios::failure(("can not write file " + file + "\n").c_str());
心路历程与收获
慢慢学习git的过程中,一次次惊叹竟有如此优秀的工具,相恨见晚
一开始看到题目,想的是简单实现一个,然后逐步优化。但是想写的简单,漏洞反而多,没有达到预期效果。最后还有很多优化空间,但是涉及我不擅长和不懂的知识,因而怯步。
单元测试要求覆盖率,这让我从另一个角度看到了自己代码设计的不合理之处。看着那些没被覆盖的部分,就迸发出改进和优化的点子。
这次作业暴露出我太多薄弱的地方,今后要继续努力。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号