
ConcurrentHashMap 实现原理和源码分析
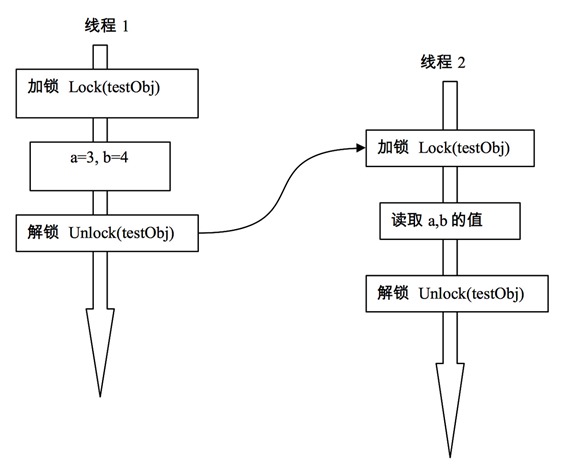
结构
HashMap结构图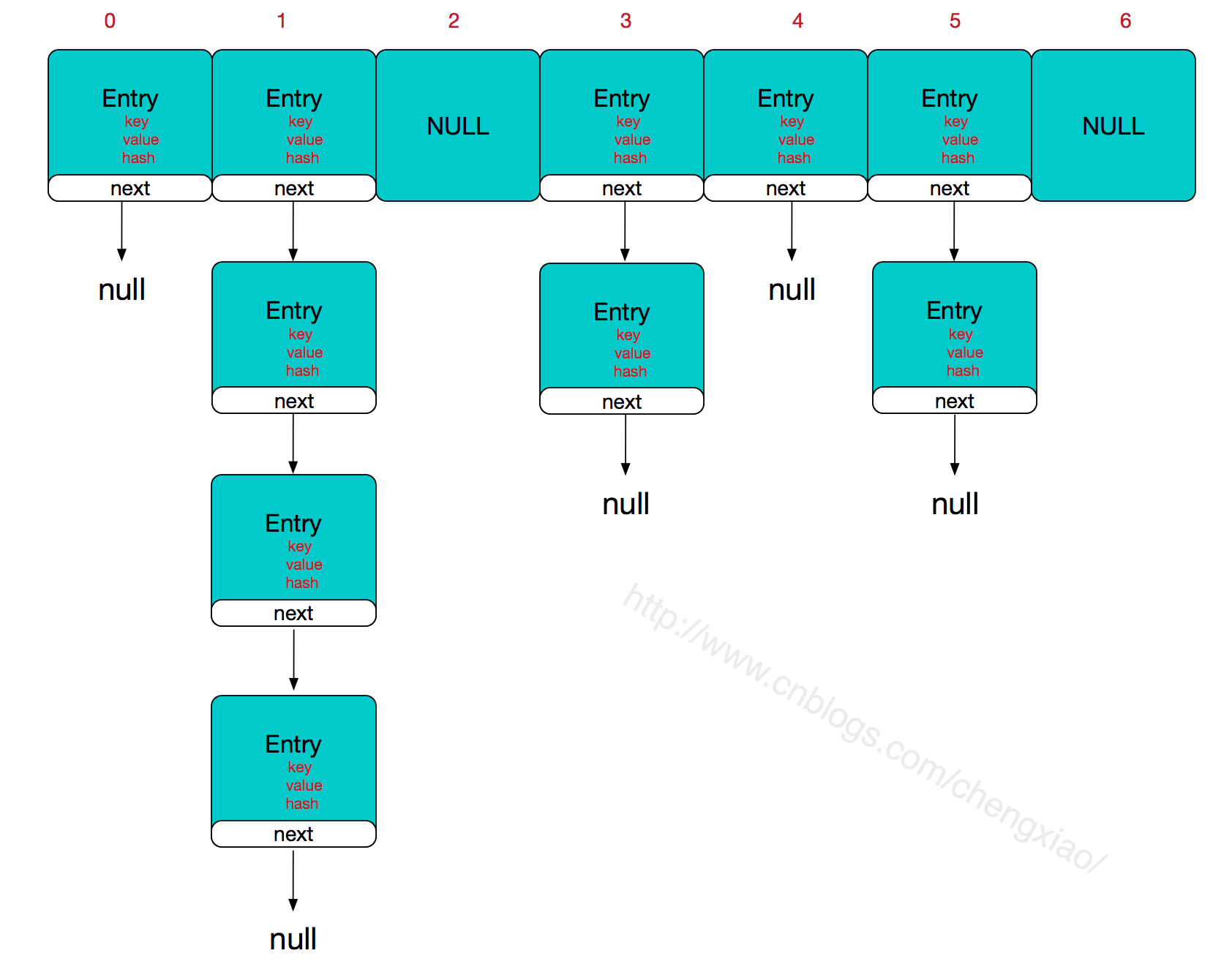

static final class HashEntry<K,V> {
final K key;
final int hash;
volatile V value;
final HashEntry<K,V> next;
} static final class Segment<K,V> extends ReentrantLock implements Serializableq
每个segment使用对象自身的锁来实现。只有对全局需要改变时锁定的是所有的segment。
这种做法,就称之为“分离锁(lock striping)
分拆锁(lock spliting)就是若原先的程序中多处逻辑都采用同一个锁,但各个逻辑之间又相互独立,就可以拆(Spliting)为使用多个锁,每个锁守护不同的逻辑。
分拆锁有时候可以被扩展,分成可大可小加锁块的集合,并且它们归属于相互独立的对象,这样的情况就是分离锁(lock striping)。(摘自《Java并发编程实践》)
初始化
它把区间按照并发级别(concurrentLevel),分成了若干个segment。默认情况下内部按并发级别为16来创建。对于每个segment的容量,默认情况也是16。concurrentLevel,segment 可以通过构造函数设定的。通过按位与的哈希算法来定位segments数组的索引,必须保证segments数组的长度是2的N次方(power-of-two size),所以必须计算出一个是大于或等于concurrencyLevel的最小的2的N次方值来作为segments数组的长度。
定位Segment
ConcurrentHashMap会首先使用Wang/Jenkins hash的变种算法对元素的hashCode进行一次再哈希,其目的是为了减少哈希冲突,使元素能够均匀的分布在不同的Segment上,从而提高容器的存取效率。默认情况下segmentShift为28,segmentMask为15,再哈希后的数最大是32位二进制数据,向右无符号移动28位,意思是让高4位参与到hash运算中, (hash >>> segmentShift) & segmentMask的运算结果分别是4,15,7和8,可以看到hash值没有发生冲突
final Segment<K,V> segmentFor(int hash) {
return segments[(hash >>> segmentShift) & segmentMask];
}remove操作
不同segment,可以并发操作
public V remove(Object key) {
hash = hash(key.hashCode());
return segmentFor(hash).remove(key, hash, null);
}
V remove(Object key, int hash, Object value) {
lock();
try {
int c = count - 1;
HashEntry<K,V>[] tab = table;
int index = hash & (tab.length - 1);
HashEntry<K,V> first = tab[index];
HashEntry<K,V> e = first;
while (e != null && (e.hash != hash || !key.equals(e.key)))
e = e.next;
V oldValue = null;
if (e != null) {
V v = e.value;
if (value == null || value.equals(v)) {
oldValue = v;
// All entries following removed node can stay
// in list, but all preceding ones need to be
// cloned.
++modCount;
HashEntry<K,V> newFirst = e.next;
for (HashEntry<K,V> p = first; p != e; p = p.next)
newFirst = new HashEntry<K,V>(p.key, p.hash,
newFirst, p.value);
tab[index] = newFirst;
count = c; // write-volatile
}
}
return oldValue;
} finally {
unlock();
}
}如果节点不存在就直接返回null,否则就要将e前面的结点复制一遍,尾结点指向e的下一个结点。因为entry除了value是volatile属性,其他都是final修饰的,所以不能重新对next域赋值,只能重新clone一次。至于entry为什么要设置为不变性,这跟不变性的访问不需要同步从而节省时间有关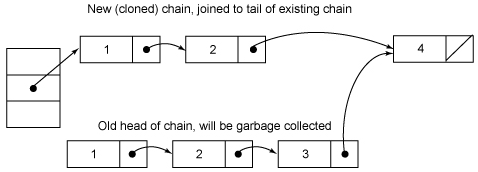
get操作
Segment的get方法
public V get(Object key) {
int hash = hash(key.hashCode());
return segmentFor(hash).get(key, hash);
}
V get(Object key, int hash) {
if (count != 0) { // read-volatile 当前桶的数据个数是否为0
HashEntry<K,V> e = getFirst(hash); 得到头节点
while (e != null) {
if (e.hash == hash && key.equals(e.key)) {
V v = e.value;
if (v != null)
return v;
return readValueUnderLock(e); // recheck
}
e = e.next;
}
}
return null;
} get操作的高效之处在于整个get过程不需要加锁,除非读到的值是空的才会加锁重读。我们知道HashTable容器的get方法是需要加锁的,原因是它的get方法里将要使用的共享变量都定义成volatile,在get操作里只需要读不需要写共享变量count和value,所以可以不用加锁。之所以不会读到过期的值,是根据java内存模型的happen before原则,对volatile字段的写入操作先于读操作,即使两个线程同时修改和获取volatile变量,get操作也能拿到最新的值,这是用volatile替换锁的经典应用场景。
理论上结点的值不可能为空,这是因为 put的时候,如果为空就要抛NullPointerException。空值是因为put,remove操作时候,tab[index] = new HashEntry<K,V>(key, hash, first, value)重新克隆了节点前的数据。
V readValueUnderLock(HashEntry<K,V> e) {
lock();
try {
return e.value;
} finally {
unlock();
}
}put操作
Segment的put方法。
V put(K key, int hash, V value, boolean onlyIfAbsent) {
lock();
try {
int c = count;
if (c++ > threshold) // ensure capacity
rehash();
HashEntry<K,V>[] tab = table;
int index = hash & (tab.length - 1);
HashEntry<K,V> first = tab[index];
HashEntry<K,V> e = first;
while (e != null && (e.hash != hash || !key.equals(e.key)))
e = e.next;
V oldValue;
if (e != null) {
oldValue = e.value;
if (!onlyIfAbsent)
e.value = value;
}
else {
oldValue = null;
++modCount;
tab[index] = new HashEntry<K,V>(key, hash, first, value);
count = c; // write-volatile
}
return oldValue;
} finally {
unlock();
}
}第一步判断是否需要对Segment里的HashEntry数组进行扩容,第二步定位添加元素的位置然后放在HashEntry数组里。在插入元素前会先判断Segment里的HashEntry数组是否超过容量(threshold),如果超过阀值,数组进行扩容。值得一提的是,Segment的扩容判断比HashMap更恰当,因为HashMap是在插入元素后判断元素是否已经到达容量的,如果到达了就进行扩容,但是很有可能扩容之后没有新元素插入,这时HashMap就进行了一次无效的扩容。
扩容的时候首先会创建一个两倍于原容量的数组,然后将原数组里的元素进行再hash后插入到新的数组里。为了高效ConcurrentHashMap不会对整个容器进行扩容,而只对某个segment进行扩容。
containsKey操作
boolean containsKey(Object key, int hash) {
if (count != 0) { // read-volatile
HashEntry<K,V> e = getFirst(hash);
while (e != null) {
if (e.hash == hash && key.equals(e.key))
returntrue;
e = e.next;
}
}
returnfalse;
} size()操作
如果我们要统计整个ConcurrentHashMap里元素的大小,就必须统计所有Segment里元素的大小后求和。Segment里的全局变量count是一个volatile变量,那么在多线程场景下,我们是不是直接把所有Segment的count相加就可以得到整个ConcurrentHashMap大小了呢?不是的,虽然相加时可以获取每个Segment的count的最新值,但是拿到之后可能累加前使用的count发生了变化,那么统计结果就不准了。所以最安全的做法,是在统计size的时候把所有Segment的put,remove和clean方法全部锁住,但是这种做法显然非常低效。因为在累加count操作过程中,之前累加过的count发生变化的几率非常小,所以ConcurrentHashMap的做法是先尝试2次通过不锁住Segment的方式来统计各个Segment大小,如果统计的过程中,容器的count发生了变化,则再采用加锁的方式来统计所有Segment的大小。
那么ConcurrentHashMap是如何判断在统计的时候容器是否发生了变化呢?使用modCount变量,在put , remove和clean方法里操作元素前都会将变量modCount进行加1,那么在统计size前后比较modCount是否发生变化,从而得知容器的大小是否发生变化。
参考资料
- 《Java并发编程实践》
- 深入分析ConcurrentHashMap

