


Zookeeper的Watcher 机制的实现原理
事件机制:
Watcher 监听机制是 Zookeeper 中非常重要的特性,我们基于 zookeeper 上创建的节点,可以对这些节点绑定监听事件,比如可以监听节点数据变更、节点删除、子节点状态变更等事件,通过这个事件机制,可以基于 zookeeper实现分布式锁、集群管理等功能。
watcher 特性:当数据发生变化的时候, zookeeper 会产生一个 watcher 事件,并且会发送到客户端。但是客户端只会收到一次通知。如果后续这个节点再次发生变化,那么之前设置 watcher 的客户端不会再次收到消息。(watcher 是一次性的操作)。 可以通过循环监听去达到永久监听效果。
如何注册事件机制:
ZooKeeper 的 Watcher 机制,总的来说可以分为三个过程:客户端注册 Watcher、服务器处理 Watcher 和客户端回调 Watcher客户端。注册 watcher 有 3 种方式,getData、exists、getChildren;以如下代码为例
如何触发事件? 凡是事务类型的操作,都会触发监听事件。create /delete /setData,来看以下代码简单实现

public class WatcherDemo {
public static void main(String[] args) throws IOException, InterruptedException, KeeperException {
final CountDownLatch countDownLatch=new CountDownLatch(1);
final ZooKeeper zooKeeper=
new ZooKeeper("192.168.254.135:2181," +
"192.168.254.136:2181,192.168.254.137:2181",
4000, new Watcher() {
@Override
public void process(WatchedEvent event) {
System.out.println("默认事件: "+event.getType());
if(Event.KeeperState.SyncConnected==event.getState()){
//如果收到了服务端的响应事件,连接成功
countDownLatch.countDown();
}
}
});
countDownLatch.await();
zooKeeper.create("/zk-wuzz","1".getBytes(),
ZooDefs.Ids.OPEN_ACL_UNSAFE,CreateMode.PERSISTENT);
//exists getdata getchildren
//通过exists绑定事件
Stat stat=zooKeeper.exists("/zk-wuzz", new Watcher() {
@Override
public void process(WatchedEvent event) {
System.out.println(event.getType()+"->"+event.getPath());
try {
//再一次去绑定事件 ,但是这个走的是默认事件
zooKeeper.exists(event.getPath(),true);
} catch (KeeperException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
//通过修改的事务类型操作来触发监听事件
stat=zooKeeper.setData("/zk-wuzz","2".getBytes(),stat.getVersion());
Thread.sleep(1000);
zooKeeper.delete("/zk-wuzz",stat.getVersion());
System.in.read();
}
}
以上就是 Watcher 的简单实现操作。接下来浅析一下这个 Watcher 实现的流程。
watcher 事件类型:
//org.apache.zookeeper.Watcher.Event.EventType enum EventType { None(-1), // 客户端连接状态变化 NodeCreated(1), // 节点创建 NodeDeleted(2), // 节点删除 NodeDataChanged(3), // 节点数据变化 NodeChildrenChanged(4), // 子节点变化 DataWatchRemoved(5), // 事件移除 ChildWatchRemoved(6), // 子节点事件移除 PersistentWatchRemoved (7); // 持久化监听移除 //..... }
事件的实现原理:
client 端连接后会注册一个事件,然后客户端会保存这个事件,通过zkWatcherManager 保存客户端的事件注册,通知服务端 Watcher 为 true,然后服务端会通过WahcerManager 会绑定path对应的事件。如下图:
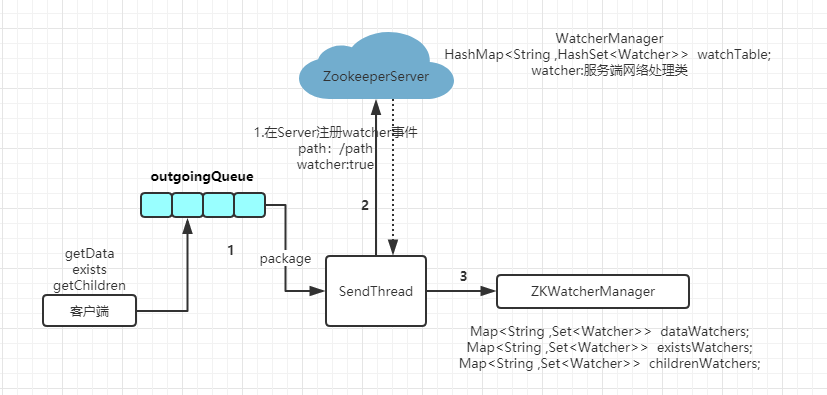
请求发送:
基于 zookeeper 源码 3.6.3 版本分析。
接下去通过源码层面去熟悉一下这个 Watcher 的流程。由于我们demo 是通过exists 来注册事件,那么我们就通过 exists 来作为入口。先来看看ZooKeeper API 的初始化过程:
public ZooKeeper(String connectString,int sessionTimeout,Watcher watcher,boolean canBeReadOnly,HostProvider aHostProvider,ZKClientConfig clientConfig) throws IOException { LOG.info( "Initiating client connection, connectString={} sessionTimeout={} watcher={}", connectString, sessionTimeout, watcher); if (clientConfig == null) { clientConfig = new ZKClientConfig(); } this.clientConfig = clientConfig; watchManager = defaultWatchManager(); //--在这里将 watcher 设置到ZKWatchManager watchManager.defaultWatcher = watcher; ConnectStringParser connectStringParser = new ConnectStringParser(connectString); hostProvider = aHostProvider; //初始化了 ClientCnxn,并且调用 cnxn.start()方法 cnxn = createConnection(connectStringParser.getChrootPath(),hostProvider,sessionTimeout,this,watchManager,getClientCnxnSocket(),canBeReadOnly); cnxn.start(); }
createConnection ,初始化一个ClientCnxn。在创建一个 ZooKeeper 客户端对象实例时,我们通过 new Watcher()向构造方法中传入一个默认的 Watcher, 这个 Watcher 将作为整个 ZooKeeper 会话期间的默认Watcher,会一直被保存在客户端 ZKWatchManager 的 defaultWatcher 中.其中初始化了 ClientCnxn并且调用了其start 方法:
public ClientCnxn( String chrootPath, HostProvider hostProvider, int sessionTimeout, ZooKeeper zooKeeper, ClientWatchManager watcher, ClientCnxnSocket clientCnxnSocket, long sessionId, byte[] sessionPasswd, boolean canBeReadOnly) throws IOException { this.zooKeeper = zooKeeper; this.watcher = watcher; this.sessionId = sessionId; this.sessionPasswd = sessionPasswd; this.sessionTimeout = sessionTimeout;//会话超时时间 this.hostProvider = hostProvider; this.chrootPath = chrootPath; connectTimeout = sessionTimeout / hostProvider.size(); readTimeout = sessionTimeout * 2 / 3; 超时时间 readOnly = canBeReadOnly; //初始化一个sendThread sendThread = new SendThread(clientCnxnSocket); //初始化一个EventThread、用于事件触发处理 eventThread = new EventThread(); this.clientConfig = zooKeeper.getClientConfig(); initRequestTimeout(); } //启动两个线程 public void start() { sendThread.start(); eventThread.start(); }
ClientCnxn:是 Zookeeper 客户端和 Zookeeper 服务器端进行通信和事件通知处理的主要类,它内部包含两个类,
- SendThread :负责客户端和服务器端的数据通信, 也包括事件信息的传输
- EventThread : 主要在客户端回调注册的 Watchers 进行通知处理
接下去就是我们通过getData、exists、getChildren 注册事件的过程了,以exists为例:
public Stat exists(final String path, Watcher watcher)
throws KeeperException, InterruptedException
{
final String clientPath = path;
PathUtils.validatePath(clientPath);
// 这个很关键,执行回调的时候会用到
WatchRegistration wcb = null;
if (watcher != null) {//不为空,将进行包装
wcb = new ExistsWatchRegistration(watcher, clientPath);
}
final String serverPath = prependChroot(clientPath);
//类似手写RPC中的一个请求类request
//在这里 requesr就封装了两个东西 1.ZooDefs.OpCode.exists
//还有一个是watch ->true
RequestHeader h = new RequestHeader();
h.setType(ZooDefs.OpCode.exists);
ExistsRequest request = new ExistsRequest();
request.setPath(serverPath);
request.setWatch(watcher != null);
SetDataResponse response = new SetDataResponse();
//通过客户端的网络处理类去提交请求
ReplyHeader r = cnxn.submitRequest(h, request, response, wcb);
if (r.getErr() != 0) {
if (r.getErr() == KeeperException.Code.NONODE.intValue()) {
return null;
}
throw KeeperException.create(KeeperException.Code.get(r.getErr()),
clientPath);
}
return response.getStat().getCzxid() == -1 ? null : response.getStat();
}
其实这个方法内就做了两件事,初始化了ExistsWatchRegistration 以及封装了一个网络请求参数 ExistsRequest,接着通过 cnxn.submitRequest 发送请求:
public ReplyHeader submitRequest(RequestHeader h, Record request,
Record response, WatchRegistration watchRegistration)
throws InterruptedException {
ReplyHeader r = new ReplyHeader();//应答消息头
//组装请求入队
Packet packet = queuePacket(h, r, request, response, null, null, null,
null, watchRegistration);
//等待请求完成。否则阻塞
synchronized (packet) {
while (!packet.finished) {
packet.wait();
}
}
return r;
}
这里验证了我们之前流程图中对于请求进行封包都过程,紧接着会调用wait进入阻塞,一直的等待整个请求处理完毕,我们跟进 queuePacket:
public Packet queuePacket(RequestHeader h, ReplyHeader r, Record request,Record response,AsyncCallback cb, String clientPath,String serverPath,Object ctx, WatchRegistration watchRegistration, WatchDeregistration watchDeregistration) { Packet packet = null; // Note that we do not generate the Xid for the packet yet. It is // generated later at send-time, by an implementation of ClientCnxnSocket::doIO(), // where the packet is actually sent. packet = new Packet(h, r, request, response, watchRegistration); packet.cb = cb; packet.ctx = ctx; packet.clientPath = clientPath; packet.serverPath = serverPath; packet.watchDeregistration = watchDeregistration; // The synchronized block here is for two purpose: // 1. synchronize with the final cleanup() in SendThread.run() to avoid race // 2. synchronized against each packet. So if a closeSession packet is added, // later packet will be notified. // 1.与SendThread.run()中的最终cleanup()同步以避免竞争 // 2.针对每个数据包进行同步。 因此,如果添加了closeSession数据包,则将通知以后的数据包。 synchronized (state) { if (!state.isAlive() || closing) { conLossPacket(packet); } else { // If the client is asking to close the session then // mark as closing if (h.getType() == OpCode.closeSession) { closing = true; } outgoingQueue.add(packet); //添加到outgoingQueue,这里很显然又是一个生产者消费者模式。 } } //唤醒阻塞在selector.select上的线程 sendThread.getClientCnxnSocket().packetAdded(); return packet; }
这里加了个同步锁以避免并发问题,封装了一个 Packet 并将其加入到一个阻塞队列 outgoingQueue 中,最后调用 sendThread.getClientCnxnSocket().wakeupCnxn() 唤醒selector。看到这里,发现只是发送了数据,那哪里触发了对 outgoingQueue 队列的消息进行消费。再把组装的packeet 放入队列的时候用到的 cnxn.submitRequest(h, request, response, wcb);这个cnxn 是哪里来的呢? 在 zookeeper的构造函数中,我们初始化了一个ClientCnxn并且启动了两个线程:
public void start() {
sendThread.start();
eventThread.start();
}
对于当前场景来说,目前是需要将封装好的数据包发送出去,很显然走的是 SendThread,我们进入他的 Run 方法:
public void run() { clientCnxnSocket.introduce(this, sessionId, outgoingQueue); clientCnxnSocket.updateNow(); clientCnxnSocket.updateLastSendAndHeard(); int to; long lastPingRwServer = Time.currentElapsedTime(); final int MAX_SEND_PING_INTERVAL = 10000; //10 seconds InetSocketAddress serverAddress = null; while (state.isAlive()) {//如果是存活状态 try { if (!clientCnxnSocket.isConnected()) {//如果不是连接状态,则需要进行连接的建立 // don't re-establish connection if we are closing if (closing) { break; } if (rwServerAddress != null) { serverAddress = rwServerAddress; rwServerAddress = null; } else { serverAddress = hostProvider.next(1000); } onConnecting(serverAddress); startConnect(serverAddress);//开启连接 clientCnxnSocket.updateLastSendAndHeard(); } if (state.isConnected()) {//如果连接是正常状态 // determine whether we need to send an AuthFailed event. if (zooKeeperSaslClient != null) { //是否是ssl连接 //省略。。。。。 } else { to = connectTimeout - clientCnxnSocket.getIdleRecv(); } if (to <= 0) {//会话是否超时 String warnInfo = String.format( "Client session timed out, have not heard from server in %dms for session id 0x%s", clientCnxnSocket.getIdleRecv(), Long.toHexString(sessionId)); LOG.warn(warnInfo); throw new SessionTimeoutException(warnInfo); } if (state.isConnected()) { //1000(1 second) is to prevent race condition missing to send the second ping //also make sure not to send too many pings when readTimeout is small int timeToNextPing = readTimeout / 2 - clientCnxnSocket.getIdleSend() - ((clientCnxnSocket.getIdleSend() > 1000) ? 1000 : 0); //send a ping request either time is due or no packet sent out within MAX_SEND_PING_INTERVAL //发送ping请求 if (timeToNextPing <= 0 || clientCnxnSocket.getIdleSend() > MAX_SEND_PING_INTERVAL) { sendPing(); clientCnxnSocket.updateLastSend(); } else { if (timeToNextPing < to) { to = timeToNextPing; } } } // If we are in read-only mode, seek for read/write server // 是否是只读请求连接状态 if (state == States.CONNECTEDREADONLY) { long now = Time.currentElapsedTime(); int idlePingRwServer = (int) (now - lastPingRwServer); if (idlePingRwServer >= pingRwTimeout) { lastPingRwServer = now; idlePingRwServer = 0; pingRwTimeout = Math.min(2 * pingRwTimeout, maxPingRwTimeout); pingRwServer(); } to = Math.min(to, pingRwTimeout - idlePingRwServer); } //这里就是核心的处理逻辑,真正进行网络传输; //pendingQueue表示已经发送出去的数据需要等待server返回的packet队列 //outgoingQueue是等待发送出去的packet队列 clientCnxnSocket.doTransport(to, pendingQueue, ClientCnxn.this); } // 省略部分代码。。。。。。 }
这一步大部分的逻辑是进行校验判断连接状态,以及相关心跳维持得操作,最后会走 clientCnxnSocket.doTransport :
void doTransport( int waitTimeOut, Queue<Packet> pendingQueue, ClientCnxn cnxn) throws IOException, InterruptedException { selector.select(waitTimeOut); Set<SelectionKey> selected; synchronized (this) {//获取selectedKeys selected = selector.selectedKeys(); } // Everything below and until we get back to the select is // non blocking, so time is effectively a constant. That is // Why we just have to do this once, here updateNow(); for (SelectionKey k : selected) { SocketChannel sc = ((SocketChannel) k.channel()); // readyOps :获取此键上ready操作集合.即在当前通道上已经就绪的事件 // SelectKey.OP_CONNECT 连接就绪事件,表示客户与服务器的连接已经建立成功 // 两者的与计算不等于0 //如果是连接事件,暂时忽略 if ((k.readyOps() & SelectionKey.OP_CONNECT) != 0) { if (sc.finishConnect()) { updateLastSendAndHeard(); updateSocketAddresses(); sendThread.primeConnection(); } } else if ((k.readyOps() & (SelectionKey.OP_READ | SelectionKey.OP_WRITE)) != 0) { doIO(pendingQueue, cnxn);//如果是读写事件,则调用doIO进行传输 } } if (sendThread.getZkState().isConnected()) { if (findSendablePacket(outgoingQueue, sendThread.tunnelAuthInProgress()) != null) { enableWrite(); } } selected.clear(); }
这里的代码相信很多小伙伴都不会很陌生,是 Java NIO相关操作的API,对于当前场景,这里我们是走 SelectionKey.OP_WRITE ,即 doIO(pendingQueue, outgoingQueue, cnxn) :
void doIO(Queue<Packet> pendingQueue, ClientCnxn cnxn) throws InterruptedException, IOException { SocketChannel sock = (SocketChannel) sockKey.channel(); if (sock == null) { throw new IOException("Socket is null!"); } //省略 读事件相关代码。。。。。 //如果是写请求 if (sockKey.isWritable()) { //找到可以发送的packet Packet p = findSendablePacket(outgoingQueue, sendThread.tunnelAuthInProgress()); //如果Packet的byteBuffer没有创建,那么就创建 if (p != null) { updateLastSend(); // If we already started writing p, p.bb will already exist if (p.bb == null) { if ((p.requestHeader != null) && (p.requestHeader.getType() != OpCode.ping) && (p.requestHeader.getType() != OpCode.auth)) { p.requestHeader.setXid(cnxn.getXid()); } p.createBB(); } sock.write(p.bb); // 发送数据包 if (!p.bb.hasRemaining()) { sentCount.getAndIncrement(); outgoingQueue.removeFirstOccurrence(p);;//从待发送队列中移除 if (p.requestHeader != null//判断数据包的请求,ping以及auth不加入待回复队列 && p.requestHeader.getType() != OpCode.ping && p.requestHeader.getType() != OpCode.auth) { synchronized (pendingQueue) { pendingQueue.add(p);//添加到pendingQueue待回复队列 } } } } if (outgoingQueue.isEmpty()) { // No more packets to send: turn off write interest flag. // Will be turned on later by a later call to enableWrite(), // from within ZooKeeperSaslClient (if client is configured // to attempt SASL authentication), or in either doIO() or // in doTransport() if not. disableWrite(); } else if (!initialized && p != null && !p.bb.hasRemaining()) { // On initial connection, write the complete connect request // packet, but then disable further writes until after // receiving a successful connection response. If the // session is expired, then the server sends the expiration // response and immediately closes its end of the socket. If // the client is simultaneously writing on its end, then the // TCP stack may choose to abort with RST, in which case the // client would never receive the session expired event. See // http://docs.oracle.com/javase/6/docs/technotes/guides/net/articles/connection_release.html disableWrite(); } else { // Just in case enableWrite(); } } }
默认序列化框架:jute.至此就将当前都操作发送至服务器端,当服务器端接收到请求进行下一步的处理。
到目前为止,我们已经分析了客户端请求的发送流程,我们来画一个简单的流程图梳理一下
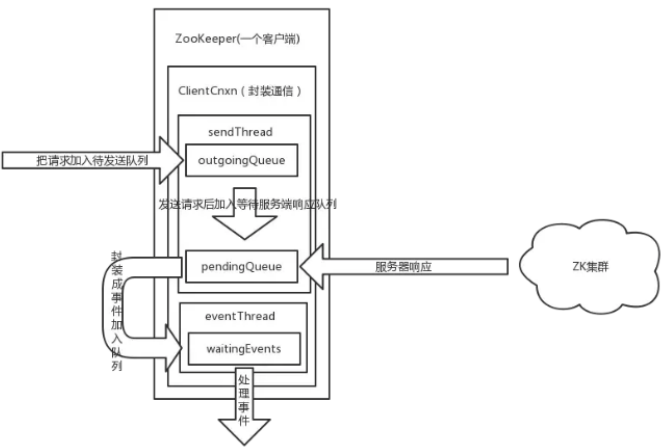
服务端接收请求处理流程:
服务端有一个 NIOServerCnxn 类,在服务器端初始化的时候,在QuorumPeerMain.runFromConfig方法中:
ServerCnxnFactory cnxnFactory = ServerCnxnFactory.createFactory();
这里创建的 cnxnFactory 就是服务器端的网络请求处理类工厂对象,即 NIOServerCnxnFactory ,并且,在QuorumPeer.start()->startServerCnxnFactory()->cnxnFactory.start(); 中,启动了一个 acceptThread线程,这个线程从名字上看,应该是用来处理客户端的来请求,我们跟进去看看:
public void run() { try { while (!stopped && !acceptSocket.socket().isClosed()) { try { select(); } catch (RuntimeException e) { LOG.warn("Ignoring unexpected runtime exception", e); } catch (Exception e) { LOG.warn("Ignoring unexpected exception", e); } } } finally { closeSelector(); // This will wake up the selector threads, and tell the // worker thread pool to begin shutdown. if (!reconfiguring) { NIOServerCnxnFactory.this.stop(); } LOG.info("accept thread exitted run method"); } }
在run方法中,调用了select()方法,select方法中,会通过复路器Selector,去进行select操作,获取就绪的连接。其中select这个方法中主 要做的事情是
- 遍历所有的就绪连接,进行连接的判断
- 调用doAccept方法进行处理
private boolean doAccept() {//这里用来处理客户端连接事件 boolean accepted = false; SocketChannel sc = null; try { sc = acceptSocket.accept();//获得客户端连接 accepted = true; //是否超过最大连接 if (limitTotalNumberOfCnxns()) { throw new IOException("Too many connections max allowed is " + maxCnxns); } InetAddress ia = sc.socket().getInetAddress(); int cnxncount = getClientCnxnCount(ia); if (maxClientCnxns > 0 && cnxncount >= maxClientCnxns) { throw new IOException("Too many connections from " + ia + " - max is " + maxClientCnxns); } LOG.debug("Accepted socket connection from {}", sc.socket().getRemoteSocketAddress()); sc.configureBlocking(false);//设置非阻塞 // Round-robin assign this connection to a selector thread // 轮询,将当前连接分配给选择器线程 if (!selectorIterator.hasNext()) { selectorIterator = selectorThreads.iterator(); } SelectorThread selectorThread = selectorIterator.next(); //把当前连接再丢给SelectorThread来处理。 if (!selectorThread.addAcceptedConnection(sc)) { throw new IOException("Unable to add connection to selector queue" + (stopped ? " (shutdown in progress)" : "")); } acceptErrorLogger.flush(); } catch (IOException e) { // accept, maxClientCnxns, configureBlocking ServerMetrics.getMetrics().CONNECTION_REJECTED.add(1); acceptErrorLogger.rateLimitLog("Error accepting new connection: " + e.getMessage()); fastCloseSock(sc); } return accepted; }
把当前客户端连接丢到acceptedQueue这个阻塞队列中。
public boolean addAcceptedConnection(SocketChannel accepted) { if (stopped || !acceptedQueue.offer(accepted)) { //添加到接收队列,后续会为该连接注册读写事件 return false; } wakeupSelector();//唤醒阻塞在selector.select上的线程 return true; }
SelectorThread.run :由于在doAccept方法中,已经把客户端的连接交给了SelectorThread,所以我们去这个线程的run方法 中看看处理逻辑
public void run() { //这里用来处理读写请求事件 try { while (!stopped) { try { select();//处理多路复用 processAcceptedConnections();//处理连接请求 processInterestOpsUpdateRequests(); //注册一个更新请求 } catch (RuntimeException e) { LOG.warn("Ignoring unexpected runtime exception", e); } catch (Exception e) { LOG.warn("Ignoring unexpected exception", e); } } // Close connections still pending on the selector. Any others // with in-flight work, let drain out of the work queue. for (SelectionKey key : selector.keys()) { NIOServerCnxn cnxn = (NIOServerCnxn) key.attachment(); if (cnxn.isSelectable()) { cnxn.close(ServerCnxn.DisconnectReason.SERVER_SHUTDOWN); } cleanupSelectionKey(key); } SocketChannel accepted; while ((accepted = acceptedQueue.poll()) != null) { fastCloseSock(accepted); } updateQueue.clear(); } finally { closeSelector(); // This will wake up the accept thread and the other selector // threads, and tell the worker thread pool to begin shutdown. NIOServerCnxnFactory.this.stop(); LOG.info("selector thread exitted run method"); } }
从selector中获取就绪的连接,针对读写事件,调用handleIO方法进行处理。
private void select() { try { selector.select(); Set<SelectionKey> selected = selector.selectedKeys(); ArrayList<SelectionKey> selectedList = new ArrayList<SelectionKey>(selected); Collections.shuffle(selectedList); Iterator<SelectionKey> selectedKeys = selectedList.iterator(); while (!stopped && selectedKeys.hasNext()) { SelectionKey key = selectedKeys.next(); selected.remove(key); if (!key.isValid()) { cleanupSelectionKey(key); continue; } if (key.isReadable() || key.isWritable()) { handleIO(key); } else { LOG.warn("Unexpected ops in select {}", key.readyOps()); } } } catch (IOException e) { LOG.warn("Ignoring IOException while selecting", e); } }
doIO
- 构建一个IOWorkRequest
- 把这个请求丢给workerPool来处理
private void handleIO(SelectionKey key) { IOWorkRequest workRequest = new IOWorkRequest(this, key); NIOServerCnxn cnxn = (NIOServerCnxn) key.attachment(); // Stop selecting this key while processing on its // connection cnxn.disableSelectable(); key.interestOps(0); touchCnxn(cnxn); workerPool.schedule(workRequest); }
ZookeeperServer.processPacket :
通过N个异步化处理过程,最终进入到 ZookeeperServer.processPacket 调用链路:
WorkerService.schedule -> ScheduledWorkRequest.run -> IOWorkRequest.doWork - > NIOServerCnxn.doIO -> readPayload- > readRequest -> processPacket 这个方法根据数据包的类型来处理不同的数据包,对于读写请求,我们主要关注下面这块代码即可
public void processPacket(ServerCnxn cnxn, ByteBuffer incomingBuffer) throws IOException { // We have the request, now process and setup for next InputStream bais = new ByteBufferInputStream(incomingBuffer); BinaryInputArchive bia = BinaryInputArchive.getArchive(bais); RequestHeader h = new RequestHeader(); h.deserialize(bia, "header"); cnxn.incrOutstandingAndCheckThrottle(h); incomingBuffer = incomingBuffer.slice(); if (h.getType() == OpCode.auth) { // 省略代码。。。。 } else {// 由于exists方法一开始设置了 h.setType(ZooDefs.OpCode.exists);所以走这个流程 if (shouldRequireClientSaslAuth() && !hasCnxSASLAuthenticated(cnxn)) { ReplyHeader replyHeader = new ReplyHeader(h.getXid(), 0, Code.SESSIONCLOSEDREQUIRESASLAUTH.intValue()); cnxn.sendResponse(replyHeader, null, "response"); cnxn.sendCloseSession(); cnxn.disableRecv(); } else { Request si = new Request(cnxn, cnxn.getSessionId(), h.getXid(), h.getType(), incomingBuffer, cnxn.getAuthInfo()); int length = incomingBuffer.limit(); if (isLargeRequest(length)) { // checkRequestSize will throw IOException if request is rejected checkRequestSizeWhenMessageReceived(length); si.setLargeRequestSize(length); } si.setOwner(ServerCnxn.me); //sumitReuqest方法实际就是把 任务添加到阻塞队列。 submitRequest(si); } } }
ZookeeperServer.submitRequest 将请求添加到RequestThrottler(限流器)中去处理,它是一个线程,而sumitReuqest方法实际就是把 任务添加到阻塞队列。
public void submitRequest(Request request) { if (stopping) { LOG.debug("Shutdown in progress. Request cannot be processed"); dropRequest(request); } else { submittedRequests.add(request); } }
RequestThrottler.run 在RequestThrottler的run 方法中,会从阻塞队列中取出任务进行处理。
public void run() { try { while (true) { if (killed) { break; } //从阻塞队列中获取任务 Request request = submittedRequests.take(); if (Request.requestOfDeath == request) { break; } if (request.mustDrop()) { continue; } // 当maxRequests=0时,节流阀处于关闭状态 // Throttling is disabled when maxRequests = 0 if (maxRequests > 0) { while (!killed) { if (dropStaleRequests && request.isStale()) { // Note: this will close the connection dropRequest(request); ServerMetrics.getMetrics().STALE_REQUESTS_DROPPED.add(1); request = null; break; }// 只要没达到最大限制,直接通过 if (zks.getInProcess() < maxRequests) { break; }//否则会等待一段时间继续再处理 throttleSleep(stallTime); } } if (killed) { break; } // 如果请求不为空,则处理请求 // A dropped stale request will be null if (request != null) { if (request.isStale()) { ServerMetrics.getMetrics().STALE_REQUESTS.add(1); }// 验证通过后,提交给 zkServer 处理 zks.submitRequestNow(request); } } } catch (InterruptedException e) { LOG.error("Unexpected interruption", e); } int dropped = drainQueue(); LOG.info("RequestThrottler shutdown. Dropped {} requests", dropped); }
ZookeeperServer.submitRequestNow 提交请求,这里面涉及到一个firstProcessor. 这个是一个责任链模式,如果当前请求发到了Leader服务器
firstProcessor请求链组成 :firstProcessor的初始化是在ZookeeperServer的setupRequestProcessor中完成的,代码如下
这里到了服务端的处理链都流程了,首先我们需要知道这个处理链是哪里初始化的呢?我们需要知道在整个调用链过程中采用的是责任链都设计模式,其中在ZK中每种角色以及部署方式都有其独特的调用链,我们先来看一下他是在哪里初始化的,在本类(ZookeeperServer)中搜索到如下方法:
protected void setupRequestProcessors() { RequestProcessor finalProcessor = new FinalRequestProcessor(this); RequestProcessor syncProcessor = new SyncRequestProcessor(this, finalProcessor); ((SyncRequestProcessor) syncProcessor).start(); firstProcessor = new PrepRequestProcessor(this, syncProcessor); ((PrepRequestProcessor) firstProcessor).start(); } public synchronized void startup() { startupWithServerState(State.RUNNING); } private void startupWithServerState(State state) { if (sessionTracker == null) { createSessionTracker(); } startSessionTracker(); setupRequestProcessors(); startRequestThrottler(); registerJMX(); startJvmPauseMonitor(); registerMetrics(); setState(state); requestPathMetricsCollector.start(); localSessionEnabled = sessionTracker.isLocalSessionsEnabled(); notifyAll(); }
从代码中可以看出在 setupRequestProcessors初始化了该链路,其中由 startup() 进入初始化,而这个startup在我们跟leader选举的时候,服务端初始化中在 QuorumPeer 类中的Run方法中有调到,可以跟单机版的流程看一下,针对不同的角色,这里有五种不同的实现

我们来看看每种不同角色的调用链:standalone,单机部署:
protected void setupRequestProcessors() {
// PrepRequestProcessor -> SyncRequestProcessor-> FinalRequestProcessor
RequestProcessor finalProcessor = new FinalRequestProcessor(this);
RequestProcessor syncProcessor = new SyncRequestProcessor(this,
finalProcessor);
((SyncRequestProcessor)syncProcessor).start();
firstProcessor = new PrepRequestProcessor(this, syncProcessor);
((PrepRequestProcessor)firstProcessor).start();
}
集群部署 Leader :
protected void setupRequestProcessors() { // PrepRequestProcessor->ProposalRequestProcessor -> CommitProcessor // -> ToBeAppliedRequestProcessor ->FinalRequestProcessor RequestProcessor finalProcessor = new FinalRequestProcessor(this); RequestProcessor toBeAppliedProcessor = new Leader.ToBeAppliedRequestProcessor(finalProcessor, getLeader()); commitProcessor = new CommitProcessor(toBeAppliedProcessor, Long.toString(getServerId()), false, getZooKeeperServerListener()); commitProcessor.start();//提交提案 ProposalRequestProcessor proposalProcessor = new ProposalRequestProcessor(this, commitProcessor); proposalProcessor.initialize();//事务 prepRequestProcessor = new PrepRequestProcessor(this, proposalProcessor); prepRequestProcessor.start(); firstProcessor = new LeaderRequestProcessor(this, prepRequestProcessor); setupContainerManager(); }
集群部署 Follower:
protected void setupRequestProcessors() {
// FollowerRequestProcessor->CommitProcessor ->FinalRequestProcessor
RequestProcessor finalProcessor = new FinalRequestProcessor(this);
commitProcessor = new CommitProcessor(finalProcessor,
Long.toString(getServerId()), true,
getZooKeeperServerListener());
commitProcessor.start();
firstProcessor = new FollowerRequestProcessor(this, commitProcessor);
((FollowerRequestProcessor) firstProcessor).start();
//同步应答相关
syncProcessor = new SyncRequestProcessor(this,
new SendAckRequestProcessor((Learner)getFollower()));
syncProcessor.start();
}
集群部署 Observer:
protected void setupRequestProcessors() {
RequestProcessor finalProcessor = new FinalRequestProcessor(this);
commitProcessor = new CommitProcessor(finalProcessor,
Long.toString(getServerId()), true,
getZooKeeperServerListener());
commitProcessor.start();
firstProcessor = new ObserverRequestProcessor(this, commitProcessor);
((ObserverRequestProcessor) firstProcessor).start();
if (syncRequestProcessorEnabled) {
syncProcessor = new SyncRequestProcessor(this, null);
syncProcessor.start();
}
}
这里 setupRequestProcessors 方法,对于不同的集群角色都有相对应都类去重写该方法,我们这里以单机部署的流程去处理对应流程:回到刚刚 submitRequest 方法中:
public void submitRequest(Request si) { //firstProcessor不可能是null try { touch(si.cnxn); boolean validpacket = Request.isValid(si.type); if (validpacket) { setLocalSessionFlag(si); firstProcessor.processRequest(si); if (si.cnxn != null) { incInProcess(); } //....... }
我们根据单机版的调用链的顺序:PrepRequestProcessor -> SyncRequestProcessor-> FinalRequestProcessor。而这3个处理器的主要功能如下:
- PrepRequestProcessor:此请求处理器通常位于RequestProcessor的开头,等等可以看到,就exsits对应就一个Session的检查
- SyncRequestProcessor:此RequestProcessor将请求记录到磁盘。简单来说就是持久化的处理器
- FinalRequestProcessor:此请求处理程序实际应用与请求关联的任何事务,并为任何查询提供服务
首先进入PrepRequestProcessor.processRequest:
public void processRequest(Request request) { request.prepQueueStartTime = Time.currentElapsedTime(); submittedRequests.add(request); ServerMetrics.getMetrics().PREP_PROCESSOR_QUEUED.add(1); }
很奇怪,processRequest 只是把 request 添加到submittedRequests中,根据前面的经验,很自然的想到这里又是一个异步操作。而submittedRequests又是一个阻塞队列LinkedBlockingQueue submittedRequests = new LinkedBlockingQueue();而 PrepRequestProcessor 这个类又继承了线程类,因此我们直接找到当前类中的方法如下:
public void run() { LOG.info(String.format("PrepRequestProcessor (sid:%d) started, reconfigEnabled=%s", zks.getServerId(), zks.reconfigEnabled)); try { while (true) { ServerMetrics.getMetrics().PREP_PROCESSOR_QUEUE_SIZE.add(submittedRequests.size()); //从阻塞队列中获取请求 Request request = submittedRequests.take(); ServerMetrics.getMetrics().PREP_PROCESSOR_QUEUE_TIME .add(Time.currentElapsedTime() - request.prepQueueStartTime); long traceMask = ZooTrace.CLIENT_REQUEST_TRACE_MASK; if (request.type == OpCode.ping) { traceMask = ZooTrace.CLIENT_PING_TRACE_MASK; } if (LOG.isTraceEnabled()) { ZooTrace.logRequest(LOG, traceMask, 'P', request, ""); } if (Request.requestOfDeath == request) { break; } request.prepStartTime = Time.currentElapsedTime(); //预处理 pRequest(request); } } catch (Exception e) { handleException(this.getName(), e); } LOG.info("PrepRequestProcessor exited loop!"); } protected void pRequest(Request request) throws RequestProcessorException { // LOG.info("Prep>>> cxid = " + request.cxid + " type = " + // request.type + " id = 0x" + Long.toHexString(request.sessionId)); request.setHdr(null); request.setTxn(null); try { switch (request.type) { //省略代码。。。。。 case OpCode.sync: case OpCode.exists://根据我们这个案例会走这个分支 case OpCode.getData: case OpCode.getACL: case OpCode.getChildren: case OpCode.getAllChildrenNumber: case OpCode.getChildren2: case OpCode.ping: case OpCode.setWatches: case OpCode.setWatches2: case OpCode.checkWatches: case OpCode.removeWatches: case OpCode.getEphemerals: case OpCode.multiRead: case OpCode.addWatch: zks.sessionTracker.checkSession(request.sessionId, request.getOwner()); break; default: LOG.warn("unknown type {}", request.type); break; } } catch (KeeperException e) { if (request.getHdr() != null) { request.getHdr().setType(OpCode.error); request.setTxn(new ErrorTxn(e.code().intValue())); } if (e.code().intValue() > Code.APIERROR.intValue()) { LOG.info( "Got user-level KeeperException when processing {} Error Path:{} Error:{}", request.toString(), e.getPath(), e.getMessage()); } request.setException(e); } catch (Exception e) { //...省略 } request.zxid = zks.getZxid(); ServerMetrics.getMetrics().PREP_PROCESS_TIME.add(Time.currentElapsedTime() - request.prepStartTime); nextProcessor.processRequest(request); }
这里通过判断请求的类型进而调用处理,而在本场景中 case OpCode.exists: 会走检查 Session 而没有做其他操作,进而进入下一个调用链 SyncRequestProcessor.processRequest:
SyncRequestProcessor.processRequest 这个 processor负责把写request持久化到本地磁盘,为了提高写磁盘的效率,这里使用的是缓冲写, 但是会周期性(1000个request)的调用flush操作,flush之后request已经确保写到磁盘了. 同时他还要维护本机的txnlog和snapshot,这里的基本逻辑是:
每隔snapCount/2个request会重新生成一个snapshot并滚动一次txnlog,同时为了避免所有的 zookeeper server在同一个时间生成snapshot和滚动日志,这里会再加上一个随机数,snapCount 的默认值是10w个request
public void processRequest(final Request request) { Objects.requireNonNull(request, "Request cannot be null"); request.syncQueueStartTime = Time.currentElapsedTime(); queuedRequests.add(request); ServerMetrics.getMetrics().SYNC_PROCESSOR_QUEUED.add(1); }
又是一样的套路,进入其 Run方法:
public void run() { try { // we do this in an attempt to ensure that not all of the servers // in the ensemble take a snapshot at the same time resetSnapshotStats(); lastFlushTime = Time.currentElapsedTime(); while (true) { ServerMetrics.getMetrics().SYNC_PROCESSOR_QUEUE_SIZE.add(queuedRequests.size()); long pollTime = Math.min(zks.getMaxWriteQueuePollTime(), getRemainingDelay()); Request si = queuedRequests.poll(pollTime, TimeUnit.MILLISECONDS); if (si == null) { /* We timed out looking for more writes to batch, go ahead and flush immediately */ flush(); si = queuedRequests.take(); } if (si == REQUEST_OF_DEATH) { break; } long startProcessTime = Time.currentElapsedTime(); ServerMetrics.getMetrics().SYNC_PROCESSOR_QUEUE_TIME.add(startProcessTime - si.syncQueueStartTime); // track the number of records written to the log // 将请求写入到事务日志中,并跟踪写入日志的记录数量 if (zks.getZKDatabase().append(si)) { if (shouldSnapshot()) {//判断是否要生成快照 resetSnapshotStats(); // roll the log zks.getZKDatabase().rollLog(); //滚动日志 // take a snapshot if (!snapThreadMutex.tryAcquire()) { LOG.warn("Too busy to snap, skipping"); } else { new ZooKeeperThread("Snapshot Thread") { public void run() { try { zks.takeSnapshot();//生成快照 } catch (Exception e) { LOG.warn("Unexpected exception", e); } finally { snapThreadMutex.release(); } } }.start(); } } } else if (toFlush.isEmpty()) { // optimization for read heavy workloads // iff this is a read, and there are no pending // flushes (writes), then just pass this to the next // processor if (nextProcessor != null) { nextProcessor.processRequest(si); if (nextProcessor instanceof Flushable) { ((Flushable) nextProcessor).flush(); } } continue; } toFlush.add(si); if (shouldFlush()) { flush(); } ServerMetrics.getMetrics().SYNC_PROCESS_TIME.add(Time.currentElapsedTime() - startProcessTime); } } catch (Throwable t) { handleException(this.getName(), t); } LOG.info("SyncRequestProcessor exited!"); }
接着进入下一个调用链 FinalRequestProcessor.processRequest:
这个是最终的一个处理器,主要负责把已经commit的写操作应用到本机,对于读操作则从本机中读取 数据并返回给client
public void processRequest(Request request) { LOG.debug("Processing request:: {}", request); // request.addRQRec(">final"); long traceMask = ZooTrace.CLIENT_REQUEST_TRACE_MASK; if (request.type == OpCode.ping) { traceMask = ZooTrace.SERVER_PING_TRACE_MASK; } if (LOG.isTraceEnabled()) { ZooTrace.logRequest(LOG, traceMask, 'E', request, ""); } ProcessTxnResult rc = zks.processTxn(request); //省略代码 ServerCnxn cnxn = request.cnxn; long lastZxid = zks.getZKDatabase().getDataTreeLastProcessedZxid(); String lastOp = "NA"; // Notify ZooKeeperServer that the request has finished so that it can // update any request accounting/throttling limits zks.decInProcess(); zks.requestFinished(request); Code err = Code.OK; Record rsp = null; String path = null; try { //省略代码。。。。。 switch (request.type) { //省略部分代码。。。。。 case OpCode.exists: {//进入到exists请求 lastOp = "EXIS"; // TODO we need to figure out the security requirement for this! ExistsRequest existsRequest = new ExistsRequest();// 构建一个Exists请求 //反序列化 (将ByteBuffer反序列化成为ExitsRequest.这个就是我们在客户端 发起请求的时候传递过来的Request对象 ByteBufferInputStream.byteBuffer2Record(request.request, existsRequest); path = existsRequest.getPath();;//得到请求的路径 if (path.indexOf('\0') != -1) { throw new KeeperException.BadArgumentsException(); }//终于找到一个很关键的代码,判断请求的getWatch是否存在,如果存在,则传递 cnxn(servercnxn) //对于exists请求,需要监听data变化事件,添加watcher Stat stat = zks.getZKDatabase().statNode(path, existsRequest.getWatch() ? cnxn : null); rsp = new ExistsResponse(stat);//返回元数据 requestPathMetricsCollector.registerRequest(request.type, path); break; } //省略代码。。。。 ReplyHeader hdr = new ReplyHeader(request.cxid, lastZxid, err.intValue()); updateStats(request, lastOp, lastZxid); try { if (path == null || rsp == null) { cnxn.sendResponse(hdr, rsp, "response"); } else { int opCode = request.type; Stat stat = null; // Serialized read and get children responses could be cached by the connection // object. Cache entries are identified by their path and last modified zxid, // so these values are passed along with the response. switch (opCode) { case OpCode.getData : { GetDataResponse getDataResponse = (GetDataResponse) rsp; stat = getDataResponse.getStat(); cnxn.sendResponse(hdr, rsp, "response", path, stat, opCode); break; } case OpCode.getChildren2 : { GetChildren2Response getChildren2Response = (GetChildren2Response) rsp; stat = getChildren2Response.getStat(); cnxn.sendResponse(hdr, rsp, "response", path, stat, opCode); break; } default: cnxn.sendResponse(hdr, rsp, "response"); } } if (request.type == OpCode.closeSession) { cnxn.sendCloseSession(); } } catch (IOException e) { LOG.error("FIXMSG", e); } }
这里的 cnxn 是 SverCnxn cnxn = request.cnxn在 processRequest(Request request) 方法内,推至前面 c.doIO(k) 的这个c 是通过 NIOServerCnxn c = (NIOServerCnxn) k.attachment() 获取到的。
statNode的处理逻辑按照前面我们讲过的原理,statNode应该会做两个事情 获取指定节点的元数据 保存针对该节点的事件监听 注意,在这个方法中,将ServerCnxn向上转型为Watcher了。
最后将这个信息保存在服务器端:
public Stat statNode(String path, Watcher watcher) throws KeeperException.NoNodeException { Stat stat = new Stat(); DataNode n = nodes.get(path); //根据path获取节点数据 if (watcher != null) {//如果watcher不为空,则将当前的watcher和path进行绑定 dataWatches.addWatch(path, watcher); } if (n == null) { throw new KeeperException.NoNodeException(); } synchronized (n) { n.copyStat(stat);//copy属性设置到stat中 } updateReadStat(path, 0L); return stat; }
WatchManager.addWatch 通过WatchManager来保存指定节点的事件监听,WatchManager维护了两个集合。
private final Map<String, Set<Watcher>> watchTable = new HashMap<>(); private final Map<Watcher, Set<String>> watch2Paths = new HashMap<>();
watchTable表示从节点路径到watcher集合的映射 ,而watch2Paths则表示从watcher到所有节点路径集合的映射
public synchronized boolean addWatch(String path, Watcher watcher, WatcherMode watcherMode) { if (isDeadWatcher(watcher)) {//判断这个连接是否已经断开,如果是,则直接忽略 LOG.debug("Ignoring addWatch with closed cnxn"); return false; } //存储指定path对应的watcher,一个path可以存在多个客户端进行watcher,所以保存了一个set集合 Set<Watcher> list = watchTable.get(path);//判断watcherTable中是否存在当前路径对应的watcher if (list == null) {//如果为空,说明针对当前节点的watcher还不存在,则进行初始化。 // don't waste memory if there are few watches on a node // rehash when the 4th entry is added, doubling size thereafter // seems like a good compromise //如果节点上的watcher很少,就不要浪费内存,只添加4个长度,后续进行扩容 list = new HashSet<>(4); watchTable.put(path, list); }//把watcher(对应的是一个ServerCnxn)保存到list中。 list.add(watcher); //watcher到节点的映射关系表 Set<String> paths = watch2Paths.get(watcher); if (paths == null) {{//如果为空,则初始化并保存 // cnxns typically have many watches, so use default cap here paths = new HashSet<>(); watch2Paths.put(watcher, paths); } //设置watch的模式 //watch 有三种类型,一种是PERSISTENT、一种是PERSISTENT_RECURSIVE、STANDARD,前者是持久化订阅,后者是持久化递归订阅,所谓递归订阅就是针对监听的节点的子节点的变化都会触发监听, watcherModeManager.setWatcherMode(watcher, path, watcherMode); //将path保存到集合 return paths.add(path); }
至此,服务端处理完成。在FinalRequestProcessor的processRequest方法中,将处理结果rsp返回给客户端。调用关系链如下
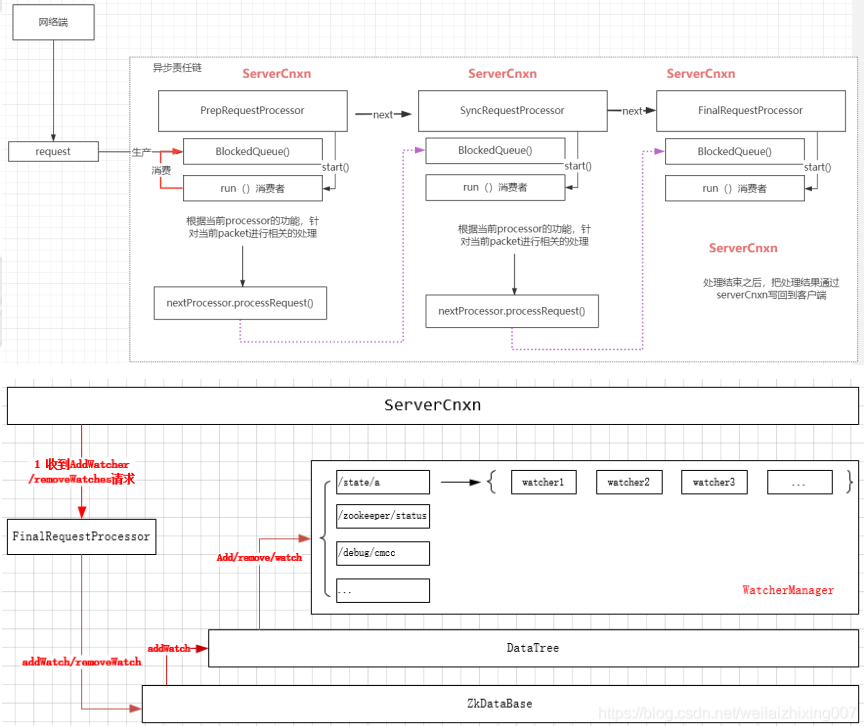
客户端接收服务端处理完成的响应:
服务端处理完成以后,由于在 发送exsits的时候调用了doTransport ,本身调用这个方法之前的ClientCnxn 的 run方法是一直在轮询跑着的。所以在不断的轮询Selector ,所以这里不管是客户端的读还是写操作,都会进入ClientCnxnSocketNIO.doIO ,
客户端接收请求的处理是在ClientCnxnSocketNIO的doIO中,之前客户端发起请求是写,现在客户端收 到请求,则是一个读操作,也就是当客户端收到服务端的数据时会触发一下代码的执行。其中很关键的 是 sendThread.readResponse(incomingBuffer); 来接收服务端的请求。
这里是接收服务端的返回:
void doIO(List<Packet> pendingQueue, LinkedList<Packet> outgoingQueue, ClientCnxn cnxn)
throws InterruptedException, IOException {
SocketChannel sock = (SocketChannel) sockKey.channel();
if (sock == null) {
throw new IOException("Socket is null!");
}
if (sockKey.isReadable()) {
int rc = sock.read(incomingBuffer);
if (rc < 0) {
throw new EndOfStreamException(
"Unable to read additional data from server sessionid 0x"
+ Long.toHexString(sessionId)
+ ", likely server has closed socket");
}//判断是否有刻度数据
if (!incomingBuffer.hasRemaining()) {
incomingBuffer.flip();
if (incomingBuffer == lenBuffer) {
recvCount++;
readLength();
} else if (!initialized) {
readConnectResult();
enableRead();
if (findSendablePacket(outgoingQueue,
cnxn.sendThread.clientTunneledAuthenticationInProgress()) != null) {
// Since SASL authentication has completed (if client is configured to do so),
// outgoing packets waiting in the outgoingQueue can now be sent.
enableWrite();
}
lenBuffer.clear();
incomingBuffer = lenBuffer;
updateLastHeard();
initialized = true;
} else {//读取响应
sendThread.readResponse(incomingBuffer);
lenBuffer.clear();
incomingBuffer = lenBuffer;
updateLastHeard();
}
}
}
......//省略部分代码
}
}
根据当前场景我们现在是接收服务器响应应该走的是 read,最后会调用 sendThread.readResponse(incomingBuffer);来读取数据:
void readResponse(ByteBuffer incomingBuffer) throws IOException { ByteBufferInputStream bbis = new ByteBufferInputStream(incomingBuffer); BinaryInputArchive bbia = BinaryInputArchive.getArchive(bbis); ReplyHeader replyHdr = new ReplyHeader(); replyHdr.deserialize(bbia, "header"); switch (replyHdr.getXid()) { //判断返回的信息类型。 case PING_XID: LOG.debug("Got ping response for session id: 0x{} after {}ms.", Long.toHexString(sessionId), ((System.nanoTime() - lastPingSentNs) / 1000000)); return; case AUTHPACKET_XID: LOG.debug("Got auth session id: 0x{}", Long.toHexString(sessionId)); if (replyHdr.getErr() == KeeperException.Code.AUTHFAILED.intValue()) { changeZkState(States.AUTH_FAILED); eventThread.queueEvent(new WatchedEvent(Watcher.Event.EventType.None, Watcher.Event.KeeperState.AuthFailed, null)); eventThread.queueEventOfDeath(); } return; case NOTIFICATION_XID: LOG.debug("Got notification session id: 0x{}", Long.toHexString(sessionId)); WatcherEvent event = new WatcherEvent(); event.deserialize(bbia, "response"); // convert from a server path to a client path if (chrootPath != null) { String serverPath = event.getPath(); if (serverPath.compareTo(chrootPath) == 0) { event.setPath("/"); } else if (serverPath.length() > chrootPath.length()) { event.setPath(serverPath.substring(chrootPath.length())); } else { LOG.warn("Got server path {} which is too short for chroot path {}.", event.getPath(), chrootPath); } } WatchedEvent we = new WatchedEvent(event); LOG.debug("Got {} for session id 0x{}", we, Long.toHexString(sessionId)); eventThread.queueEvent(we); return; default: break; } // If SASL authentication is currently in progress, construct and // send a response packet immediately, rather than queuing a // response as with other packets. if (tunnelAuthInProgress()) { GetSASLRequest request = new GetSASLRequest(); request.deserialize(bbia, "token"); zooKeeperSaslClient.respondToServer(request.getToken(), ClientCnxn.this); return; } Packet packet; synchronized (pendingQueue) {//pendingQueue中存储的是客户端传递过去的数据包packet if (pendingQueue.size() == 0) { throw new IOException("Nothing in the queue, but got " + replyHdr.getXid()); } packet = pendingQueue.remove();//表示这个请求包已经处理完成,直接移除 } /* * Since requests are processed in order, we better get a response * to the first request! */ try { if (packet.requestHeader.getXid() != replyHdr.getXid()) { packet.replyHeader.setErr(KeeperException.Code.CONNECTIONLOSS.intValue()); throw new IOException("Xid out of order. Got Xid " + replyHdr.getXid() + " with err " + replyHdr.getErr() + " expected Xid " + packet.requestHeader.getXid() + " for a packet with details: " + packet); } //把服务端返回的头信息设置到packet中 packet.replyHeader.setXid(replyHdr.getXid()); packet.replyHeader.setErr(replyHdr.getErr()); packet.replyHeader.setZxid(replyHdr.getZxid()); if (replyHdr.getZxid() > 0) { lastZxid = replyHdr.getZxid(); } //反序列化返回的消息体 if (packet.response != null && replyHdr.getErr() == 0) { packet.response.deserialize(bbia, "response"); } LOG.debug("Reading reply session id: 0x{}, packet:: {}", Long.toHexString(sessionId), packet); } finally { finishPacket(packet);//调用finishPacket完成消息的处理 } }
这个方法里面主要的流程如下 首先读取header,如果其xid == -2,表明是一个ping的response,return 如果xid是 -4 ,表明是一个AuthPacket的response return 如果xid是 -1,表明是一个notification,此时要继续读取并构造一个enent,通过 EventThread.queueEvent发送,return
其它情况下:从pendingQueue拿出一个Packet,校验后更新packet信息,对于exists请求,返回的xid=1,则进入到其他情况来处理
最后调用 finishPacket 注册本地事件:主要功能是把从 Packet 中取出对应的 Watcher 并注册到 ZKWatchManager 中去
protected void finishPacket(Packet p) { int err = p.replyHeader.getErr(); if (p.watchRegistration != null) { //将事件注册到zkwatchemanager中 //watchRegistration,熟悉吗?在组装请求的时候,我们初始化了这个对象 //把watchRegistration 子类里面的 Watcher 实例放到 ZKWatchManager 的 existsWatches 中存储起来。 p.watchRegistration.register(err); } // Add all the removed watch events to the event queue, so that the // clients will be notified with 'Data/Child WatchRemoved' event type. //将所有已删除的监听时间添加到事件队列,这样客户端可以收到 `data/child`事件已删除的类型通知 if (p.watchDeregistration != null) { Map<EventType, Set<Watcher>> materializedWatchers = null; try { materializedWatchers = p.watchDeregistration.unregister(err); for (Entry<EventType, Set<Watcher>> entry : materializedWatchers.entrySet()) { Set<Watcher> watchers = entry.getValue(); if (watchers.size() > 0) { queueEvent(p.watchDeregistration.getClientPath(), err, watchers, entry.getKey()); // ignore connectionloss when removing from local // session p.replyHeader.setErr(Code.OK.intValue()); } } } catch (KeeperException.NoWatcherException nwe) { p.replyHeader.setErr(nwe.code().intValue()); } catch (KeeperException ke) { p.replyHeader.setErr(ke.code().intValue()); } } //cb就是AsnycCallback,如果为null,表明是同步调用的接口,不需要异步回掉,因此,直接notifyAll即可。 //这里唤醒的就是在客户端调用exists方法中,wait()的逻辑,这样表示服务处理完成。 if (p.cb == null) { synchronized (p) { p.finished = true; p.notifyAll(); } } else { p.finished = true; eventThread.queuePacket(p); } }
其中 watchRegistration 为 exists 方法中初始化的 ExistsWatchRegistration,调用其注册事件:
public void register(int rc) { if (shouldAddWatch(rc)) {//根据返回的code来决定是否需要添加watch Map<String, Set<Watcher>> watches = getWatches(rc); synchronized(watches) {//初始化watches集合 Set<Watcher> watchers = watches.get(clientPath); if (watchers == null) { watchers = new HashSet<Watcher>(); watches.put(clientPath, watchers); }//把watcher保存到watches集合,此时的watcher对应的 就是在exists方法中传入的匿名内部类。 watchers.add(watcher);//初始化客户端的时候自己定义的实现Watcher接口的类 } } } //ExistsWatchRegistration.getWatches protected Map<String, Set<Watcher>> getWatches(int rc) { return rc == 0 ? watchManager.dataWatches : watchManager.existWatches; }
而这里的 ExistsWatchRegistration.getWatches 获取到的集合在本场景下是获取到的 dataWatches :
private static class ZKWatchManager implements ClientWatchManager { private final Map<String, Set<Watcher>> dataWatches = new HashMap<String, Set<Watcher>>(); private final Map<String, Set<Watcher>> existWatches = new HashMap<String, Set<Watcher>>(); private final Map<String, Set<Watcher>> childWatches = new HashMap<String, Set<Watcher>>();
.......
总的来说,当使用 ZooKeeper 构造方法或者使用 getData、exists 和getChildren 三个接口来向 ZooKeeper 服务器注册 Watcher 的时候,首先将此消息传递给服务端,传递成功后,服务端会通知客户端,然后客户端将该路径和Watcher 对应关系存储起来备用。
finishPacket 方法最终会调用 eventThread.queuePacket, 将当前的数据包添加到等待事件通知的队列中.
public void queuePacket(Packet packet) {
if (wasKilled) {
synchronized (waitingEvents) {
if (isRunning) waitingEvents.add(packet);
else processEvent(packet);
}
} else {
waitingEvents.add(packet);
}
}
事件触发:
前面这么长的说明,只是为了清晰的说明事件的注册流程,最终的触发,还得需要通过事务型操作来完成在我们最开始的案例中,通过如下代码去完成了事件的触发
zooKeeper.setData("/zk-wuzz","1".getBytes(),stat.getVersion());
修改节点的值触发监听前面的客户端和服务端对接的流程就不再重复讲解了,交互流程是一样的,唯一的差别在于事件触发了.由于调用链路最终都会走到FinalRequestProcessor.processRequest.
服务端收到setData请求时,会进入到FinalRequestProcessor这个类中 ProcessTxnResult rc = zks.processTxn(request); 我们跟进 zks.processTxn(hdr, txn) :
public ProcessTxnResult processTxn(Request request) { TxnHeader hdr = request.getHdr(); processTxnForSessionEvents(request, hdr, request.getTxn()); final boolean writeRequest = (hdr != null); final boolean quorumRequest = request.isQuorum(); // return fast w/o synchronization when we get a read if (!writeRequest && !quorumRequest) { return new ProcessTxnResult(); } synchronized (outstandingChanges) { ProcessTxnResult rc = processTxnInDB(hdr, request.getTxn(), request.getTxnDigest()); // request.hdr is set for write requests, which are the only ones // that add to outstandingChanges. if (writeRequest) { long zxid = hdr.getZxid(); while (!outstandingChanges.isEmpty() && outstandingChanges.peek().zxid <= zxid) { ChangeRecord cr = outstandingChanges.remove(); ServerMetrics.getMetrics().OUTSTANDING_CHANGES_REMOVED.add(1); if (cr.zxid < zxid) { LOG.warn( "Zxid outstanding 0x{} is less than current 0x{}", Long.toHexString(cr.zxid), Long.toHexString(zxid)); } if (outstandingChangesForPath.get(cr.path) == cr) { outstandingChangesForPath.remove(cr.path); } } } // do not add non quorum packets to the queue. if (quorumRequest) { getZKDatabase().addCommittedProposal(request); } return rc; } }
通过 getZKDatabase().processTxn(hdr, txn) 链路,最终会调用到 DataTree.processTxn(TxnHeader header, Record txn) :
public ProcessTxnResult processTxn(TxnHeader header, Record txn, boolean isSubTxn) { ProcessTxnResult rc = new ProcessTxnResult(); try { rc.clientId = header.getClientId(); rc.cxid = header.getCxid(); rc.zxid = header.getZxid(); rc.type = header.getType(); rc.err = 0; rc.multiResult = null; switch (header.getType()) { //省略代码..... case OpCode.setData: SetDataTxn setDataTxn = (SetDataTxn) txn; rc.path = setDataTxn.getPath(); rc.stat = setData( setDataTxn.getPath(), setDataTxn.getData(), setDataTxn.getVersion(), header.getZxid(), header.getTime()); break; //省略代码。。。。
在这里我们会再进这个分支:
public Stat setData(String path, byte[] data, int version, long zxid, long time) throws KeeperException.NoNodeException { Stat s = new Stat(); DataNode n = nodes.get(path);//得到节点数据 if (n == null) { throw new KeeperException.NoNodeException(); } byte[] lastdata = null; synchronized (n) {//修改节点数据 lastdata = n.data; nodes.preChange(path, n); n.data = data; n.stat.setMtime(time); n.stat.setMzxid(zxid); n.stat.setVersion(version); n.copyStat(s); nodes.postChange(path, n); } // now update if the path is in a quota subtree. String lastPrefix = getMaxPrefixWithQuota(path); long dataBytes = data == null ? 0 : data.length; if (lastPrefix != null) { this.updateCountBytes(lastPrefix, dataBytes - (lastdata == null ? 0 : lastdata.length), 0); } nodeDataSize.addAndGet(getNodeSize(path, data) - getNodeSize(path, lastdata)); updateWriteStat(path, dataBytes); //触发NodeDataChanged事件 dataWatches.triggerWatch(path, EventType.NodeDataChanged); return s; }
在这里可以看到 ,在服务端的节点是利用 DataNode 来保存的,在保存好数据后会触发对应节点的 NodeDataChanged 事件:
public WatcherOrBitSet triggerWatch(String path, EventType type, WatcherOrBitSet supress) { //根据类型、连接状态、路径,构建WatchedEvent WatchedEvent e = new WatchedEvent(type, KeeperState.SyncConnected, path); Set<Watcher> watchers = new HashSet<>(); //是否是递归watcher,也就是如果针对/wuzz加了递归的watch,那么如果/wuzz下有子节点,则会递归/wuzz下所有子节点,触发事件通知 PathParentIterator pathParentIterator = getPathParentIterator(path); synchronized (this) {//遍历节点 for (String localPath : pathParentIterator.asIterable()) { //根据path获取watcher Set<Watcher> thisWatchers = watchTable.get(localPath); if (thisWatchers == null || thisWatchers.isEmpty()) { continue; }//针对一个path会有多个watcher,所以遍历所有watcher Iterator<Watcher> iterator = thisWatchers.iterator(); while (iterator.hasNext()) { Watcher watcher = iterator.next(); //根据watcher和path得到watchermode WatcherMode watcherMode = watcherModeManager.getWatcherMode(watcher, localPath); if (watcherMode.isRecursive()) {//如果是递归watch if (type != EventType.NodeChildrenChanged) { watchers.add(watcher); } } else if (!pathParentIterator.atParentPath()) { watchers.add(watcher); if (!watcherMode.isPersistent()) {//如果不是持久化监听 iterator.remove();//先移除当前的watcher Set<String> paths = watch2Paths.get(watcher); if (paths != null) {//根据watcher得到路径列表 paths.remove(localPath); } } } } if (thisWatchers.isEmpty()) { watchTable.remove(localPath); } } } if (watchers.isEmpty()) { if (LOG.isTraceEnabled()) { ZooTrace.logTraceMessage(LOG, ZooTrace.EVENT_DELIVERY_TRACE_MASK, "No watchers for " + path); } return null; } for (Watcher w : watchers) { if (supress != null && supress.contains(w)) { continue; } w.process(e);//遍历watchers,循环处理事件 } switch (type) { case NodeCreated: ServerMetrics.getMetrics().NODE_CREATED_WATCHER.add(watchers.size()); break; case NodeDeleted: ServerMetrics.getMetrics().NODE_DELETED_WATCHER.add(watchers.size()); break; case NodeDataChanged: ServerMetrics.getMetrics().NODE_CHANGED_WATCHER.add(watchers.size()); break; case NodeChildrenChanged: ServerMetrics.getMetrics().NODE_CHILDREN_WATCHER.add(watchers.size()); break; default: // Other types not logged. break; } return new WatcherOrBitSet(watchers); }
还记得我们在服务端绑定事件的时候,watcher 绑定是是什么?是 ServerCnxn,所以 w.process(e),其实调用的应该是 ServerCnxn 的 process 方法。而servercnxn 又是一个抽象方法,有两个实现类,分别是:NIOServerCnxn 和 NettyServerCnxn。那接下来我们扒开 NIOServerCnxn 这个类的 process 方法看看究竟:
synchronized public void process(WatchedEvent event) {
ReplyHeader h = new ReplyHeader(-1, -1L, 0);
if (LOG.isTraceEnabled()) {
ZooTrace.logTraceMessage(LOG, ZooTrace.EVENT_DELIVERY_TRACE_MASK,
"Deliver event " + event + " to 0x"
+ Long.toHexString(this.sessionId)
+ " through " + this);
}
// Convert WatchedEvent to a type that can be sent over the wire
WatcherEvent e = event.getWrapper();
sendResponse(h, e, "notification");
}
那接下里,客户端会收到这个 response,触发 SendThread.readResponse 方法。
客户端处理事件响应:
还是在不断轮询Selector ,所以这里不管是客户端的读还是写操作,都会进入ClientCnxnSocketNIO.doIO,然后我们直接进入 SendThread.readResponse:
客户端收到请求,仍然执行SendThread.readResponse,此时的消息通知类型的xid=-1,所以需要进 入到-1的分支进行判断
void readResponse(ByteBuffer incomingBuffer) throws IOException { ByteBufferInputStream bbis = new ByteBufferInputStream(incomingBuffer); BinaryInputArchive bbia = BinaryInputArchive.getArchive(bbis); ReplyHeader replyHdr = new ReplyHeader(); replyHdr.deserialize(bbia, "header"); switch (replyHdr.getXid()) { case PING_XID: LOG.debug("Got ping response for session id: 0x{} after {}ms.", Long.toHexString(sessionId), ((System.nanoTime() - lastPingSentNs) / 1000000)); return; case AUTHPACKET_XID: LOG.debug("Got auth session id: 0x{}", Long.toHexString(sessionId)); if (replyHdr.getErr() == KeeperException.Code.AUTHFAILED.intValue()) { changeZkState(States.AUTH_FAILED); eventThread.queueEvent(new WatchedEvent(Watcher.Event.EventType.None, Watcher.Event.KeeperState.AuthFailed, null)); eventThread.queueEventOfDeath(); } return; case NOTIFICATION_XID://收到事件请求 LOG.debug("Got notification session id: 0x{}", Long.toHexString(sessionId)); WatcherEvent event = new WatcherEvent(); event.deserialize(bbia, "response");//反序列化对象,得到WatcherEvent // convert from a server path to a client path if (chrootPath != null) { String serverPath = event.getPath(); if (serverPath.compareTo(chrootPath) == 0) { event.setPath("/"); } else if (serverPath.length() > chrootPath.length()) { event.setPath(serverPath.substring(chrootPath.length())); } else { LOG.warn("Got server path {} which is too short for chroot path {}.", event.getPath(), chrootPath); } } //构建一个WatchedEvent,加入EventThread.queueEvent事件通知线程 WatchedEvent we = new WatchedEvent(event); LOG.debug("Got {} for session id 0x{}", we, Long.toHexString(sessionId)); eventThread.queueEvent(we); return; default: break; } //省略代码。。。。。。。
这里是客户端处理事件回调,这里传过来的 xid 是等于 -1。SendThread 接收到服务端的通知事件后,会通过调用 EventThread 类的queueEvent 方法将事件传给 EventThread 线程,queueEvent 方法根据该通知事件,从 ZKWatchManager 中取出所有相关的 Watcher,如果获取到相应的 Watcher,就会让 Watcher 移除失效:
private void queueEvent(WatchedEvent event, Set<Watcher> materializedWatchers) { if (event.getType() == EventType.None && sessionState == event.getState()) { return; } sessionState = event.getState(); final Set<Watcher> watchers; if (materializedWatchers == null) { // materialize the watchers based on the event watchers = watcher.materialize(event.getState(), event.getType(), event.getPath()); } else { watchers = new HashSet<Watcher>(); watchers.addAll(materializedWatchers); } WatcherSetEventPair pair = new WatcherSetEventPair(watchers, event); // queue the pair (watch set & event) for later processing waitingEvents.add(pair); }
其中Meterialize 方法是通过 dataWatches 或者 existWatches 或者 childWatches 的 remove 取出对应的watch,表明客户端 watch 也是注册一次就移除同时需要根据 keeperState、eventType 和 path 返回应该被通知的 Watcher 集合
这里也进一步说明了zookeeper的watcher事件是不复用的,触发一次就没了,除非再注册一次。
public Set<Watcher> materialize(Watcher.Event.KeeperState state, Watcher.Event.EventType type, String clientPath) { Set<Watcher> result = new HashSet<Watcher>(); switch (type) { case None: result.add(defaultWatcher); boolean clear = ClientCnxn.getDisableAutoResetWatch() && state != Watcher.Event.KeeperState.SyncConnected; synchronized(dataWatches) { for(Set<Watcher> ws: dataWatches.values()) { result.addAll(ws); } if (clear) { dataWatches.clear(); } } synchronized(existWatches) { for(Set<Watcher> ws: existWatches.values()) { result.addAll(ws); } if (clear) { existWatches.clear(); } } synchronized(childWatches) { for(Set<Watcher> ws: childWatches.values()) { result.addAll(ws); } if (clear) { childWatches.clear(); } } return result; case NodeDataChanged://节点变化 case NodeCreated://节点创建 synchronized (dataWatches) { addTo(dataWatches.remove(clientPath), result); } synchronized (existWatches) { addTo(existWatches.remove(clientPath), result); } break; case NodeChildrenChanged://子节点变化 synchronized (childWatches) { addTo(childWatches.remove(clientPath), result); } break; case NodeDeleted://节点删除 synchronized (dataWatches) { addTo(dataWatches.remove(clientPath), result); } // XXX This shouldn't be needed, but just in case synchronized (existWatches) { Set<Watcher> list = existWatches.remove(clientPath); if (list != null) { addTo(list, result); LOG.warn("We are triggering an exists watch for delete! Shouldn't happen!"); } } synchronized (childWatches) { addTo(childWatches.remove(clientPath), result); } break; default://默认 String msg = "Unhandled watch event type " + type + " with state " + state + " on path " + clientPath; LOG.error(msg); throw new RuntimeException(msg); } return result; }
最后一步,接近真相了,waitingEvents 是 EventThread 这个线程中的阻塞队列,很明显,又是在我们第一步操作的时候实例化的一个线程。从名字可以知道,waitingEvents 是一个待处理 Watcher 的队列,EventThread 的run() 方法会不断从队列中取数据,交由 processEvent 方法处理:
public void run() {
try {
isRunning = true;
while (true) {
Object event = waitingEvents.take();
if (event == eventOfDeath) {
wasKilled = true;
} else {
processEvent(event);
}
if (wasKilled)
synchronized (waitingEvents) {
if (waitingEvents.isEmpty()) {
isRunning = false;
break;
}
}
}
} catch (InterruptedException e) {
LOG.error("Event thread exiting due to interruption", e);
}
LOG.info("EventThread shut down for session: 0x{}",
Long.toHexString(getSessionId()));
}
继而调用 processEvent(event):
private void processEvent(Object event) {
try {// 判断事件类型
if (event instanceof WatcherSetEventPair) {
// each watcher will process the event
// 得到 watcherseteventPair
WatcherSetEventPair pair = (WatcherSetEventPair) event;
// 拿到符合触发机制的所有 watcher 列表,循环进行调用
for (Watcher watcher : pair.watchers) {
try {// 调用客户端的回
watcher.process(pair.event);
} catch (Throwable t) {
LOG.error("Error while calling watcher ", t);
}
}
} else {
。。。。//省略代码
}
}
最后调用到自定义的 Watcher 处理类。至此整个Watcher 事件处理完毕。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!