


Elasticsearch概念及安装
官网:https://www.elastic.co/cn/products/elasticsearch
Elasticsearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。又以下特点
- 分布式,无需人工搭建集群(solr就需要人为配置,使用Zookeeper作为注册中心)
- Restful风格,一切API都遵循Rest原则,容易上手
- 近实时搜索,数据更新在Elasticsearch中几乎是完全同步的。
ElasticSearch 中的基本概念:
NRT(Near Realtime):近实时,写入数据时,过1秒才会被搜索到,因为内部在分词、录入索引。es搜索时:搜索和分析数据需要秒级出结果。
Index索引:索引是具有相似特性的文档集合。例如,可以为用户数据提供索引,为产品目录建立另一个索引,以及为订单数据建立另一个索引。索引由名称(必须全部为小写)标识,该名称用于在对其中的文档执行索引、搜索、更新和删除操作时引用索引。在单个群集中,您可以定义尽可能多的索引。
Type类型:在索引中,可以定义一个或多个类型。类型是索引的逻辑类别/分区,其语义完全取决于您。一般来说,类型定义为具有公共字段集的文档。例如,假设你运行一个博客平台,并将所有数据存储在一个索引中。在这个索引中,您可以为用户数据定义一种类型,为博客数据定义另一种类型,以及为注释数据定义另一类型。
Document文档:文档是可以被索引的信息的基本单位。例如,您可以为单个用户提供一个文档,单个产品提供另一个文档,以及单个订单提供另一个文档。本文件的表示形式为JSON(JavaScript Object Notation)格式,这是一种非常普遍的互联网数据交换格式。在索引/类型中,您可以存储尽可能多的文档。请注意,尽管文档物理驻留在索引中,文档实际上必须索引或分配到索引中的类型。
Shards & Replicas分片与副本:索引可以存储大量的数据,这些数据可能超过单个节点的硬件限制。例如,十亿个文件占用磁盘空间1TB的单指标可能不适合对单个节点的磁盘或可能太慢服务仅从单个节点的搜索请求。为了解决这一问题,Elasticsearch提供细分你的指标分成多个块称为分片的能力。当你创建一个索引,你可以简单地定义你想要的分片数量。每个分片本身是一个全功能的、独立的“指数”,可以托管在集群中的任何节点。Shards分片的重要性主要体现在以下两个特征:
- 分片允许您水平拆分或缩放内容的大小
- 分片允许你分配和并行操作的碎片(可能在多个节点上)从而提高性能/吞吐量
这个机制中的碎片是分布式的以及其文件汇总到搜索请求是完全由ElasticSearch管理,对用户来说是透明的。在同一个集群网络或云环境上,故障是任何时候都会出现的,拥有一个故障转移机制以防分片和结点因为某些原因离线或消失是非常有用的,并且被强烈推荐。为此,Elasticsearch允许你创建一个或多个拷贝,你的索引分片进入所谓的副本或称作复制品的分片,简称Replicas。Replicas的重要性主要体现在以下两个特征:
- 副本为分片或节点失败提供了高可用性。为此,需要注意的是,一个副本的分片不会分配在同一个节点作为原始的或主分片,副本是从主分片那里复制过来的。
- 副本允许用户扩展你的搜索量或吞吐量,因为搜索可以在所有副本上并行执行。
可能到这里您对这些概念还有点模糊,没关系,在以后的使用过程中慢慢就会有深刻的体会了。
Elasticsearch的使用场景:
- 维基百科,类似百度百科,“网络七层协议”的维基百科,全文检索,高亮,搜索推荐
- StackOverflflow(国外的程序讨论论坛),相当于程序员的贴吧。遇到it问题去上面发帖,热心网友下面回帖解答。
- GitHub(开源代码管理),搜索上千亿行代码。
- 电商网站,检索商品
- 日志数据分析,logstash采集日志,ES进行复杂的数据分析(ELK技术,elasticsearch+logstash+kibana)
- 商品价格监控网站,用户设定某商品的价格阈值,当低于该阈值的时候,发送通知消息给用户,比如说订阅《Carl的笔记》的监控,如果价格低于27块钱,就通知我,我就去买。
- BI系统,商业智能(Business Intelligence)。大型连锁超市,分析全国网点传回的数据,分析各个商品在什么季节的销售量最好、利润最高。成本管理,店面租金、员工工资、负债等信息进行分析。从而部署下一个阶段的战略目标。
Elasticsearch的特点:
- 可拓展性:大型分布式集群(数百台服务器)技术,处理PB级数据,大公司可以使用。小公司数据量小,也可以部署在单机。大数据领域使用广泛。
- 技术整合:将全文检索、数据分析、分布式相关技术整合在一起:lucene(全文检索),商用的数据分析软件(BI软件),分布式数据库(mycat)
- 部署简单:开箱即用,很多默认配置不需关心,解压完成直接运行即可。拓展时,只需多部署几个实例即可,负载均衡、分片迁移集群内部自己实施。
- 接口简单:使用restful api进行交互,跨语言。功能强大:Elasticsearch作为传统数据库的一个补充,提供了数据库所不不能提供的很多功能,如全文检索,同义词处理,相关度排名。
关系型数据库和 ElasticSearch 操作姿势对比:
JDBC 操作 ElasticSearch Client 操作
- 加载驱动类(JDBC 驱动)
- 建立连接(Connection) ----------------1、建立连接(TransportClient)
- 创建语句集(Statement)----------------2、条件构造(SearchRequestBuilder)
- 执行语句集 execute() ----------------3、执行语句 execute()
- 获取结果集(ResultSet)----------------4、获取结果(SearchResponse)
- 关闭结果、语句、连接 ----------------5、关闭以上操作
文件储存:
Elasticsearch的文件存储,Elasticsearch是面向文档型数据库,一条数据在这里就是一个文档,用JSON作为文档序列化的格式,比如下面这条用户数据:
{
"name" : "carl",
"sex" : "Male",
"age" : 18,
"birthDate": "1990/05/10",
"interests": [ "sports", "music" ]
}
用Mysql这样的数据库存储就会容易想到建立一张User表,有name,sex等字段,在Elasticsearch里这就是一个文档,当然这个文档会属于一个User的类型,各种各样的类型存在于一个索引当中。这里有一份简易的将Elasticsearch和关系型数据术语对照表:
关系数据库 ⇒ 数据库 ⇒ 表 ⇒ 行 ⇒ 列(Columns)
Elasticsearch ⇒ 索引(Index) ⇒ 类型(type) (7.x版本正式将type剔除) ⇒ 文档 (Docments)⇒ 字段(Fields)
一个 Elasticsearch 集群可以包含多个索引(数据库),也就是说其中包含了很多类型(表)。这些类型中包含了很多的文档(行),然后每个文档中又包含了很多的字段(列)。Elasticsearch的交互,可以使用JavaAPI,也可以直接使用HTTP的Restful API方式
ElasticSearch 集群搭建:
JDK:1.8
OS:windows
es版本:elasticsearch-6.5.1.zip,官方下载地址 https://www.elastic.co/cn/downloads/elasticsearch
但是这个版本不是最新的。我们来简单对比一下大版本的区别:
| 版本信息 | 6.X | 7.X |
| 集群连接对比 | 可使用TransportClient | 建议使用restclient TransportClient被废弃,只能使用restclient。于java编程,建议采用 High-level-rest-client 的方式操作ES集群 |
| ES数据存储结构变化 | index/type 一对一 | 建议使用_doc做type 去除了type,es7中使用默认的_doc作为type |
| 默认配置变化 | 默认节点名称为主机名,默认分片数改为5 | 默认节点名称为主机名,默认分片数改为1 |
| ES程序包默认打包jdk | Jdk需自己安装配置,需要配置官方支持的jdk版本建议在Java 8发行版系列中安装Java版本1.8.0_131或更高版本。打包大小100M+ 的捆绑版本的OpenJDK。 | 捆绑的JVM,位于Elasticsearch主目录的jdk目录中。可使用自己的Java版本,在JAVA_HOME环境配置。打包大小300M+(包含jdk) |
| 查询相关性速度优化 | 倒排索引的方式进行查询 |
倒排索引的方式进行查询+Weak-AND算法 |
| 间隔查询(Intervals queries) | 无 | 查找单词或短语彼此相距一定距离的记录 |
| 安全性功能 | 6.8有免费 | 其他无 7.0无免费 其他有免费 |
1.下载之后,直接解压即可。单机版的话运行 bin 目录下的 elasticsearch.bat 文件 。伪分布式需要进行配置,首先我们先解压三份出来,组成一主二从的局面:
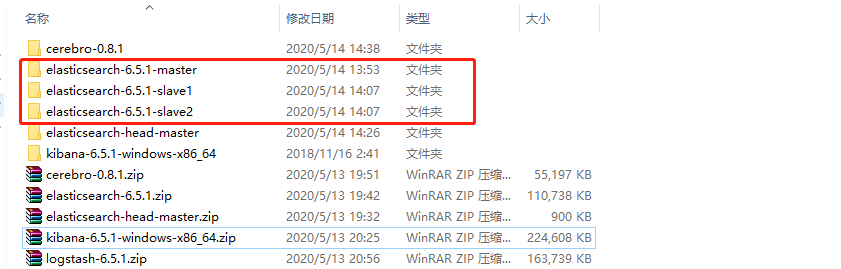
2.修改master的配置,进入安装目录中 config 下面,编辑 elasticsearch.yml
cluster.name: wuzz-cluster # 集群的名称
node.name: master # 节点ID,保证唯一
node.master: true # 是否主节点
network.host: 127.0.0.1 #对外公开的 IP 地址,如果自动识别配置为 0.0.0.0
同样配置其他两个节点的 elasticsearch.yml:
// slave-1
cluster.name: wuzz-cluster #集群名称三个节点保持一致
node.name: slave-1 #从节点 ID,保证唯一
network.host: 127.0.0.1 #对外公开的 IP 地址,如果自动识别配置为 0.0.0.0
http.port: 8200 #默认端口为 9200,因为我的环境是在同一台机器,因此,指定服务端口号
discovery.zen.ping.unicast.hosts: ["127.0.0.1"] #集群的 IP 组,配置主节点 IP 即可
// slave-2
cluster.name: wuzz-cluster #集群名称三个节点保持一致
node.name: slave-2 #从节点 ID,保证唯一
network.host: 127.0.0.1 #对外公开的 IP 地址,如果自动识别配置为 0.0.0.0
http.port: 8000 #默认端口为 9200,因为我的环境是在同一台机器,因此,指定服务端口号
discovery.zen.ping.unicast.hosts: ["127.0.0.1"] #集群的 IP 组,配置主节点 IP 即可
3.启动三个节点,成功的话可以看到类似这样的输出信息:
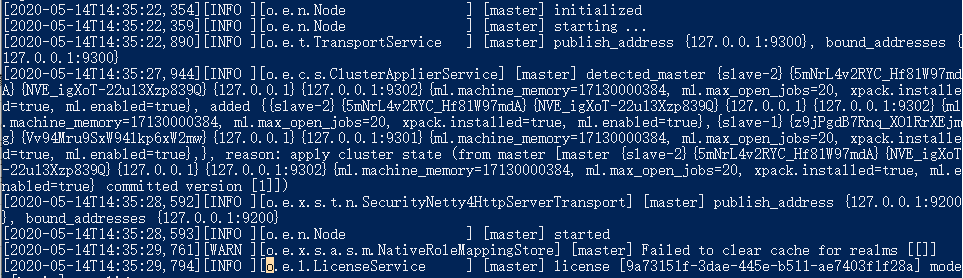
4.分别访问http://localhost:9200/,http://localhost:8200/,http://localhost:8000/,都会输出节点信息,说明配置完成:

Linux 下部署 ES 相关操作注意,以7.9.1版本为例的话
1.要是在生产环境下确定你的内存在16G以上
2.确定防火墙 ,开放对应端口
3.关闭SEliunx,或者设置为宽容模式
4.是否安装了JDK
5.配置操作系统进程线程数与文件句柄数,找到 /etc/security/limits.conf 文件
#进程线程数 设置限制数量,第一列表示用户,* 表示所有用户
* soft nproc 131072 #单个用户可用的最大进程数量(超过会警告);
* hard nproc 131072 #单个用户可用的最大进程数量(超过会报错);
# 文件句柄数
* soft nofile 131072#可打开的文件描述符的最大数(超过会警告);
* hard nofile 131072 #可打开的文件描述符的最大数(超过会报错);
6.虚拟内存 /etc/sysctl.conf
#es使用hybrid max mapfs / niofs目录来存储index数据,操作系统的默认mmap count限制是很低的,可能会导致内存耗尽的异常。
vm.swappiness=1
vm.max_map_count=262144
7.配置swappiness
#将vm.swappiness设置为1,这可以尽量减少linux内核swap的倾
向,在正常情况下,就不会进行swap,但是在紧急情况下,还是会进行swap操作。 也就是
vm.swappiness=1 ,如果你希望完全不会swap。那我们还是需要配置swappiness值为0,那么内存在free和file-backed使用的页面总量小于高水位标记(high water mark也就是我们设置的
值)之前,不会发生交换。
重新指定JDK,修改默认启动文件 bin/elasticsearch ,7.9.1 默认使用JDK14
#配置ES自带的jdk
export JAVA_HOME=/es/elasticsearch-7.9.1/jdk
export PATH=$JAVA_HOME/bin:$PATH
#添加jdk判断,注意,要带小引号。
if [ -x "$JAVA_HOME/bin/java" ]; then
JAVA="/es/elasticsearch-7.9.1/jdk/bin/java"
else
JAVA=`which java`
fi
在启动elasticsearch之前,ES在启动的时候是不允许使用root账户的,所以我们要新建一个用户 es。
更换权限:chown -R es:es /es/elasticsearch/elasticsearch-7.9.1 (需要在root权限下更换权限,而不是其他权限下.sudo相当于以系统管理员身份运行,而不需要root密码.)
绑定IP network.host: 192.168.1.101
配置ES内存 /es/elasticsearch-7.9.1/config/jvm.options
在配置文件中设置
-Xms8g
-Xmx8g
根据生产情况设定。建议-Xms与-Xmx配置成一样,同时不要超过32G,一些文档说是30.5G
elasticsearch.yml详细配置:
cluster.name:
配置elasticsearch的集群名称,默认是elasticsearch。建议修改成一个有意义的名称。
node.name:
节点名,通常一台物理服务器就是一个节点,es会默认随机指定一个名字,建议指定一个有意义的名称,方便管理一个或多个节点组成一个cluster集群,集群是一个逻辑的概念,节点是物理概念,后边章节会详细介绍。
path.conf:
设置配置文件的存储路径,tar或zip包安装默认在es根目录下的config文件夹,rpm安装默认在/etc/ elasticsearch
path.data:
设置索引数据的存储路径,默认是es根目录下的data文件夹,可以设置多个存储路径,用逗号隔开。
path.logs:
设置日志文件的存储路径,默认是es根目录下的logs文件夹
path.plugins:
设置插件的存放路径,默认是es根目录下的plugins文件夹
bootstrap.memory_lock: true
设置为true可以锁住ES使用的内存,避免内存与swap分区交换数据。
network.host:
设置绑定主机的ip地址,设置为0.0.0.0表示绑定任何ip,允许外网访问,生产环境建议设置为具体的ip。
http.port: 9200
设置对外服务的http端口,默认为9200。
transport.tcp.port: 9300 集群结点之间通信端口
node.master:
指定该节点是否有资格被选举成为master结点,默认是true,如果原来的master宕机会重新选举新的master。
node.data:
指定该节点是否存储索引数据,默认为true。
#es7.x 之后新增的配置,节点发现
discovery.seed_hosts: ["localhost:9700","localhost:9800","localhost:9900"]
#es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举master
cluster.initial_master_nodes: ["node1", "node2","node3"]
node.max_local_storage_nodes:
单机允许的最大存储结点数,通常单机启动一个结点建议设置为1,开发环境如果单机启动多个节点可设置大于1。
可视化工具之 elasticsearch-head:
1.因为head是一个Node.js项目。所以,如果没有安装nodejs需要先安装Node.js,安装可以参考 https://www.cnblogs.com/wuzhenzhao/p/12672125.html
2.因为运行head需要借助grunt命令,所以需要安装grunt。进入Node.js目录下,执行命令npm install -g grunt-cli,将grunt安装位全局命令。进入head主目录执行npm install安装grunt,安装完成后执行grunt -version查看是否安装成功,会显示安装的版本号。
如果npm 不让使用,执行 set-ExecutionPolicy RemoteSigned 就好了

3.下载 https://github.com,搜索 elasticsearch-head 关键字。下载 elasticsearch-head-master.zip 包。
4..配置主节点 elasticsearch.yml
http.cors.enabled: true
http.cors.allow-origin: "*"
node.data: true
5.命令行进入head文件夹执行执行npm install 安装完成后执行grunt server 或者npm run start 运行head插件,如果不成功重新安装grunt。成功如下:
6.然后就可以通过 http://localhost:9100/ 来访问:

可视化工具之 Cerebro:
下载 https://github.com/lmenezes/cerebro/releases
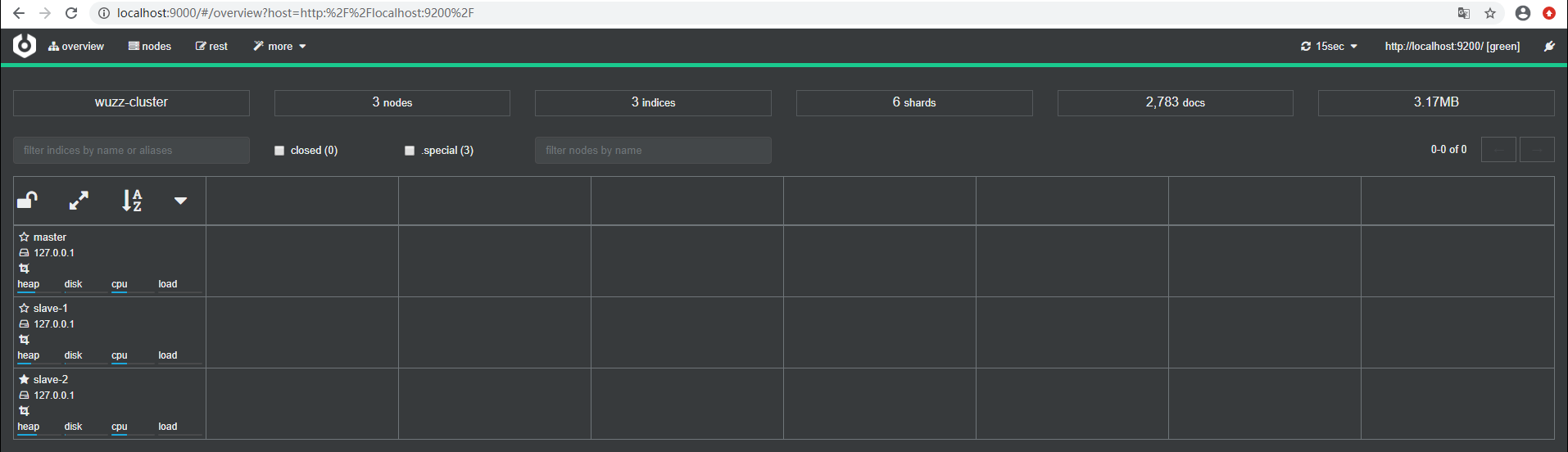
下载完解压,运行成功如下图所示

然后就可以通过 http://localhost:9000/ 进行访问:
可视化工具之 Kibana:
版本:需要与 ElasticSearch保持一致,也是6.5.1
下载 :https://www.elastic.co/cn/downloads/past-releases 下载 Kibana6.5.1
1.进行安装目录 config 下面,修改 kibana.yml (保持默认也可以)默认链接本地9200端口的es
server.port: 5601
server.host: "0.0.0.0"
elasticsearch.url: "http://192.168.1.101:9200" #es集群主节点地址
kibana.index: ".kibana"
2.进入bin 启动 启动 kibana 即可,然后通过 http://localhost:5601/ 进行访问。点击 monitoring 就可以看到es集群信息:
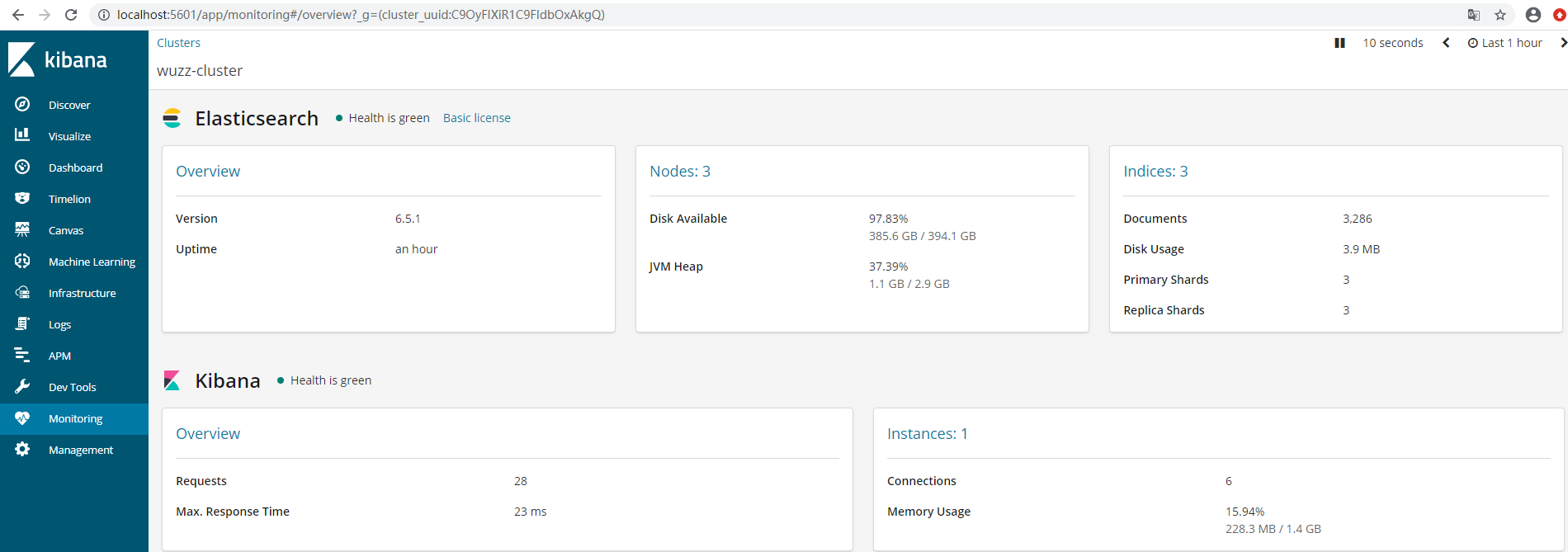
- Discover:日志管理视图 主要进行搜索和查询
- Visualize:统计视图 构建可视化的图表
- Dashboard:仪表视图 将构建的图表组合形成图表盘
- Timelion:时间轴视图 随着时间流逝的数据
- APM:性能管理视图 应用程序的性能管理系统
- Canvas:大屏展示图
- Dev Tools: 开发者命令视图 开发工具
- Monitoring:健康视图 请求访问性能预警
- Management:管理视图 管理工具

