Kubernetes之Pod的生命周期及Controller相关组件
Lifecycle:
官网:https://kubernetes.io/docs/concepts/workloads/pods/pod-lifecycle/
Pod 的 status 定义在 PodStatus 对象中,其中有一个 phase 字段。Pod 的运行阶段(phase)是 Pod 在其生命周期中的简单宏观概述。该阶段并不是对容器或 Pod 的综合汇总,也不是为了做为综合状态机。Pod 相位的数量和含义是严格指定的。下面是 phase 可能的值:
- 挂起(Pending):Pod 已被 Kubernetes 系统接受,但有一个或者多个容器镜像尚未创建。等待时间包括调度 Pod 的时间和通过网络下载镜像的时间,这可能需要花点时间。
- 运行中(Running):该 Pod 已经绑定到了一个节点上,Pod 中所有的容器都已被创建。至少有一个容器正在运行,或者正处于启动或重启状态。
- 成功(Succeeded):Pod 中的所有容器都被成功终止,并且不会再重启。
- 失败(Failed):Pod 中的所有容器都已终止了,并且至少有一个容器是因为失败终止。也就是说,容器以非0状态退出或者被系统终止。
- 未知(Unknown):因为某些原因无法取得 Pod 的状态,通常是因为与 Pod 所在主机通信失败。
重启策略:
官网:https://kubernetes.io/docs/concepts/workloads/pods/pod-lifecycle/#restart-policy
PodSpec 中有一个 restartPolicy 字段,可能的值为 Always、OnFailure 和 Never。默认为 Always。 restartPolicy 适用于 Pod 中的所有容器。restartPolicy 仅指通过同一节点上的 kubelet 重新启动容器。失败的容器由 kubelet 以五分钟为上限的指数退避延迟(10秒,20秒,40秒…)重新启动,并在成功执行十分钟后重置。一旦绑定到一个节点,Pod 将永远不会重新绑定到另一个节点。
- Always:容器失效时,即重启
- OnFailure:容器终止运行且退出码不为0时重启
- Never:永远不重启
静态Pod:
静态Pod是由kubelet进行管理的,并且存在于特定的Node上。例如kube-apiserver。不能通过API Server进行管理,无法与ReplicationController,Ddeployment或者DaemonSet进行关联,也无法进行健康检查。
健康检查:
官网:https://kubernetes.io/docs/concepts/workloads/pods/pod-lifecycle/#container-probes
探针 是由 kubelet 对容器执行的定期诊断。要执行诊断,kubelet 调用由容器实现的 Handler。有三种类型的处理程序:
- ExecAction:在容器内执行指定命令。如果命令退出时返回码为 0 则认为诊断成功。
- TCPSocketAction:对指定端口上的容器的 IP 地址进行 TCP 检查。如果端口打开,则诊断被认为是成功的。
- HTTPGetAction:对指定的端口和路径上的容器的 IP 地址执行 HTTP Get 请求。如果响应的状态码大于等于200 且小于 400,则诊断被认为是成功的。
每次探测都将获得以下三种结果之一:
- 成功 Success:容器通过了诊断。
- 失败 Failure:容器未通过诊断。
- 未知 Unknown:诊断失败,因此不会采取任何行动。
Kubelet 可以选择是否执行在容器上运行的两种探针执行和做出反应:
livenessProbe:指示容器是否正在运行。如果存活探测失败,则 kubelet 会杀死容器,并且容器将受到其 重启策略 的影响。如果容器不提供存活探针,则默认状态为Success。readinessProbe:指示容器是否准备好服务请求。如果就绪探测失败,端点控制器将从与 Pod 匹配的所有 Service 的端点中删除该 Pod 的 IP 地址。初始延迟之前的就绪状态默认为Failure。如果容器不提供就绪探针,则默认状态为Success。
比如:在containers标签下面定义
livenessProbe: failureThreshold: 3 httpGet: path: /healthz port: 10254 scheme: HTTP initialDelaySeconds: 10 periodSeconds: 10 successThreshold: 1 timeoutSeconds: 10 readinessProbe: failureThreshold: 3 httpGet: path: /healthz port: 10254 scheme: HTTP periodSeconds: 10 successThreshold: 1 timeoutSeconds: 10
ConfigMap:
官网 :https://kubernetes.io/docs/tasks/configure-pod-container/configure-pod-configmap/
ConfigMap 允许您将配置文件与镜像文件分离,以使容器化的应用程序具有可移植性。说白了就是用来保存配置数据的键值对,也可以保存单个属性,也可以保存配置文件。所有的配置内容都存储在etcd中,创建的数据可以供Pod使用。
1.命令行创建:创建一个名称为my-config的ConfigMap,key值时db.port,value值是'3306'
kubectl create configmap my-config --from-literal=db.port='3306'
kubectl get configmap

详情信息:kubectl get configmap myconfig -o yaml
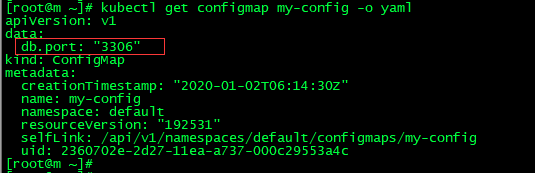
2.从配置文件中创建,创建一个文件,名称为app.properties
name=wuzz age=25
kubectl create configmap app --from-file=./app.properties 创建
kubectl get configmap 查看
kubectl get configmap app -o yaml
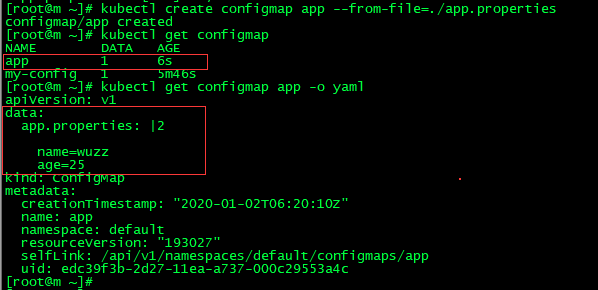
3.从目录中创建,新建 config 目录,在里面创建两个配置文件 a.properties b.properties
kubectl create configmap config --from-file=config/
kubectl get configmap
name=wuzz age=25 --- name=hahahha age=100
kubectl describe configmaps config 查看描述
4.通过yaml文件创建 configmaps.yaml
apiVersion: v1 kind: ConfigMap metadata: name: special-config namespace: default data: special.how: very --- apiVersion: v1 kind: ConfigMap metadata: name: env-config namespace: default data: log_level: INFO
kubectl apply -f configmaps.yaml
kubectl get configmap
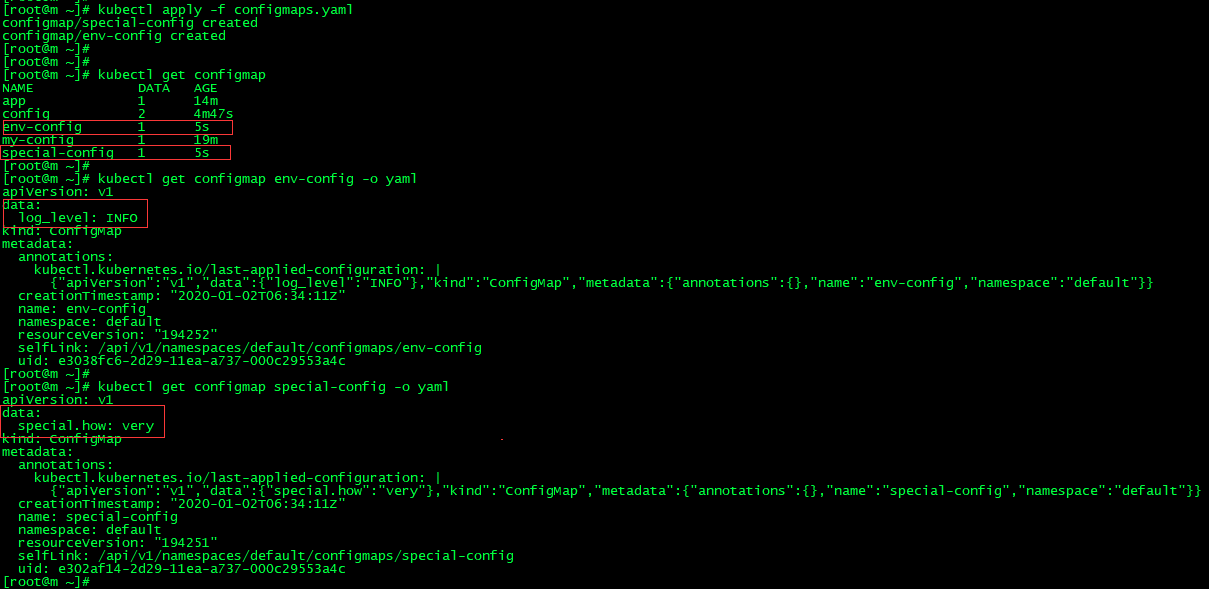
ConfigMap的使用:
- 通过环境变量的方式,直接传递给pod,可以使用configmap中指定的key,也可以使用configmap中所有的key。
- 通过在pod的命令行下运行的方式(启动命令中)。
- 作为volume的方式挂载到pod内。
需要注意的是:
- ConfigMap必须在Pod使用它之前创建。
- 使用envFrom时,将会自动忽略无效的键。
- Pod只能使用同一个命名空间的ConfigMap。
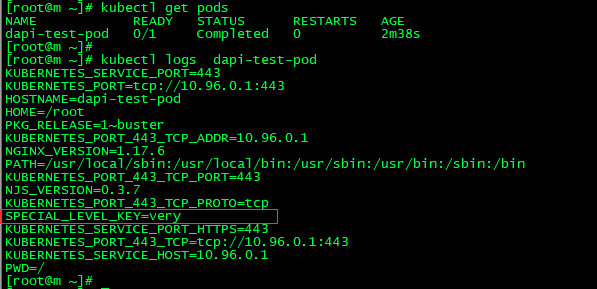
1.通过环境变量使用,创建env-configmap.yaml,使用valueFrom、configMapKeyRef、name。key的话指定要用到的key
kubectl apply -f env-configmap.yaml
由于Command是覆盖容器启动后默认执行的命令,比如在Dockerfile中 一般最后一行CMD 或 ENTRYPOINT的就是了。可这个时候我们Command覆盖了次命令,导致容器推出,状态时Completed
apiVersion: v1 kind: Pod metadata: name: dapi-test-pod spec: containers: - name: nginx image: nginx command: [ "/bin/sh", "-c", "env" ] env: # Define the environment variable - name: SPECIAL_LEVEL_KEY valueFrom: configMapKeyRef: # The ConfigMap containing the value you want to assign to SPECIAL_LEVEL_KEY name: special-config # Specify the key associated with the value key: special.how restartPolicy: Never
kubectl logs pod-name :就能看到效果
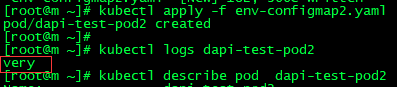
2.用作命令行参数,在命令行下引用时,需要先设置为环境变量,之后可以用过$(VAR_NAME)设置容器启动命令的启动参数,创建env-configmap2.yaml
kubectl apply -f env-configmap2.yaml
apiVersion: v1 kind: Pod metadata: name: dapi-test-pod2 spec: containers: - name: nginx2 image: nginx command: [ "/bin/sh", "-c", "echo $(SPECIAL_LEVEL_KEY)" ] env: - name: SPECIAL_LEVEL_KEY valueFrom: configMapKeyRef: name: special-config key: special.how restartPolicy: Never
kubectl logs dapi-test-pod2:就能看到效果:
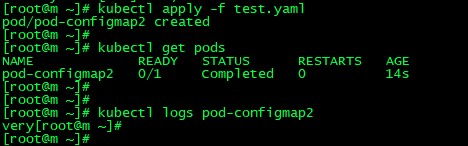
3.作为volume挂载使用,将创建的ConfigMap直接挂载至Pod的/etc/config目录下,其中每一个key-value键值对都会生成一个文件,key为文件名,value为内容。
kubectl apply -f pod-myconfigmap-v2.yml
apiVersion: v1 kind: Pod metadata: name: pod-configmap2 spec: containers: - name: nginx3 image: nginx command: [ "/bin/sh", "-c", "cat /etc/config/special.how" ] volumeMounts: - name: config-volume mountPath: /etc/config volumes: - name: config-volume configMap: name: special-config restartPolicy: Never
当 pod 运行结束后会输出我们配好的configmap的value:
更新 ConfigMap 后:
- 使用该 ConfigMap 挂载的 Env 不会同步更新
- 使用该 ConfigMap 挂载的 Volume 中的数据需要一段时间(实测大概10秒)才能同步更新
ConfigMap在Ingress Controller中实战:
在之前ingress网络中的mandatory.yaml文件中使用了ConfigMap,于是我们可以打开。可以发现有nginx-configuration、tcp-services等名称的cm而且也可以发现最后在容器的参数中使用了这些cm
kind: ConfigMap apiVersion: v1 metadata: name: nginx-configuration namespace: ingress-nginx labels: app.kubernetes.io/name: ingress-nginx app.kubernetes.io/part-of: ingress-nginx --- kind: ConfigMap apiVersion: v1 metadata: name: tcp-services namespace: ingress-nginx labels: app.kubernetes.io/name: ingress-nginx app.kubernetes.io/part-of: ingress-nginx --- kind: ConfigMap apiVersion: v1 metadata: name: udp-services namespace: ingress-nginx labels: app.kubernetes.io/name: ingress-nginx app.kubernetes.io/part-of: ingress-nginx --- args: - /nginx-ingress-controller - --configmap=$(POD_NAMESPACE)/nginx-configuration - --tcp-services-configmap=$(POD_NAMESPACE)/tcp-services - --udp-services-configmap=$(POD_NAMESPACE)/udp-services - --publish-service=$(POD_NAMESPACE)/ingress-nginx - --annotations-prefix=nginx.ingress.kubernetes.io
(1)查看nginx ingress controller的pod部署 kubectl get pods -n ingress-nginx -o wide

(2)发现运行在w1节点上,说明w1上一定有对应的container,来到w1节点 docker ps | grep ingress

(3)不妨进入容器看看?docker exec -it 4e7c88baf14a bash

(4)可以发现,就是一个nginx嘛,而且里面还有nginx.conf文件,不妨打开nginx.conf文件看看,假如已经配置过ingress,不妨尝试搜索一下配置的域名.或者我们创建一个ingress:kubectl apply -f ingress.yaml
#ingress apiVersion: extensions/v1beta1 kind: Ingress metadata: name: nginx-ingress spec: rules: - host: tomcat.wuzz.com http: paths: - path: / backend: serviceName: tomcat-service servicePort: 80
我这里是tomcat.wuzz.com,然后再查看nginx.conf,就会发现我们的配置跑到了这个文件里:
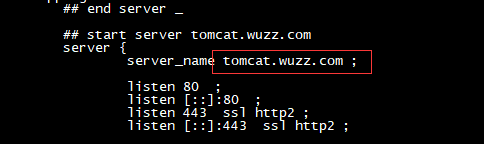
(5)到这里,大家应该有点感觉了,原来nginx ingress controller就是一个nginx,而所谓的ingress.yaml文件中配置的内容像tomcat.wuzz.com就会对应到nginx.conf中。
(6)但是,不可能每次都进入到容器里面来修改,而且还需要手动重启nginx,很麻烦一定会有好事之者来做这件事情,比如在K8s中有对应的方式,修改了什么就能修改nginx.conf文件
(7)先查看一下nginx.conf文件中的内容,比如找个属性:proxy_connect_timeout 5s我们想要将这个属性在K8s中修改成8s,可以吗?
(8)准备一个yaml文件 :
kubectl apply -f nginx-config.yaml
kind: ConfigMap
apiVersion: v1
metadata:
name: nginx-configuration
namespace: ingress-nginx
labels:
app: ingress-nginx
data:
proxy-read-timeout: "228"
kubectl get cm -n ingress-nginx
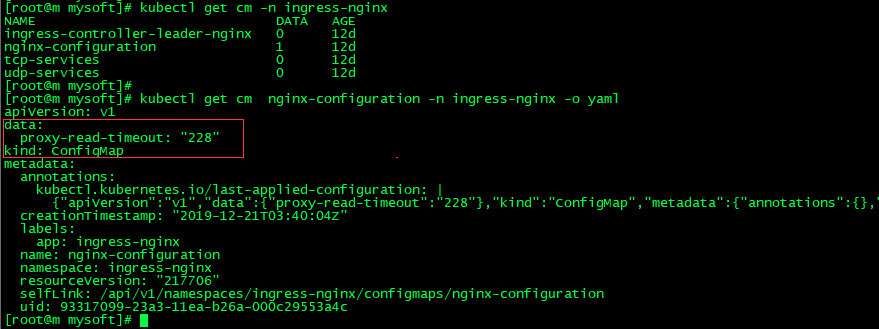
(9)再次查看nginx.conf文件,如我们所料:

(10)其实定义规则都在nginx ingress controller的官网中 https://kubernetes.github.io/ingress-nginx/user-guide/nginx-configuration/
这里还提供了3种方式来供我们自定义配置文件。There are three ways to customize NGINX:
- ConfigMap: using a Configmap to set global configurations in NGINX. 这个就是我们上述的方式,其他具体配置见:https://kubernetes.github.io/ingress-nginx/user-guide/nginx-configuration/configmap/
- Annotations: use this if you want a specific configuration for a particular Ingress rule. 注解的方式。
- Custom template: when more specific settings are required, like open_file_cache, adjust listen options as
rcvbufor when is not possible to change the configuration through the ConfigMap.整个文件替换
Secret:
官网 :https://kubernetes.io/docs/concepts/configuration/secret/
对于 ConfigMap来说是存放明文数据的,安全性不高。Secret 对象类型用来保存敏感信息,例如密码、OAuth 令牌和 ssh key。 将这些信息放在 secret 中比放在 Pod 的定义或者 容器镜像 中来说更加安全和灵活。
Secret类型:
- Opaque:使用base64编码存储信息,可以通过`base64 --decode`解码获得原始数据,因此安全性弱。
- kubernetes.io/dockerconfigjson:用于存储docker registry的认证信息。
- kubernetes.io/service-account-token:用于被 serviceaccount 引用。serviceaccout 创建时 Kubernetes 会默认创建对应的 secret。Pod 如果使用了 serviceaccount,对应的 secret 会自动挂载到 Pod 的 /run/secrets/kubernetes.io/serviceaccount 目录中。
Opaque Secret:Opaque类型的Secret的value为base64位编码后的值
1.从文件中创建
echo -n "admin" > ./username.txt
echo -n "1f2d1e2e67df" > ./password.txt
创建secret :kubectl create secret generic db-user-pass --from-file=./username.txt --from-file=./password.txt
kubectl get secret

2.使用yaml文件创建
(1)对数据进行64位编码,在Linux上输入就能出结果
echo -n 'admin' | base64
echo -n '1f2d1e2e67df' | base64
(2)定义mysecret.yaml文件:
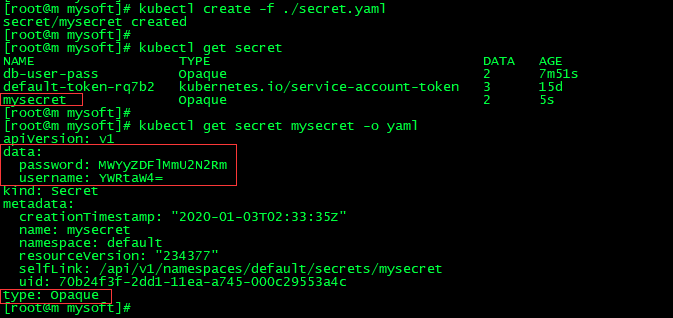
apiVersion: v1 kind: Secret metadata: name: mysecret type: Opaque data: username: YWRtaW4= password: MWYyZDFlMmU2N2Rm
(3)根据yaml文件创建资源并查看
kubectl create -f ./secret.yaml
kubectl get secret
kubectl get secret mysecret -o yaml
Secret使用:
- 以Volume方式
- 以环境变量方式
1.将Secret挂载到Volume中。kubectl apply -f mypod.yaml
apiVersion: v1 kind: Pod metadata: name: mypod spec: containers: - name: mypod image: redis volumeMounts: - name: foo mountPath: "/etc/foo" readOnly: true volumes: - name: foo secret: secretName: mysecret
kubectl apply -f mypod.yaml 创建
kubectl exec -it pod-name bash 进入容器
ls /etc/foo 查看
cat /etc/foo/username
cat /etc/foo/password 我们会得到我们的预期效果,他会帮我们进行解码后保存到文件。

2.将Secret设置为环境变量,而这个其实是跟configmap是一样的操作:
apiVersion: v1 kind: Pod metadata: name: secret-env-pod spec: containers: - name: mycontainer image: redis env: - name: SECRET_USERNAME valueFrom: secretKeyRef: name: mysecret key: username - name: SECRET_PASSWORD valueFrom: secretKeyRef: name: mysecret key: password restartPolicy: Never
kubernetes.io/dockerconfigjson
kubernetes.io/dockerconfigjson用于存储docker registry的认证信息,可以直接使用 kubectl create secret 命令创建
kubernetes.io/service-account-token
用于被 serviceaccount 引用。serviceaccout 创建时 Kubernetes 会默认创建对应的 secret。Pod 如果使用了 serviceaccount,对应的secret 会自动挂载到 Pod 的 /run/secrets/kubernetes.io/serviceaccount 目录中。
kubectl get secret # 可以看到service-account-token kubectl run nginx --image nginx kubectl get pods kubectl exec -it nginx-pod-name bash ls /run/secrets/kubernetes.io/serviceaccount kubectl get secret kubectl get pods pod-name -o yaml # 找到volumes选项,定位到-name,secretName # 找到volumeMounts选项,定位到mountPath: /var/run/secrets/kubernetes.io/serviceaccount
无论是ConfigMap,Secret,还是DownwardAPI,都是通过ProjectedVolume实现的,可以通过APIServer将信息放到Pod中进行使用。
Controller进阶学习之路:
既然学习了Pod进阶,对于管理Pod的Controller肯定也要进阶一下,之前我们已经学习过的Controller有RC、RS和Deployment,除此之外还有吗?
官网 :https://kubernetes.io/docs/concepts/architecture/controller/
Job:
官网 :https://kubernetes.io/docs/concepts/workloads/controllers/jobs-run-to-completion/
对于RS,RC之类的控制器,能够保持Pod按照预期数目持久地运行下去,它们针对的是持久性的任务,比如web服务。而有些操作其实不需要持久,比如压缩文件,我们希望任务完成之后,Pod就结束运行,不需要保持在系统中,此时就需要用到Job。所以可以这样理解,Job是对RS、RC等持久性控制器的补充。负责批量处理短暂的一次性任务,仅执行一次,并保证处理的一个或者多个Pod成功结束。
job创建一个或多个pod,并确保指定数量的pod成功终止。当pods成功完成时,job跟踪成功完成的情况。当达到指定数量的成功完成时,任务(即作业)就完成了。删除作业将清理它创建的pod。一个简单的例子是创建一个作业对象,以便可靠地运行一个Pod直至完成。如果第一个Pod失败或被删除(例如由于节点硬件故障或节点重新启动),作业对象将启动一个新的Pod。
1.定义一个 job 的yaml 文件:
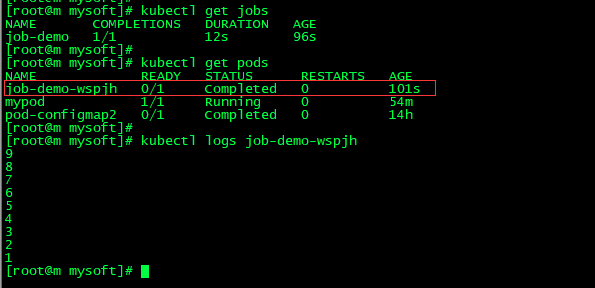
apiVersion: batch/v1 kind: Job metadata: name: job-demo spec: template: metadata: name: job-demo spec: restartPolicy: Never containers: - name: counter image: busybox command: - "bin/sh" - "-c" - "for i in 9 8 7 6 5 4 3 2 1; do echo $i; done"
kubectl apply -f job.yaml
kubectl describe jobs/pi
kubectl logs pod-name 可以发现这个job已经成功执行了。
- 非并行Job:
- 通常只运行一个Pod,Pod成功结束Job就退出。
- 固定完成次数的并行Job:
- 并发运行指定数量的Pod,直到指定数量的Pod成功,Job结束。
- 带有工作队列的并行Job:
- 用户可以指定并行的Pod数量,当任何Pod成功结束后,不会再创建新的Pod
- 一旦有一个Pod成功结束,并且所有的Pods都结束了,该Job就成功结束。
- 一旦有一个Pod成功结束,其他Pods都会准备退出。
CronJob:
官网 :https://kubernetes.io/docs/concepts/workloads/controllers/cron-jobs/
Cron作业按照基于时间的计划创建作业。一个CronJob对象就像crontab (cron表)文件的一行。它按照给定的计划定期运行作业,以Cron格式编写。cronJob是基于时间进行任务的定时管理。在特定的时间点运行任务,反复在指定的时间点运行任务:比如定时进行数据库备份,定时发送电子邮件等等。
apiVersion: batch/v1beta1 kind: CronJob metadata: name: hello spec: schedule: "*/1 * * * *" jobTemplate: spec: template: spec: containers: - name: hello image: busybox args: - /bin/sh - -c - date; echo Hello from the Kubernetes cluster restartPolicy: OnFailure
kubectl create -f ./cronjob.yaml
kubectl get cronjob hello
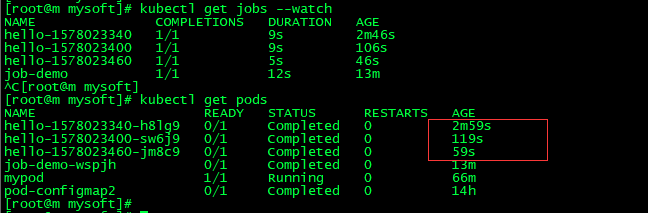
kubectl get jobs --watch
kubectl logs $pods
从命令返回结果看到的那样,CronJob 还没有调度或执行任何任务。大约需要一分钟任务才能创建好。
StatefulSet:
官网 :https://kubernetes.io/docs/concepts/workloads/controllers/statefulset/
StatefulSet 是用来管理有状态应用的工作负载 API 对象。StatefulSet 用来管理 Deployment 和扩展一组 Pod,并且能为这些 Pod 提供*序号和唯一性保证。和 Deployment 相同的是,StatefulSet 管理了基于相同容器定义的一组 Pod。但和 Deployment 不同的是,StatefulSet 为它们的每个 Pod 维护了一个固定的 ID。这些 Pod 是基于相同的声明来创建的,但是不能相互替换:无论怎么调度,每个 Pod 都有一个永久不变的 ID。
之前接触的Pod的管理对象比如RC、Deployment和Job都是面向无状态的服务,但是现实中有很多服务是有状态的,比如MySQL集群、MongoDB集群、ZK集群等,它们都有以下共同的特点:
- 每个节点都有固定的ID,通过该ID,集群中的成员可以互相发现并且通信
- 集群的规模是比较固定的,集群规模不能随意变动
- 集群里的每个节点都是有状态的,通常会持久化数据到永久存储中
- 如果磁盘损坏,则集群里的某个节点无法正常运行,集群功能受损
而之前的RC/Deployment没办法满足要求,所以从Kubernetes v1.4版本就引入了PetSet资源对象,在v1.5版本时更名为StatefulSet。从本质上说,StatefulSet可以看作是Deployment/RC对象的特殊变种
- StatefulSet里的每个Pod都有稳定、唯一的网络标识,可以用来发现集群内其他的成员
- Pod的启动顺序是受控的,操作第n个Pod时,前n-1个Pod已经是运行且准备好的状态
- StatefulSet里的Pod采用稳定的持久化存储卷,通过PV/PVC来实现,删除Pod时默认不会删除与StatefulSet相关的存储卷
- StatefulSet需要与Headless Service配合使用
准备 yaml 文件:
# 定义Service apiVersion: v1 kind: Service metadata: name: nginx labels: app: nginx spec: ports: - port: 80 name: web clusterIP: None selector: app: nginx --- # 定义StatefulSet apiVersion: apps/v1 kind: StatefulSet metadata: name: web spec: selector: matchLabels: app: nginx serviceName: "nginx" replicas: 3 template: metadata: labels: app: nginx spec: terminationGracePeriodSeconds: 10 containers: - name: nginx image: nginx ports: - containerPort: 80 name: web
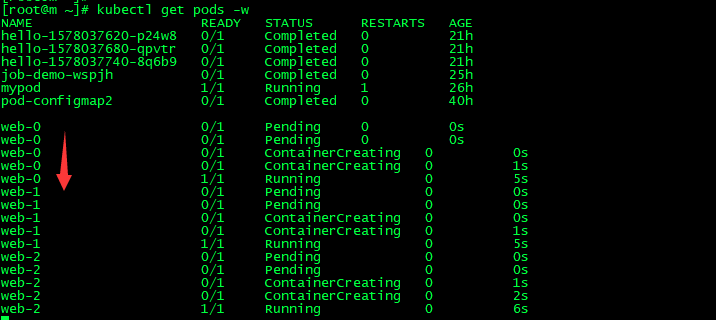
kubectl apply -f statefulset.yaml
kubectl get pods -w 可以看出他是按照顺序给我们创建的,而且是带编号的。
DaemonSet:
官网 :https://kubernetes.io/docs/concepts/workloads/controllers/daemonset/
DaemonSet 确保全部(或者某些)节点上运行一个 Pod 的副本。当有节点加入集群时, 也会为他们新增一个 Pod 。当有节点从集群移除时,这些 Pod 也会被回收。删除 DaemonSet 将会删除它创建的所有 Pod。
DaemonSet应用场景:
- 运行集群存储 daemon,例如在每个节点上运行 glusterd 、 ceph 。
- 在每个节点上运行日志收集 daemon,例如 fluentd 、 logstash 。
- 在每个节点上运行监控 daemon,例如 Prometheus Node Exporter、 collectd 、Datadog 代理、New Relic 代理,或 Ganglia gmond 。
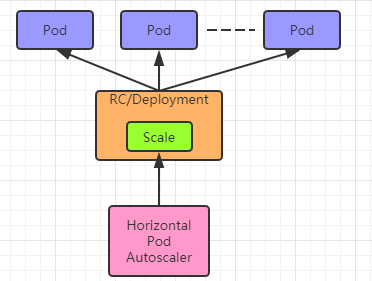
Horizontal Pod Autoscaler:
官网 :https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/
Pod 水平自动伸缩(Horizontal Pod Autoscaler)特性, 可以基于CPU利用率自动伸缩 replication controller、deployment和 replica set 中的 pod 数量,(除了 CPU 利用率)也可以 基于其他应程序提供的度量指标custom metrics。 pod 自动缩放不适用于无法缩放的对象,比如 DaemonSets。Pod 水平自动伸缩特性由 Kubernetes API 资源和控制器实现。资源决定了控制器的行为。 控制器会周期性的获取平均 CPU 利用率,并与目标值相比较后来调整 replication controller 或 deployment 中的副本数量。
前期准备:
apiVersion: apps/v1 kind: Deployment metadata: name: nginx-deployment labels: app: nginx spec: replicas: 3 selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx ports: - containerPort: 80
(1)创建hpa
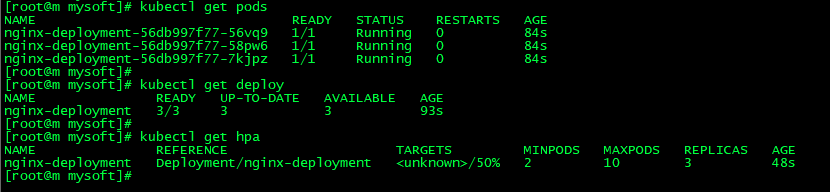
使nginx pod的数量介于2和10之间,CPU使用率维持在50%:kubectl autoscale deployment nginx-deployment --min=2 --max=10 --cpu-percent=50
(2)查看所有创建的资源
kubectl get pods
kubectl get deploy
kubectl get hpa
(3)修改replicas值为1或者11。可以发现最终最小还是2,最大还是10
kubectl edit deployment nginx-deployment
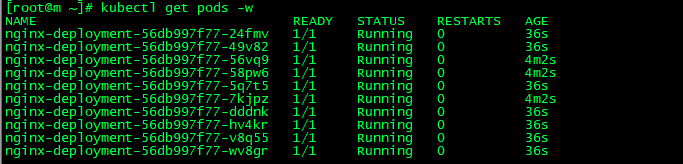
(4)再次理解什么是hpa
Horizontal Pod Autoscaling可以根据CPU使用率或应用自定义metrics自动扩展Pod数量(支持replication controller、deployment和replica set)
- 控制管理器每隔30s查询metrics的资源使用情况
- 通过kubectl创建一个horizontalPodAutoscaler对象,并存储到etcd中
- APIServer:负责接受创建hpa对象,然后存入etcd
Resource:
官网 :https://kubernetes.io/docs/concepts/configuration/manage-compute-resources-container/
因为K8S的最小操作单元是Pod,所以这里主要讨论的是Pod的资源。在K8S的集群中,Node节点的资源信息会上报给APIServer。requests&limits。可以通过这两个属性设置cpu和内存
当您定义 Pod 的时候可以选择为每个容器指定需要的 CPU 和内存(RAM)大小。当为容器指定了资源请求后,调度器就能够更好的判断出将容器调度到哪个节点上。如果您还为容器指定了资源限制,Kubernetes 就可以按照指定的方式来处理节点上的资源竞争。
apiVersion: v1 kind: Pod metadata: name: frontend spec: containers: - name: db image: mysql env: - name: MYSQL_ROOT_PASSWORD value: "password" resources: requests: memory: "64Mi" cpu: "250m" limits: memory: "128Mi" cpu: "500m" - name: wp image: wordpress resources: requests: memory: "64Mi" cpu: "250m" limits: memory: "128Mi" cpu: "500m
Dashboard:
官网 :https://kubernetes.io/docs/tasks/access-application-cluster/web-ui-dashboard/
Dashboard 是基于网页的 Kubernetes 用户界面。您可以使用 Dashboard 将容器应用部署到 Kubernetes 集群中,也可以对容器应用排错,还能管理集群资源。您可以使用 Dashboard 获取运行在集群中的应用的概览信息,也可以创建或者修改 Kubernetes 资源(如 Deployment,Job,DaemonSet 等等)。例如,您可以对 Deployment 实现弹性伸缩、发起滚动升级、重启 Pod 或者使用向导创建新的应用。Dashboard 同时展示了 Kubernetes 集群中的资源状态信息和所有报错信息。
(1)根据yaml文件创建资源:
apiVersion: v1
kind: ConfigMap
metadata:
labels:
k8s-app: kubernetes-dashboard
# Allows editing resource and makes sure it is created first.
addonmanager.kubernetes.io/mode: EnsureExists
name: kubernetes-dashboard-settings
namespace: kube-system
---
apiVersion: v1
kind: ServiceAccount
metadata:
labels:
k8s-app: kubernetes-dashboard
addonmanager.kubernetes.io/mode: Reconcile
name: kubernetes-dashboard
namespace: kube-system
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: kubernetes-dashboard
namespace: kube-system
labels:
k8s-app: kubernetes-dashboard
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
spec:
selector:
matchLabels:
k8s-app: kubernetes-dashboard
template:
metadata:
labels:
k8s-app: kubernetes-dashboard
annotations:
scheduler.alpha.kubernetes.io/critical-pod: ''
seccomp.security.alpha.kubernetes.io/pod: 'docker/default'
spec:
priorityClassName: system-cluster-critical
containers:
- name: kubernetes-dashboard
image: k8s.gcr.io/kubernetes-dashboard-amd64:v1.8.3
resources:
limits:
cpu: 100m
memory: 300Mi
requests:
cpu: 50m
memory: 100Mi
ports:
- containerPort: 8443
protocol: TCP
args:
# PLATFORM-SPECIFIC ARGS HERE
- --auto-generate-certificates
volumeMounts:
- name: kubernetes-dashboard-certs
mountPath: /certs
- name: tmp-volume
mountPath: /tmp
livenessProbe:
httpGet:
scheme: HTTPS
path: /
port: 8443
initialDelaySeconds: 30
timeoutSeconds: 30
volumes:
- name: kubernetes-dashboard-certs
secret:
secretName: kubernetes-dashboard-certs
- name: tmp-volume
emptyDir: {}
serviceAccountName: kubernetes-dashboard
tolerations:
- key: "CriticalAddonsOnly"
operator: "Exists"
---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
labels:
k8s-app: kubernetes-dashboard
addonmanager.kubernetes.io/mode: Reconcile
name: kubernetes-dashboard-minimal
namespace: kube-system
rules:
# Allow Dashboard to get, update and delete Dashboard exclusive secrets.
- apiGroups: [""]
resources: ["secrets"]
resourceNames: ["kubernetes-dashboard-key-holder", "kubernetes-dashboard-certs"]
verbs: ["get", "update", "delete"]
# Allow Dashboard to get and update 'kubernetes-dashboard-settings' config map.
- apiGroups: [""]
resources: ["configmaps"]
resourceNames: ["kubernetes-dashboard-settings"]
verbs: ["get", "update"]
# Allow Dashboard to get metrics from heapster.
- apiGroups: [""]
resources: ["services"]
resourceNames: ["heapster"]
verbs: ["proxy"]
- apiGroups: [""]
resources: ["services/proxy"]
resourceNames: ["heapster", "http:heapster:", "https:heapster:"]
verbs: ["get"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: kubernetes-dashboard-minimal
namespace: kube-system
labels:
k8s-app: kubernetes-dashboard
addonmanager.kubernetes.io/mode: Reconcile
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: kubernetes-dashboard-minimal
subjects:
- kind: ServiceAccount
name: kubernetes-dashboard
namespace: kube-system
---
apiVersion: v1
kind: Secret
metadata:
labels:
k8s-app: kubernetes-dashboard
# Allows editing resource and makes sure it is created first.
addonmanager.kubernetes.io/mode: EnsureExists
name: kubernetes-dashboard-certs
namespace: kube-system
type: Opaque
---
apiVersion: v1
kind: Secret
metadata:
labels:
k8s-app: kubernetes-dashboard
# Allows editing resource and makes sure it is created first.
addonmanager.kubernetes.io/mode: EnsureExists
name: kubernetes-dashboard-key-holder
namespace: kube-system
type: Opaque
---
apiVersion: v1
kind: Service
metadata:
name: kubernetes-dashboard
namespace: kube-system
labels:
k8s-app: kubernetes-dashboard
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
spec:
selector:
k8s-app: kubernetes-dashboard
ports:
- port: 443
targetPort: 8443
nodePort: 30018
type: NodePort
该文件分为以下几部分:
- Dashboard Service .
- Dashboard Deployment。
- Dashboard Role:定义了Dashboard 的角色,其角色名称为
kubernetes-dashboard-minimal,rules中清晰的列出了其拥有的多个权限。通过名称我们可以猜到,这个权限级别是比较低的。 - RoleBinding:定义了Dashboard的角色绑定,其名称为
kubernetes-dashboard-minimal,roleRef中为被绑定的角色,也叫kubernetes-dashboard-minimal,subjects中为绑定的用户:kubernetes-dashboard。 - Dashboard Service Account:定义了Dashboard的用户,其类型为
ServiceAccount,名称为kubernetes-dashboard。 - Dashboard Secret。
(1)根据yaml文件创建资源
kubectl apply -f dashboard.yaml
(2)查看资源
kubectl get pods -n kube-system
kubectl get pods -n kube-system -o wide
kubectl get svc -n kube-system
kubectl get deploy kubernetes-dashboard -n kube-system

(3)生成登录需要的token
# 创建service account kubectl create sa dashboard-admin -n kube-system # 创建角色绑定关系 kubectl create clusterrolebinding dashboard-admin --clusterrole=cluster-admin --serviceaccount=kube-system:dashboard-admin # 查看dashboard-admin的secret名字 ADMIN_SECRET=$(kubectl get secrets -n kube-system | grep dashboard-admin | awk '{print $1}')
echo ADMIN_SECRET # 打印secret的token kubectl describe secret -n kube-system ${ADMIN_SECRET} | grep -E '^token' | awk '{print $2}'
(4)使用火狐浏览器访问
https://192.168.1.101:30018/

输入token即可