tensorflow笔记:多层CNN代码分析
tensorflow笔记系列:
(一) tensorflow笔记:流程,概念和简单代码注释
(二) tensorflow笔记:多层CNN代码分析
(三) tensorflow笔记:多层LSTM代码分析
(四) tensorflow笔记:常用函数说明
(五) tensorflow笔记:模型的保存与训练过程可视化
(六)tensorflow笔记:使用tf来实现word2vec
在之前的tensorflow笔记:流程,概念和简单代码注释 文章中,已经大概解释了tensorflow的大概运行流程,并且提供了一个mnist数据集分类器的简单实现。当然,因为结构简单,最后的准确率在91%左右。似乎已经不低了?其实这个成绩是非常不理想的。现在mnist的准确率天梯榜已经被刷到了99.5%以上。为了进一步提高准确率,官网还提供了一个多层的CNN分类器的代码。相比之前的一层神经网络,这份代码的主要看点倒不是多层,而是CNN,也就是卷积神经网络。
CNN的具体内容不再详述,概述可以参考这里,详细信息可以参见Convolutional Networks。一般来说,CNN网络的前几层为卷积层和采样层(或者说池化层),在若干层卷积和池化以后,还有若干层全连接层(也就是传统神经网络),最后输出分类信息。大概的结构示意图如下图所示
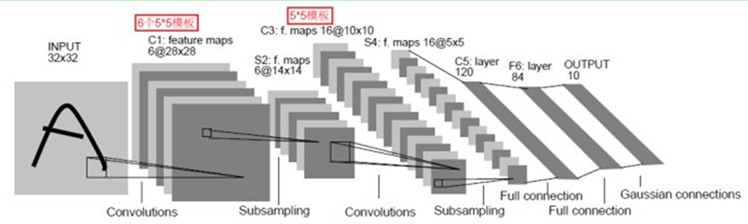
可以看到,CNN相比与传统神经网络,最大的区别就是引入了卷积层和池化层。这也是我们在代码中要着重看的地方。
在下面的代码中,卷积是使用tf.nn.conv2d, 池化使用tf.nn.max_pool,下面来详细的讲解一下这两个函数的用法。
tf.nn.conv2d
这个函数的功能是:给定4维的input和filter,计算出一个2维的卷积结果。函数的定义为:
def conv2d(input, filter, strides, padding, use_cudnn_on_gpu=None,
data_format=None, name=None):
前几个参数分别是input, filter, strides, padding, use_cudnn_on_gpu, …下面来一一解释
input:待卷积的数据。格式要求为一个张量,[batch, in_height, in_width, in_channels].
分别表示 批次数,图像高度,宽度,输入通道数。
filter: 卷积核。格式要求为[filter_height, filter_width, in_channels, out_channels].
分别表示 卷积核的高度,宽度,输入通道数,输出通道数。
strides :一个长为4的list. 表示每次卷积以后卷积窗口在input中滑动的距离
padding :有SAME和VALID两种选项,表示是否要保留图像边上那一圈不完全卷积的部分。如果是SAME,则保留
use_cudnn_on_gpu :是否使用cudnn加速。默认是True
tf.nn.max_pool
进行最大值池化操作,而avg_pool 则进行平均值池化操作.函数的定义为:
def max_pool(value, ksize, strides, padding, data_format="NHWC", name=None):
value: 一个4D张量,格式为[batch, height, width, channels],与conv2d中input格式一样
ksize: 长为4的list,表示池化窗口的尺寸
strides: 池化窗口的滑动值,与conv2d中的一样
padding: 与conv2d中用法一样。
具体的代码注释如下:
# Copyright 2015 The TensorFlow Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
"""A very simple MNIST classifier.
See extensive documentation at
http://tensorflow.org/tutorials/mnist/beginners/index.md
"""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
# Import data
from tensorflow.examples.tutorials.mnist import input_data
import tensorflow as tf
flags = tf.app.flags
FLAGS = flags.FLAGS
flags.DEFINE_string('data_dir', '/tmp/data/', 'Directory for storing data') # 第一次启动会下载文本资料,放在/tmp/data文件夹下
print(FLAGS.data_dir)
mnist = input_data.read_data_sets(FLAGS.data_dir, one_hot=True)
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1) # 变量的初始值为截断正太分布
return tf.Variable(initial)
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
def conv2d(x, W):
"""
tf.nn.conv2d功能:给定4维的input和filter,计算出一个2维的卷积结果
前几个参数分别是input, filter, strides, padding, use_cudnn_on_gpu, ...
input 的格式要求为一个张量,[batch, in_height, in_width, in_channels],批次数,图像高度,图像宽度,通道数
filter 的格式为[filter_height, filter_width, in_channels, out_channels],滤波器高度,宽度,输入通道数,输出通道数
strides 一个长为4的list. 表示每次卷积以后在input中滑动的距离
padding 有SAME和VALID两种选项,表示是否要保留不完全卷积的部分。如果是SAME,则保留
use_cudnn_on_gpu 是否使用cudnn加速。默认是True
"""
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
def max_pool_2x2(x):
"""
tf.nn.max_pool 进行最大值池化操作,而avg_pool 则进行平均值池化操作
几个参数分别是:value, ksize, strides, padding,
value: 一个4D张量,格式为[batch, height, width, channels],与conv2d中input格式一样
ksize: 长为4的list,表示池化窗口的尺寸
strides: 窗口的滑动值,与conv2d中的一样
padding: 与conv2d中用法一样。
"""
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1], padding='SAME')
sess = tf.InteractiveSession()
x = tf.placeholder(tf.float32, [None, 784])
x_image = tf.reshape(x, [-1,28,28,1]) #将输入按照 conv2d中input的格式来reshape,reshape
"""
# 第一层
# 卷积核(filter)的尺寸是5*5, 通道数为1,输出通道为32,即feature map 数目为32
# 又因为strides=[1,1,1,1] 所以单个通道的输出尺寸应该跟输入图像一样。即总的卷积输出应该为?*28*28*32
# 也就是单个通道输出为28*28,共有32个通道,共有?个批次
# 在池化阶段,ksize=[1,2,2,1] 那么卷积结果经过池化以后的结果,其尺寸应该是?*14*14*32
"""
W_conv1 = weight_variable([5, 5, 1, 32]) # 卷积是在每个5*5的patch中算出32个特征,分别是patch大小,输入通道数目,输出通道数目
b_conv1 = bias_variable([32])
h_conv1 = tf.nn.elu(conv2d(x_image, W_conv1) + b_conv1)
h_pool1 = max_pool_2x2(h_conv1)
"""
# 第二层
# 卷积核5*5,输入通道为32,输出通道为64。
# 卷积前图像的尺寸为 ?*14*14*32, 卷积后为?*14*14*64
# 池化后,输出的图像尺寸为?*7*7*64
"""
W_conv2 = weight_variable([5, 5, 32, 64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.elu(conv2d(h_pool1, W_conv2) + b_conv2)
h_pool2 = max_pool_2x2(h_conv2)
# 第三层 是个全连接层,输入维数7*7*64, 输出维数为1024
W_fc1 = weight_variable([7 * 7 * 64, 1024])
b_fc1 = bias_variable([1024])
h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64])
h_fc1 = tf.nn.elu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
keep_prob = tf.placeholder(tf.float32) # 这里使用了drop out,即随机安排一些cell输出值为0,可以防止过拟合
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
# 第四层,输入1024维,输出10维,也就是具体的0~9分类
W_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
y_conv=tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2) # 使用softmax作为多分类激活函数
y_ = tf.placeholder(tf.float32, [None, 10])
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y_conv), reduction_indices=[1])) # 损失函数,交叉熵
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy) # 使用adam优化
correct_prediction = tf.equal(tf.argmax(y_conv,1), tf.argmax(y_,1)) # 计算准确度
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
sess.run(tf.initialize_all_variables()) # 变量初始化
for i in range(20000):
batch = mnist.train.next_batch(50)
if i%100 == 0:
# print(batch[1].shape)
train_accuracy = accuracy.eval(feed_dict={
x:batch[0], y_: batch[1], keep_prob: 1.0})
print("step %d, training accuracy %g"%(i, train_accuracy))
train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5})
print("test accuracy %g"%accuracy.eval(feed_dict={
x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0}))
 浙公网安备 33010602011771号
浙公网安备 33010602011771号