


spring-cloud-stream消息驱动的微服务
Spring Cloud Stream 是 一 个用来为微服务应用构建消息驱动能力的框架。 它可以基于Spring Boot 来创建独立的、 可用于生产的 Spring 应用程序。 它通过使用 Spring Integration来连接消息代理中间件以实现消息事件驱动。 Spring Cloud Stream 为 一 些供应商的消息中间件产品提供了个性化的自动化配置实现,并且引入了发布与订阅、 消费组以及分区这三个核心概念。 简单地说, Spring Cloud Stream 本质上就是整合了 Spring Boot 和 SpringIntegration, 实现了 一 套轻量级的消息驱动的微服务框架。 通过使用 Spring Cloud Stream,可以有效简化开发人员对消息中间件的使用复杂度, 让系统开发人员可以有更多的精力关注于核心业务逻辑的处理。 由于 Spring Cloud Stream 基于 Spring Boot 实现,所以它秉承了Spring Boot 的优点,自动化配置的功能可帮助我们快速上手使用。
快速入门:
1.创建 一 个基础的 Spring Boot 工程,添加以下依赖:
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-rabbit</artifactId>
</dependency>
</dependencies>
2.创建用于接收来自 RabbitMQ 消息的消费者 SinkReceiver
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.cloud.stream.annotation.EnableBinding;
import org.springframework.cloud.stream.annotation.StreamListener;
import org.springframework.cloud.stream.messaging.Sink;
@EnableBinding(Sink.class)
public class SinkReceiver {
private static Logger logger = LoggerFactory.getLogger(SinkReceiver.class);
@StreamListener(Sink.INPUT)
public void receive(String payload) {
logger.info("Received Message: " + payload);
}
}
3.创建主类:
@SpringBootApplication
public class StreamApp {
private final static Logger log = LoggerFactory.getLogger(StreamApp.class);
public static void main(String[] args) {
SpringApplication.run(StreamApp.class, args);
log.info("服务启动成功 ");
}
}
4.新增配置:
spring.rabbitmq.host = 192.168.1.101
spring.rabbitmq.username = guest
spring.rabbitmq.password = guest
spring.rabbitmq.port = 5672
到这里, 快速入门示例的编码任务已经完成了。 下面我们分别启动 RabbitMQ 以及该Spring Boot 应用, 然后做下面的测试, 看看它们是如何运作的。先来看一 下Spring Boot 应用的启动日志,我们可以发现如下信息

我们看到连接了 Rabbit,声明了一 个名为input.anonymous.eAIrmYmoRfGNwBYNynD3Uw 的队列,并通过RabbitMessageChannelBinder将自己绑定为它的消费者。 这些信息我们也能在RabbitMQ的控制台中发现它们

下面我们可以在 RabbitMQ的控制台中 进入 input.anonymous.eAIrmYmoRfGNwBYNynD3Uw 队列 的管理页面, 通过Publish message功能来发送 一 条消息到该 队列中。
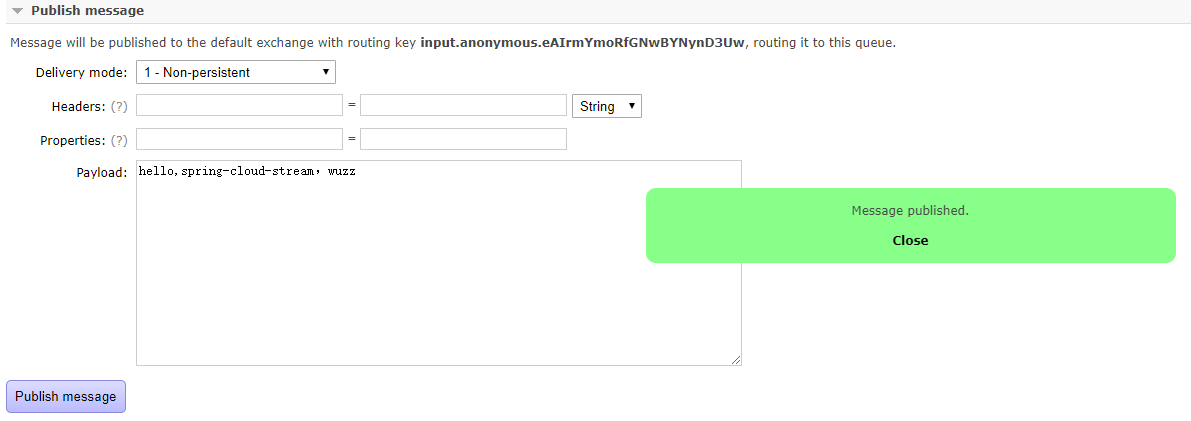
此时, 我们可以在当前启动的Spring Boot应用程序的控制台中看到下面的内容:

可以 发现在应用控制台中输出的内容就是SinkReceiver中的receive方法定义的, 而输出的具体内容则来自消息队列中获取的对象。
接着, 我们再来看看这里用到的几个Spring Cloud Stream的核心注解, 它们都被定义在SinkReceiver中。
@EnableBinding, 该注解用来指定 一 个或多个定义了@Input或@Output 注解的接口, 以此实现对消息通道 (Channel) 的绑定。 在上面的例子中, 我们通过@EnableBinding(Sink.class)绑定了 Sink接口, 该接口是 Spring CloudStream中默认实现的对输入消息通道绑定的定义, 它的源码如下:
public interface Sink {
String INPUT = "input";
@Input("input")
SubscribableChannel input();
}
它通过@Input注解绑定了 一 个名为input的通道。除了Sink之外,Spring CloudStream还默认实现了绑定 output 通道的 Source 接口, 还有结合了Sink和Source的Processor接口,实际使用时我们也可以自已通过@Input和@Output注解来定义绑定消息通道的接口。 当需要为@EnableBinding指定多个接口来绑定消息通道的时候, 可以这样定义: @EnableBinding ( value = {Sink. class,Source .class})。
@StreamListener: 它主要定义在方法上, 作用是将被修饰的方法注册为消息中间件上数据流的事件监听器, 注解中的属性值对应了监听的消息通道名。 在上面的例子中, 我们通过@StreamListener (Sink. INPUT)注解将receive方法注册为input消息通道的监听处理器,所以当我们在RabbitMQ的控制页面中发布消息的时候, receive方法会做出对应的响应动作。
核心概念:
下图是官方文档中Spring Cloud Stream应用模型的结构图。从中我们可以看到,SpringCloud Stream构建的应用程序与消息中间件之间是通过绑定器 Binder相关联的, 绑定器对于应用程序而言起到了隔离作用, 它使得不同消息中间件的实现细节对应用程序来说是透明的。 所以对于每 一 个Spring Cloud Stream的应用程序来说, 它不需要知晓消息中间件的通信细节, 它只需知道Binder 对应程序提供的抽象概念来使用消息中间件来实现业务逻辑即可, 而 这个抽象概念就是在上文中我们提到的消息通道: Channel。如下图所示, 在应用程序和Binder之间定义 了两条输入通道和三条输出通道来传递消息, 而绑定器则是作为这些通道和消息中间件之间的桥梁进行通信。

绑定器:
Binder绑定器是Spring Cloud Stream中 一 个非常重要的概念。 在没有绑定器这个概念的情况下, SpringBoot应用要直接与消息中间件进行信息交互的时候, 由于各消息中间件构建的初衷不同, 所以它们在实现细节上会有较大的差异, 这使得我们实现的消息交互逻辑就会非常笨重, 因为对具体的中间件实现细节有太重的依赖, 当中间件有较大的变动升级或是更换中间件的时候, 我们就需要付出非常大的代价来实施。
通过定义绑定器作为中间层, 完美地实现了应用程序与消息中间件细节之间的隔离。 通过向应用程序暴露统 一 的Channel通道, 使得应用程序不需要再考虑各种不同的消息中间件的实现。 当需要升级消息中间件, 或是更换其他消息中间件产品时, 我们要做的就是更换它们对应的Binder绑定器而 不需要修改任何SpringBoot的应用逻辑。这 一 点在消息总线时, 从RabbitMQ切换到Kafka的过程中, 已经能够让我们体验到这 一 好处。目前版本的Spring Cloud Stream为主流的消息中间件产品RabbitMQ和Kafka提供了默认的Binder 实现, 在上文的例子中, 我们就使用了RabbitMQ的Binder。 另外,Spring Cloud Stream还实现了 一 个专门用于测试的TestSupportBinder, 开发者可以直接使用它来对通道的接收内容进行可靠的测试断言。 如果要使用除了RabbitMQ 和 Kafka以外的消息中间件的话, 我们也可以通过使用它所提供的扩展API来实现其他中间件的Binder。
发布-订阅模式:
Spring Cloud Stream中的消息通信方式遵循了发布-订阅模式, 当 一 条消息被投递到消息中间件之后,它会通过共享的Topic主题进行广播,消息消费者在订阅的主题中收到它并触发自身的业务逻辑处理。这里所 提到的Topic 主题是SpringCloud Stream中的 一 个抽象概念,用来代表发布共享消息给消费者的地方。 在不同的消息中间件中,Topic可能对应不同的概念, 比如, 在RabbitMQ中,它对应Exchange, 而在 Kakfa中则对应Kafka中的Topic。
在上面的示例中,我们通过RabbitMQ的Channel发布消息给 我们编写的应用程序消费, 而实际上SpringCloud Stream应用启动的时候,在RabbitMQ的Exchange中也创建了 一 个名为 input的Exchange交换器, 由于Binder的隔离作用, 应用程序并无法感知它的存在,应用程序只知道自己指向Binder的输入或是输出通道。而在Exchanges选项卡中,我们还能找到名为input的交换器:
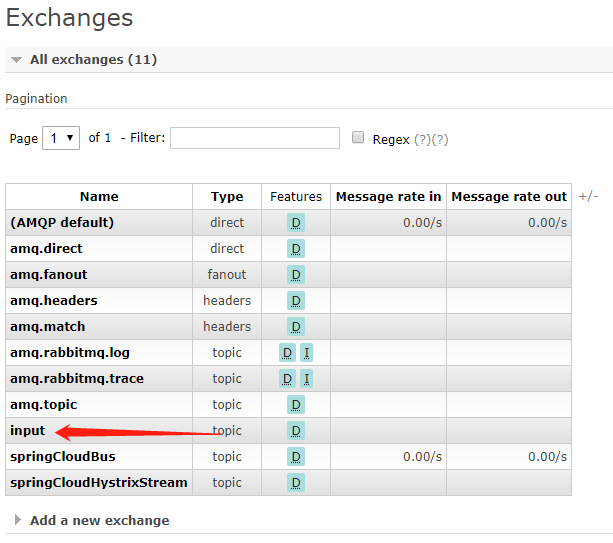
单击进入可以看到如下图所示的详情页面。 Bindings栏中的内容就是应用程序绑定通道中的消息队列, 我们可以通过Exchange页面的Publish Message来发布消息, 此时可以发现启动的应用程序都输出了消息内容。

相对于点对点队列实现的消息通信来说,Spring Cloud Stream采用的发布-订阅模式可以有效降低消息生产者与消费者之间的耦合。 当需要对同 一 类消息增加 一 种处理方式时,只需要增加 一 个应用程序并将输入通道绑定到既有的Topic中就可以实现功能的扩展,而不需要改变原来已经实现的任何内容。
消费组:
虽然Spring Cloud Stream通过发布-订阅模式将消息生产者与消费者做了很好的解耦,基于相同主题的消费者可以轻松地进行扩展, 但是这些扩展都是针对不同的应用实例而言的。 在现实的微服务架构中, 我们的每 一 个微服务应用为了实现高可用和负载均衡, 实际上都会部署多个实例。 在很多情况下, 消息生产者发送消息给某个具体微服务时, 只希望被消费 一 次,为了解决这个问题, 在Spring Cloud Stream中提供了消费组的概念。
如果在同 一 个主题上的应用需要启动多个实例的时候,我们可以通过 spring.cloud.stream.bindings.input.group属性为应用指定 一 个组名,这样这个应用的多个实例在接收到消息的时候, 只会有 一 个成员真正收到消息并进行处理。 默认情况下, 当没有为应用指定消费组的时候, Spring Cloud Stream会为其分配 一 个独立的匿名消费组。 所以, 如果同 一 主题下的所有应用都没有被指定消费组的时候, 当有消息发布之后, 所有的应用都会对其进行消费, 因为它们各自都属于 一 个独立的组。 大部分情况下, 我们在创建Spring Cloud Stream应用的时候, 建议最好为其指定 一 个消费组,以防止对消息的重复处理, 除非该行为需要这样做(比如刷新所有实例的配置等)。
消息分区:
通过引入消费组的概念, 我们已经能够在多实例的清况下, 保障每个消息只被组内的一个实例消费。 通过上面对消费组参数设置后的实验, 我们可以观察到, 消费组无法控制消息具体被哪个实例消费。 也就是说, 对于同 一 条消息, 它多次到达之后可能是由不同的实例进行消费的。 但是对于一 些业务场景, 需要对 一 些具有相同特征的消息设置每次都被同 一 个消费实例处理, 比如,一 些用于监控服务, 为了统计某段时间内消息生产者发送的报告内容, 监控服务需要在自身聚合这些数据, 那么消息生产者可以为消息增加 一 个固有的特征ID来进行分区, 使得拥有这些ID的消息每次都能被发送到 一 个特定的实例上实现累计统计的效果, 否则这些数据就会分散到各个不同的节点导致监控结果不 一 致的情况。而分区概念的引入就是为了解决这样的问题: 当生产者将消息数据发送给多个消费者实例时, 保证拥有共同特征的消息数据始终是由同 一 个消费者实例接收和处理。
Spring Cloud Stream 为分区提供了通用的抽象实现, 用来在消息中间件的上层实现分区处理所以它对于消息中间件自身是否实现了消息分区并不关心, 这使得 Spring CloudStream 为不具备分区功能的消息中间件也增加了分区功能扩展。
使用详解:
开启绑定功能:
在 Spring Cloud Stream 中,我们需要通过 @EnableBinding 注解来为应用启动消息驱动的功能, 该注解我们在快速入门中已经有了基本的介绍, 下面来详细看看它的定义:
@Target({ElementType.TYPE, ElementType.ANNOTATION_TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
@Configuration
@Import({
//该配置会加载消息通道绑定必要的一些实例,比如SpEL表达式转换器配置
BindingServiceConfiguration.class,
//要是在Spring加载Bean 的时候被调用, 用来实现加载更多的Bean
BindingBeansRegistrar.class,
//主要用来加载与消息中间件相关的配置信息, 比如, 它会从应用工程的META-INF/spring.binders中加载针对具体消息中间件相关的配置文件等。
BinderFactoryConfiguration.class}
)
@EnableIntegration
public @interface EnableBinding {
Class<?>[] value() default {};
}
从该注解的定义中我们可以看到,它自身包含了 @Configuration 注解,所以用它注解的类也会成为 Spring 的基本配置类。 另外该注解还通过 @Import 加载了 Spring Cloud Stream 运行需要的几个基础配置类。
绑定消息通道:
在Spring Cloud Steam中, 我们可以在接口中通过@nput和@Output注解来定义消息通道, 而用于定义绑定消息通道的接口则可以被@EnableBinding注解的value参数来指定, 从而在应用启动的时候实现对定义消息通道的绑定。上面的例子我们使用Sink接口绑定的消息通道。Sink接口是SpringCloud Steam提供的一 个默认实现, 除此之外还有Source和Processor, 可从它们的源t码中学习它们的定义方式:
public interface Sink {
String INPUT = "input";
@Input("input")
SubscribableChannel input();
}
public interface Source {
String OUTPUT = "output";
@Output("output")
MessageChannel output();
}
public interface Processor extends Source, Sink {
}
我们可以看到,Sink和Source中分别通过@Input和@Output注解定义了 输入通道和输出通道,而Processor通过继承Source和Sink的方式同时定义了 一 个输入通道和一 个输出通道。
另外, @Input和@Output 注解都还有一 个value属性,该属性可以用来设置消息通道的名称,这里Sink和Source中指定的消息通道名称分别为 input和output。如果我们直接使用这两个注解而没有指定具体的 value值,将默认使用方法名作为消息通道的名称 。需要 注意 一 点,当我们定义输出通道的时候,需要返回MessageChannel接口对象, 该接口定义了向消息通道发送消息的方法; 而定义输入通道时,需要返回SubscribableChannel接口对象,该接口 继承自MessageChannel接口,它定义了维护消息通道订阅者的方法。
注入绑定接口:
我们在示例中已经为 Sink接口绑定的 input消息通道实现了具体的消息消费者,下面可以通过注入的方式实现一 个消息生成者,向 input消息通道发送数据。
1.创建一 个将 Input消息通道作为 输出通道的接口,具体如下:
public interface SinkSender { @Output(Source.OUTPUT) MessageChannel output(); @Input(Sink.INPUT) SubscribableChannel input(); }
2.对快速入门中定义的 SinkReceiver做 一 些修改:在@EnableBinding 注解中增加对SinkSender接口的指定,使Spring Cloud Stream能创建出对应的实例 。
@EnableBinding(value = {SinkSender.class})
public class SinkReceiver {
private static Logger logger = LoggerFactory.getLogger(SinkReceiver.class);
@StreamListener(Sink.INPUT)
public void receive(String payload) {
logger.info("Received Message: " + payload);
}
}
3.添加配置
#交换机 spring.cloud.stream.bindings.input.destination = input-wuzz-data spring.cloud.stream.bindings.output.destination=output-wuzz-data # 若指定了group ,需要重新自定义Sink 默认的 Sink input通道会创建默认的group ,下面这样子写回抛出Bean重复定义异常,所以需要自定义Sink #spring.cloud.stream.bindings.input.group=positionInput # 交换机类型 #spring.cloud.stream.rabbit.bindings.input.consumer.exchange-type=direct # routingkey #spring.cloud.stream.rabbit.bindings.input.consumer.binding-routing-key=air.task.result
4.加个接口,注入 SinkSender 的实例, 并调用它的发送消息方法。
@RestController
public class TestController {
@Autowired
private SinkSender sinkSender;
@GetMapping(value = "/hello")
public void test(){
sinkSender.output().send(MessageBuilder.withPayload("From SinkSender").build());
}
}
5.测试,调用该接口,如果可以在控制台中找到如下输出内容, 表明我们的试验已经成功了, 消息被正确地发送到了 input 通道中, 并被相对应的消息消费者输出。

注入消息通道:
由于 Spring Cloud Stream 会根据绑定接口中的 Input 和 @Output 注解来创建消息通道实例, 所以我们也可以通过直接注入的方式来使用消息通道对象。
@Autowired
private MessageChannel output;
@GetMapping(value = "/hello")
public void test(){
output.send(MessageBuilder.withPayload("From MessageChannel").build());
}
这种用法虽然很直接, 但是也容易犯错, 很多时候我们在 一 个微服务应用中可能会创建多个不同名的 MessageChannel 实例, 这样通过 @Autowired 注入时, 要注意参数命名需要与通道同名才能被正确注入, 或者也可以使用 @Qualifier 注解来特别指定具体实例的名称, 该名称需要与定义 MessageChannel 的 @Output 中的value 参数 一 致, 这样才能被正确注入。 比如下面的例子, 在 一 个接口中定义了两个输出通道, 分别命名为 Output-1和Output-2, 当要使用 Output-1 的时候, 可以通过@Qualifier("Output-1") 来指定这个具体的实例来注入使用。
public interface SinkSender {
@Output("Output-1")
MessageChannel outputl();
@Output("Output-2")
MessageChannel output2();
}
@RestController
public class TestController {
@Autowired @Qualifier("Output-1")
private MessageChannel output;
......
}
消息生产与消费:
由于 Spring Cloud Stream 是基于 Spring Integration 构建起来的, 所以在使用 SpringCloud Stream 构建消息驱动服务的时候,完全可以使用 Spring Integration 的原生注解来实现各种业务需求。 同时, 为了简化面向消息的编程模型, Spring Cloud Stream 还提供了@StreamListener 注解对输入通道的处理做了进 一 步优化。 下面我们分别从这两方面来学习一 下对消息的处理。
spring Integration 原生支持:
通过之前的内容, 我们已经能够通过注入绑定接口和消息通道的方式实现向名为 input 的消息通道发送信息。接下来, 我们通过 Spring Integration 原生的 @ServiceActivator和@InboundChannelAdapter 注解来尝试实现相同的功能, 具体实现如下:
消费者及生产者需要属于两个不同的应用。消费者:
@EnableBinding(value = {Sink.class})
public class IntegrationSinkReceiver {
private static Logger logger = LoggerFactory.getLogger(IntegrationSinkReceiver.class);
@ServiceActivator(inputChannel=Sink.INPUT)
public void receive(@Payload Date payload, @Headers Map headers) {
logger.info(headers.get("contentType").toString());
logger.info("Received from {} channel Date: {}", Sink.INPUT, payload);
}
}
生产者:
@EnableBinding(value = {IntegrationSinkSender.SinkOutput.class})
public class IntegrationSinkSender {
private static Logger logger = LoggerFactory.getLogger(IntegrationSinkSender.class);
@Bean
@InboundChannelAdapter(value = SinkOutput.OUTPUT, poller = @Poller(fixedDelay = "2000"))
public MessageSource<Date> timerMessageSource() {
return () -> new GenericMessage<>(new Date());
}
public interface SinkOutput {
String OUTPUT = Sink.INPUT;
@Output(SinkOutput.OUTPUT)
MessageChannel output();
}
}
两个应用配置一样的信息:
spring.cloud.stream.bindings.input.destination = input-wuzz-data
spring.cloud.stream.bindings.output.destination = out-wuzz-data
- IntegrationSinkReceiver 类属于消息消费者实现, 与之前实现的类似, 只是做了一 些修改:使用原生的 @ServiceActivator 注解替换了 @StreamListener, 实现对Sink.INPUT 通道的监听处理, 而该通道绑定了名为 input的主题。
- IntegrationSinkSender 类属于消息生产者实现, 它在内部定义了 SinkOutput 接口来将输出通道绑定到名为 input 的主题中。 由于 SinkSender 和 SinkReceiver 共用一 个主题, 所以它们构成了 一 组生产者与消费者。 另外, 在SinkSender 中还创建了用于生产消息的 timerMessageSource 方法, 该方法会将当前时间作为消息返回。而 InboundChannelAdapter 注解定义了该方法是对 SinkOutput.OUTPUT通道的输出绑定, 同时使用 poller 参数将该方法设置为轮询执行, 这里我们定义为2000毫秒,所以它会以2秒的频率向 SinkOutput.OUTPUT 通道输出当前时间。
执行上面定义的程序, 可以得到类似下面的输出:

另外, 还可以通过 @Transformer 注解对指定通道的消息进行转换。 比如, 我们可以在上面的 IntegrationSinkSender 类中增加下面的内容:
@Transformer(inputChannel = Sink.INPUT, outputChannel = SinkOutput.OUTPUT)
public Object transform(Date message) {
return new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(message);
}
同时修改消息接收方法:
@ServiceActivator(inputChannel=Sink.INPUT)
public void receive(String payload) {
logger.info("Received from {} channel Date: {}", Sink.INPUT, payload);
}
再次执行就会输出以下信息:

如果我们使用 @SteamListener 注解的话 ,可以在方法上直接定义对应类型的消息对象。比如上面的String类型的输出。
消息反馈:特别注意 input 跟 output,如果接收方接不到消息,请检查这个是否写反了。
很多时候在处理完输入消息之后, 需要反馈一 个消息给对方, 这时候可以通过@SendTo 注解来指定返回内容的输出通道。
接收方:
@EnableBinding(value = {Processor.class})
public class IntegrationSinkReceiverAnswer {
private static Logger logger = LoggerFactory.getLogger(IntegrationSinkReceiverAnswer.class);
@StreamListener(Processor.INPUT)
@SendTo(Processor.OUTPUT)
public Object receive(String payload) {
logger.info("Received from {} channel Date: {}", Processor.INPUT, payload);
return "From Input Channel Return - " + payload;
}
@Transformer(inputChannel = Processor.INPUT, outputChannel = Processor.INPUT)
public Object transform(Date message) {
return new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(message);
}
}
或者这样:除了可以使用 @SendTo 注解将方法返回结果输出到消息通道中, 还可以使用原生注解 @ServiceActivator 的 outputChannel 属性配置
@EnableScheduling
@EnableBinding(value = {Processor.class})
public class IntegrationSinkReceiverAnswer {
private static Logger logger = LoggerFactory.getLogger(IntegrationSinkReceiverAnswer.class);
@ServiceActivator(inputChannel = Processor.INPUT,outputChannel = Processor.OUTPUT)
public Object receive(String payload) {
logger.info("Received from {} channel Date: {}", Processor.INPUT, payload);
return "From Input Channel Return - " + payload;
}
@Transformer(inputChannel = Processor.INPUT, outputChannel = Processor.INPUT)
public Object transform(Date message) {
return new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(message);
}
}
接收方的通道配置:
spring.cloud.stream.bindings.input.destination=input-wuzz-data
spring.cloud.stream.bindings.output.destination=output-wuzz-data
发送方:
@EnableBinding(value = {Processor.class})
public class IntegrationSinkSenderAnswer {
private static Logger logger = LoggerFactory.getLogger(IntegrationSinkSenderAnswer.class);
@Bean
@InboundChannelAdapter(value = Processor.OUTPUT, poller = @Poller(fixedDelay = "2000"))
public MessageSource<Date> timerMessageSource() {
return () -> new GenericMessage<>(new Date());
}
@Transformer(inputChannel = Processor.OUTPUT, outputChannel = Processor.OUTPUT)
public Object transform(Date message) {
return new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(message) + " Wuzz";
}
// 监听input通道
@StreamListener(Processor.INPUT)
public void receiveFromInput(String s) {
logger.info("SendToSender Received: " + s);
}
}
发送方通道配置:
spring.cloud.stream.bindings.input.destination = output-wuzz-data
spring.cloud.stream.bindings.output.destination = input-wuzz-data
启动后的效果:

响应式编程::特别注意 input 跟 output,如果接收方接不到消息,请检查这个是否写反了。
在 Spring Cloud Stream 中还支持使用基千于RxJava 的响应式编程来处理消息的输入和输出。 与 RxJava 的整合使用同样很容易, 下面我们详细看看如何使用 RxJava 实现上面消息。
基于上述反馈中试验的场景:
1.在消费者端添加依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream-rxjava</artifactId>
<version>1.0.2.RELEASE</version>
</dependency>
2.改造接收消息:
@EnableRxJavaProcessor
public class RxjavaSinkReceiverAnswer {
private static Logger logger = LoggerFactory.getLogger(RxjavaSinkReceiverAnswer.class);
@Bean
public RxJavaProcessor<String, String> receive() {
//data 就是接收方的消息
return inputStream -> inputStream.map(data -> {
logger.info("Received: " + data);
return data;
//返回发送端的消息
}).map(data -> String.valueOf("From Input Channel Return - " + data));
}
}
3.这里提醒一下大家,如果我们什么都不设置,由于传输的是 byte[] ,这里就直接报错了。所以要设置contentType,但是按照书上说的在propertis里面配置我一直不起作用,所以我在发消息的时候设置了:
@EnableBinding(value = {Processor.class})
public class IntegrationSinkSenderAnswer {
private static Logger logger = LoggerFactory.getLogger(IntegrationSinkSenderAnswer.class);
@Bean
@InboundChannelAdapter(value = Processor.OUTPUT, poller = @Poller(fixedDelay = "2000"))
public MessageSource<String> timerMessageSource() {
Map map =new HashMap();
map.put("contentType","text/plain;charset=UTF-8");
return () -> new GenericMessage<>(new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(new Date()) + "RxJava",new MessageHeaders(map));
}
// 监听input通道
@StreamListener(Processor.INPUT)
public void receiveFromInput(String s) {
logger.info("SendToSender Received: " + s);
}
}
4.按照我这个代码,大家要时刻注意 input 跟output,本例子的配置如下:
#消费端
spring.cloud.stream.bindings.input.destination = input-wuzz-data
spring.cloud.stream.bindings.output.destination = output-wuzz-data
#发送端
spring.cloud.stream.bindings.input.destination = output-wuzz-data
spring.cloud.stream.bindings.output.destination = input-wuzz-data
除了实现上面的场景之外,通过利用 RxJava 的支持,我们还能轻易地实现消息的缓存聚合。 比如, 我们希望Appl在接收到5条消息之后才将处理结果返回给输出通道, 那么只需通过下面的改进即可轻松实现这样的场景:
@Bean
public RxJavaProcessor<String, String> receive() {
//data 就是接收方的消息
return inputStream -> inputStream.map(data -> {
logger.info("Received: " + data);
return data;
//返回发送端的消息
}).buffer(5).map(data -> String.valueOf("From Input Channel Return - " + data));
}
这样子以后,消费端要累计消费5条消息才会相应,响应结果如下:

消息类型:
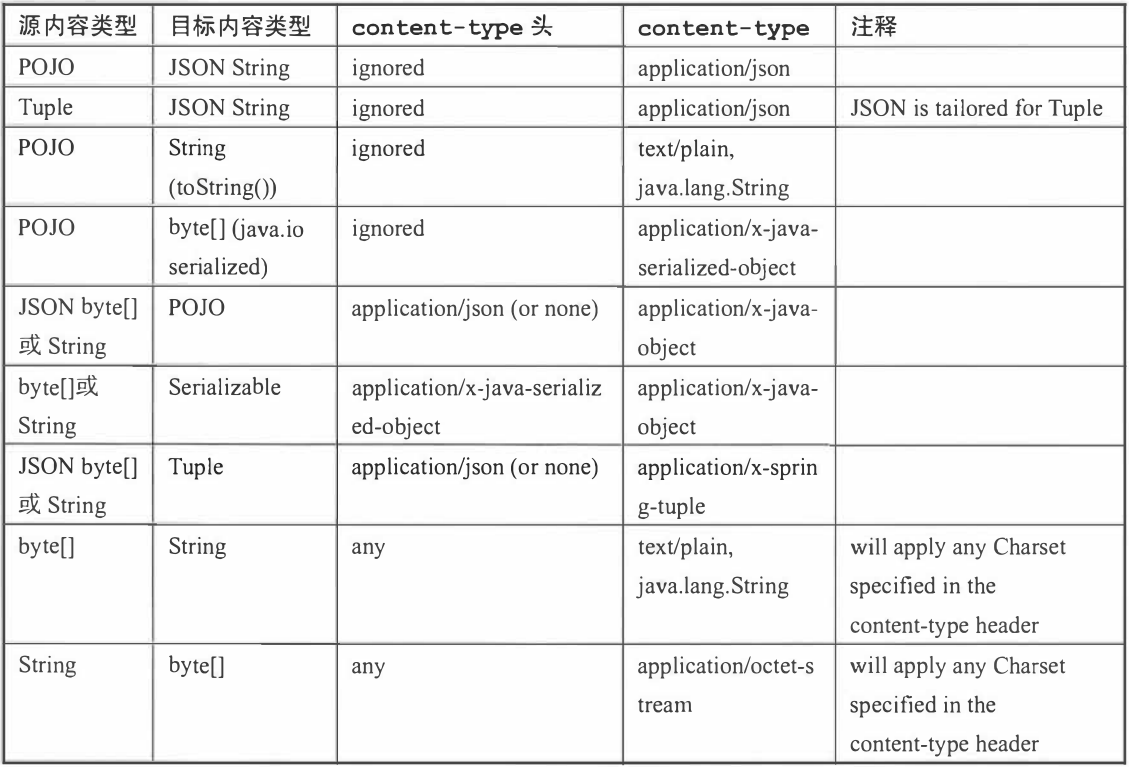
Spring Cloud Stream为了让开发者能够在消息中声明它的内容类型, 在输出消息中定义了 一 个默认 的头信息: content Type。对于那些不直接支持头信息 的消息中间件,SpringClou d Stream提供了自己的实现机制,它会在消息发出前自动将消息 包装进它自定义的消息封装格式中, 并加入头信息 。 而对于那些 自身就支待头信息 的消息中间件, SpringCloudStream构建的服务可以接收并处理来自非SpringCloud Stream构建但 包含符合规范头信息的应用程序发出的消息 。Spring Clou d Stream允许使用 spring.cloud.strearn.bindngs.<channelNarne>.content-type属性以声明式的配置方式为绑定的输入和输出通道设置消息 内容的类型。此外, 原生的消息类型转换器依然可以轻松地用于我们的应用程序 。 目前, Spring CloudStream中自带支持 了以下几种常用的消息类型转换。
- JSON与POJO的互相转换。
- JSON与org.springfrarnework.tuple.Tuple的互相转换。
- Object与byte[]的互相转换。 为 了实现远程传输序列化 的原始字节, 应用程序需要发送byte类型的数据, 或是 通过实现Jav a的序列化接口来转换为字节(Object对象必须可序列化)。
- String与byte[]的互相转换。
- Object向纯文本的 转换: Object需要实现toString()方法。
上面所指的 JSON类型可以 表现为一 个 byte类型的数组,也可以是 一 个包含有效JSON内容的字符串。 另外, Object对象可以由JSON、 byte数组或者字符串转换而来,但是在 转换为JSON的时候总是以字符串的形式返回。
MIME类型:配置方式可以参考以上响应式编程的Demo里的发送方。
在SpringClou d Stream中定义的 content-type属性采用了 Media Type, 即InternetMediaType (互联网媒体类型), 也被称为MIME类型, 常见的有 application/json、text/plain;charset=UTF-8, 相信接触过HTTP的工程师们对这些类型都不会感到陌生。MIME类型对于标示如何转换为 String或byte[]非常有用。 并且, 我们还可以使用MIME 类型格式来表示Jav a类型, 只需要使用带有类型参数的一般类型 :application/x-java-object。 比如, 我 们可 以 使用 application/x-javaobject;type = java.util.Map来表示传输的是一 个java.util.Map对象 , 或是使用application/x-java-object;type = com.wuzz.User 来表示传输的是 一 个com.wuzz.User对象;除此之外,更重要的是,它还提供了自定义的MIME类型,比如通过 application/x-spring-tuple来指定Spring的 Tuple类型。在Spring Cloud Stream中 默认提供了 一 些可以开箱即用的类型转换器, 具体 如下表所示。
消息类型的转换行为只会在需要进行转换时才被执行, 比如, 当服务模块产生了一 个头信息为application/json的XML字符串消息,Spring Cloud Stream是不会将该XML字符串转换为JSON的, 这是因为该模块的输出内容已经是 一 个字符串类型了, 所以它并不会将其做进一 步的转换。
另外需要注意的是, Spring Cloud Stream虽然同时支待输入通道和输出通道的消息类型转换, 但还是推荐开发者尽量在输出通道中做消息转换。 因为对千输入通道的消费者来说, 当目标是 一 个POJO的时候, 使用@StreamListener注解是能够支待自动对其进行转换的。
Spring Cloud Stream除了提供上面这些开箱即用的转换器之外, 还支持开发者自定义的消息转换器。 这使得我们可以使用任意格式(包括二进制)的数据进行发送和接收, 并且将这些数据与特定的contentType相关联。 在应用启用的时候, Spring Cloud Stream会将所有org.springframework. messaging.converter.MessageConverter接口实现的自定义转换器以及默认实现的那些转换器都加载到消息转换工厂中, 以提供给消息处理时使用。
消费组与消息分区:
消费组:
通常每个服务都不会以单节点的方式运行在生产环境中, 当同一 个服务启动多个实例的时候, 这些实例会绑定到同一 个消息通道的目标主题上。 默认情况下,当生产者发出一条消息到绑定通道上, 这条消息会产生多个副本被每个消费者实例接收和处理。 但是在有些业务场景之下, 我们希望生产者产生的消息只被其中一 个实例消费, 这个时候就需要为这些消费者设置消费组来实现这样的功能。 实现的方式非常简单, 只需在服务消费者端设置 spring.cloud.stream.bindings.input.group 属性即可,比如可以像下面这样实现。
spring.cloud.stream.bindings.input.destination=input-wuzz-data
spring.cloud.stream.bindings.output.destination=output-wuzz-data
spring.cloud.stream.bindings.input.group=Service-A
服务端也配置上如下信息:
spring.cloud.stream.bindings.input.destination = input-wuzz-data
spring.cloud.stream.bindings.output.destination = output-wuzz-data
到这里, 对千消费分组的示例就完成了。分别运行上面实现的生产者与消费者, 其中消费者我们启动多个实例。通过控制台, 可以发现, 每个生产者发出的消息会被启动的消费者以轮询的方式进行接收和输出 。
消息分区:
通过消费组的设置, 虽然我们已经能够在多实例环境下, 保证同 一 消息只被 一 个消费者 实例进行接收和处理, 但是, 对于一 些特殊场景,除了要保证单 一 实例消费之外, 还希望那些具备相同特征的消息都能够被同 一 个实例进行消费。 这时候我们就需要对 消息进行分区处理 。
接收方的配置:
spring.cloud.stream.bindings.input.destination=input-wuzz-data
spring.cloud.stream.bindings.output.destination=output-wuzz-data
spring.cloud.stream.bindings.input.group=Service-A
#通过该参数开启消费者分区功能。
spring.cloud.stream.bindings.input.consumer.partitioned= true
#该参数指定了当前消费者的总实例数量。
spring.cloud.stream.instance-count = 2
#该参数设置当前实例的索引号, 从0开始,
# 最大值为 spring.cloud.stream.instanceCount参数-1。
# 试验的时候需要启动多个实例, 可以通过运行参数来为不同实例设置不同的索引值。
spring.cloud.stream.instance-index= 0
发送方的配置
spring.cloud.stream.bindings.input.destination = input-wuzz-data
spring.cloud.stream.bindings.output.destination = output-wuzz-data
#分区
#通过该参数指定了分区键的表达式规则,我们可以根据实际的输出
#消息规则配置 SpEL 来生成合适的分区键。
spring.cloud.stream.bindings.input.producer.partitionKeyExpression = "partitionKey"
#该参数指定了消息分区的数量。
spring.cloud.stream.bindings.input.producer.partitionCount = 2
发送方的代码里要在header加上partitionKey ,另外特别注意 input 跟 output,如果接收方接不到消息,请检查这个是否写反了。
@Bean
@InboundChannelAdapter(value = SinkOutput.OUTPUT, poller = @Poller(fixedDelay = "2000"))
public MessageSource<CustomerMessage> timerMessageSource() {
CustomerMessage customerMessage = new CustomerMessage();
customerMessage.setId("111");
customerMessage.setBody("hello");
Message<CustomerMessage> partitionKey = MessageBuilder.withPayload(customerMessage).setHeader("partitionKey", 1).build();
return () -> partitionKey;
}
RabbitMQ与Kafka绑定器:
Spring Cloud Stream自身就提供了对RabbitMQ和Kafka的绑定器实现。 由于RabbitMQ 和 Kafka自身的实现结构有所不同 , 理解绑定器实现与消息中间件自有概念之间的对应关系,对于正确使用绑定器和消息中间件会有非常大的帮助。下面就来分别说说RabbitMQ与 Kafka的绑定器是如何使用消息中间件中不同概念来实现消息的生产与消费的。
RabbitMQ绑定器:在 RabbitMQ中, 通过Exchange交换器来实现 Spring CloudStream的主题概念,所以消息通道的输入输出目标映射了 一 个具体的Exchange交换器。 而对于每个消费组, 则会为对t应的Exchange交换器绑定 一 个Queue队列进行消息收发。依赖是:spring-cloud-stream-binder-rabbit
Kafka绑定器: 由于Kafka自身就有Topic概念, 所以 Spring Cloud Stream的主题直接采用了Kafka的Topic 主题概念, 每个消费组的通道目标都会直接连接Kafka的主题进行消息收发。依赖是:spring-cloud-stream-binder-kafka
我们这个Demo里面使用的是 RabiitMQ绑定器。至于Kafka的相关也是类似的。就不详细说明了。
配置详解:
在Spring Cloud Stream中对绑定通道和绑定器提供了通用的属性配置项, 一些绑定器还允许使用附加属性来对消息中间件的 一 些独有特性进行配置。 这些属性的配置可以通过Spring Boot支持的任何配置方式来进行, 包括使用环境变量、 YAML或者properties 配置文件等。
详细的配置可以参考 spring cloud 微服务实战一书。有疑问的欢迎随时留言讨论。
