
Elasticsearch 之(13)lucene的相关度评分TF&IDF算法以及向量空间模型算法
1、boolean model
类似and这种逻辑操作符,先过滤出包含指定term的doc
query "hello world" --> 过滤 --> hello / world / hello & world
bool --> must/must not/should --> 过滤 --> 包含 / 不包含 / 可能包含
doc --> 不打分数 --> 正或反 true or false --> 为了减少后续要计算的doc的数量,提升性能query: hello world
"match": {
"title": "hello world"
}
"bool": {
"should": [
{
"match": {
"title": "hello"
}
},
{
"match": {
"title": "world"
}
}
]
}普通multivalue搜索,转换为bool搜索,boolean model2、TF/IDF算法介绍
relevance score算法,简单来说,就是计算出,一个索引中的文本,与搜索文本,他们之间的关联匹配程度
Elasticsearch使用的是 term frequency/inverse document frequency算法,简称为TF/IDF算法
Term frequency:搜索文本中的各个词条在field文本中出现了多少次,出现次数越多,就越相关
搜索请求: hello world --> doc.content
doc1: java is my favourite programming language, hello world !!!
doc2: hello java, you are very good, oh hello world!!!
doc2: hello java, you are very good, oh hello world!!!
Inverse document frequency:搜索文本中的各个词条在整个索引的所有文档中出现了多少次,出现的次数越多,就越不相关
搜索请求:hello world
doc1:hello, today is very good
doc2:hi world, how are you
hello对doc1的评分
TF: term frequency
找到hello在doc1中出现了几次,1次,会根据出现的次数给个分数
一个term在一个doc中,出现的次数越多,那么最后给的相关度评分就会越高
IDF:inversed document frequency
找到hello在所有的doc中出现的次数,3次
一个term在所有的doc中,出现的次数越多,那么最后给的相关度评分就会越低
length norm
hello搜索的那个field的长度,field长度越长,给的相关度评分越低; field长度越短,给的相关度评分越高
最后,会将hello这个term,对doc1的分数,综合TF,IDF,length norm,计算出来一个综合性的分数
hello world --> doc1 --> hello对doc1的分数,world对doc1的分数 --> 但是最后hello world query要对doc1有一个总的分数 --> vector space model
一个term在所有的doc中,出现的次数越多,那么最后给的相关度评分就会越低
length norm
hello搜索的那个field的长度,field长度越长,给的相关度评分越低; field长度越短,给的相关度评分越高
最后,会将hello这个term,对doc1的分数,综合TF,IDF,length norm,计算出来一个综合性的分数
hello world --> doc1 --> hello对doc1的分数,world对doc1的分数 --> 但是最后hello world query要对doc1有一个总的分数 --> vector space model
_score是如何被计算出来的
GET /test_index/test_type/_search?explain
{
"query": {
"match": {
"test_field": "hello world"
}
}
}"description": "tfNorm, computed as (freq * (k1 + 1)) / (freq + k1 * (1 - b + b * fieldLength / avgFieldLength)) from:"
3、vector space model
多个term生成的一个doc的总分数
hello world --> es会根据hello world在所有doc中的评分情况,计算出一个query vector,query向量
例如:
hello这个term,给的基于所有doc的一个评分就是2
world这个term,给的基于所有doc的一个评分就是5
query向量 就是 [2, 5]
query vector
doc vector,3个doc,一个包含1个term,一个包含另一个term,一个包含2个term
3个doc
doc1:包含hello --> 向量 [2, 0]
doc2:包含world --> 向量 [0, 5]
doc3:包含hello, world --> 向量[2, 5]
会给每一个doc,拿每个term经过lucene practical scoring function计算出一个分数来,hello有一个分数,world有一个分数,再拿所有term的分数组成一个doc vector
画在一个图中,取每个doc vector对query vector的弧度,给出每个doc对多个term的总分数
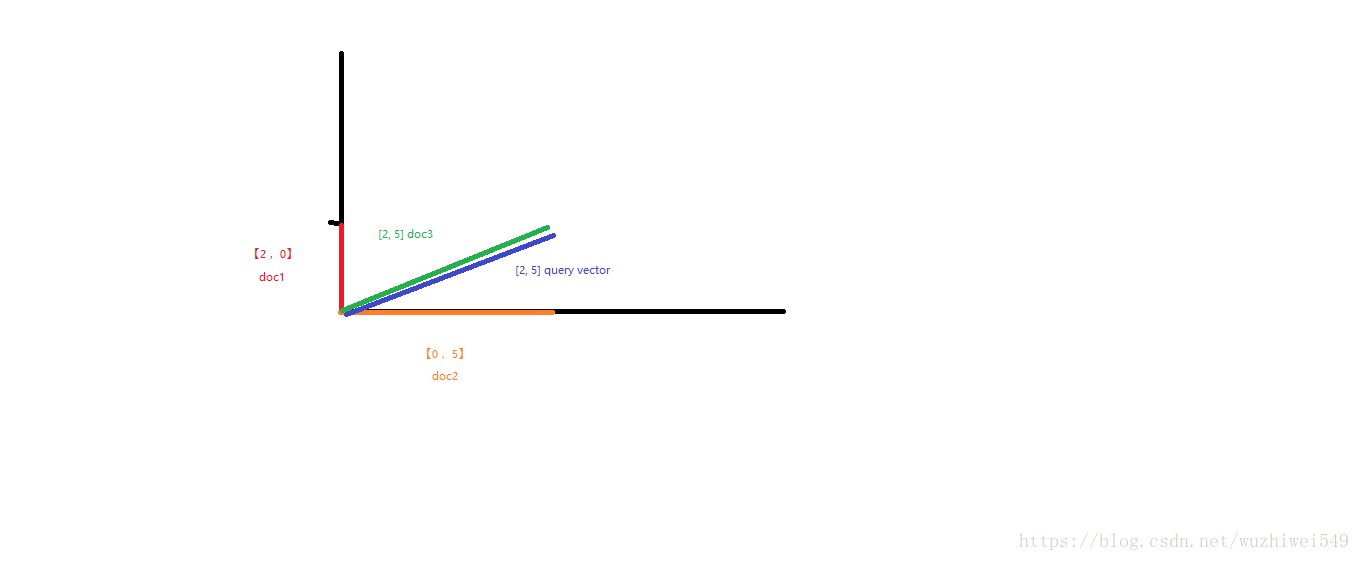
每个doc vector计算出对query vector的弧度,最后基于这个弧度给出一个doc相对于query中多个term的总分数
弧度越大,分数月底; 弧度越小,分数越高
如果是多个term,那么就是线性代数来计算,无法用图表示
这个公式的最终结果,就是说是一个query(叫做q),对一个doc(叫做d)的最终的总评分
queryNorm(q) is the query normalization factor (new).
queryNorm,是用来让一个doc的分数处于一个合理的区间内,不要太离谱,举个例子,一个doc分数是10000,一个doc分数是0.1,你们说好不好,肯定不好
coord(q,d) is the coordination factor (new).
简单来说,就是对更加匹配的doc,进行一些分数上的成倍的奖励
The sum of the weights for each term t in the query q for document d.
∑:求和的符号
∑ (t in q):query中每个term,query = hello world,query中的term就包含了hello和world
query中每个term对doc的分数,进行求和,多个term对一个doc的分数,组成一个vector space,然后计算吗,就在这一步
tf(t in d) is the term frequency for term t in document d.
计算每一个term对doc的分数的时候,就是TF/IDF算法
idf(t) is the inverse document frequency for term t.
计算每一个term对doc的分数的时候,就是TF/IDF算法
t.getBoost() is the boost that has been applied to the query (new).
增加权重
norm(t,d) is the field-length norm, combined with the index-time field-level boost, if any. (new).
搜索出的field长度越长,给的相关度评分越低; field长度越短,给的相关度评分越高
query normalization factor
queryNorm = 1 / √sumOfSquaredWeights
sumOfSquaredWeights = 所有term的IDF分数之和,开一个平方根,然后做一个平方根分之1
主要是为了将分数进行规范化 --> 开平方根,首先数据就变小了 --> 然后还用1去除以这个平方根,分数就会很小 --> 1.几 / 零点几
分数就不会出现几万,几十万,那样的离谱的分数
query coodination
奖励那些匹配更多字符的doc更多的分数
Document 1 with hello → score: 1.5
Document 2 with hello world → score: 3.0
Document 3 with hello world java → score: 4.5
Document 1 with hello → score: 1.5 * 1 / 3 = 0.5
Document 2 with hello world → score: 3.0 * 2 / 3 = 2.0
Document 3 with hello world java → score: 4.5 * 3 / 3 = 4.5
把计算出来的总分数 * 匹配上的term数量 / 总的term数量,让匹配不同term/query数量的doc,分数之间拉开差距
hello world --> es会根据hello world在所有doc中的评分情况,计算出一个query vector,query向量
例如:
hello这个term,给的基于所有doc的一个评分就是2
world这个term,给的基于所有doc的一个评分就是5
query向量 就是 [2, 5]
query vector
doc vector,3个doc,一个包含1个term,一个包含另一个term,一个包含2个term
3个doc
doc1:包含hello --> 向量 [2, 0]
doc2:包含world --> 向量 [0, 5]
doc3:包含hello, world --> 向量[2, 5]
会给每一个doc,拿每个term经过lucene practical scoring function计算出一个分数来,hello有一个分数,world有一个分数,再拿所有term的分数组成一个doc vector
画在一个图中,取每个doc vector对query vector的弧度,给出每个doc对多个term的总分数
每个doc vector计算出对query vector的弧度,最后基于这个弧度给出一个doc相对于query中多个term的总分数
弧度越大,分数月底; 弧度越小,分数越高
如果是多个term,那么就是线性代数来计算,无法用图表示
4、lucene practical scoring function
practical scoring function,来计算一个query对一个doc的分数的公式,该函数会使用一个公式来计算score(q,d) =
queryNorm(q)
· coord(q,d)
· ∑ (
tf(t in d)
· idf(t)2
· t.getBoost()
· norm(t,d)
) (t in q) score(q,d) score(q,d) is the relevance score of document d for query q.这个公式的最终结果,就是说是一个query(叫做q),对一个doc(叫做d)的最终的总评分
queryNorm(q) is the query normalization factor (new).
queryNorm,是用来让一个doc的分数处于一个合理的区间内,不要太离谱,举个例子,一个doc分数是10000,一个doc分数是0.1,你们说好不好,肯定不好
coord(q,d) is the coordination factor (new).
简单来说,就是对更加匹配的doc,进行一些分数上的成倍的奖励
The sum of the weights for each term t in the query q for document d.
∑:求和的符号
∑ (t in q):query中每个term,query = hello world,query中的term就包含了hello和world
query中每个term对doc的分数,进行求和,多个term对一个doc的分数,组成一个vector space,然后计算吗,就在这一步
tf(t in d) is the term frequency for term t in document d.
计算每一个term对doc的分数的时候,就是TF/IDF算法
idf(t) is the inverse document frequency for term t.
计算每一个term对doc的分数的时候,就是TF/IDF算法
t.getBoost() is the boost that has been applied to the query (new).
增加权重
norm(t,d) is the field-length norm, combined with the index-time field-level boost, if any. (new).
搜索出的field长度越长,给的相关度评分越低; field长度越短,给的相关度评分越高
query normalization factor
queryNorm = 1 / √sumOfSquaredWeights
sumOfSquaredWeights = 所有term的IDF分数之和,开一个平方根,然后做一个平方根分之1
主要是为了将分数进行规范化 --> 开平方根,首先数据就变小了 --> 然后还用1去除以这个平方根,分数就会很小 --> 1.几 / 零点几
分数就不会出现几万,几十万,那样的离谱的分数
query coodination
奖励那些匹配更多字符的doc更多的分数
Document 1 with hello → score: 1.5
Document 2 with hello world → score: 3.0
Document 3 with hello world java → score: 4.5
Document 1 with hello → score: 1.5 * 1 / 3 = 0.5
Document 2 with hello world → score: 3.0 * 2 / 3 = 2.0
Document 3 with hello world java → score: 4.5 * 3 / 3 = 4.5
把计算出来的总分数 * 匹配上的term数量 / 总的term数量,让匹配不同term/query数量的doc,分数之间拉开差距
field level boost
可以将某个搜索条件的权重加大{
"match": {
"title": {
"query": "spark",
"boost": 5
}
}
} 