



RocketMQ事务性消息及持久化
TransactionProducer(事务消息):
在分布式系统中,我们时常会遇到分布式事务的问题,除了常规的解决方案之外,我们还可以利用RocketMQ的事务性消息来解决分布式事务的问题。RocketMQ和其他消息中间件最大的一个区别是支持了事务消息,这也是分布式事务里面的基于消息的最终一致性方案。
RocketMQ消息的事务架构设计:
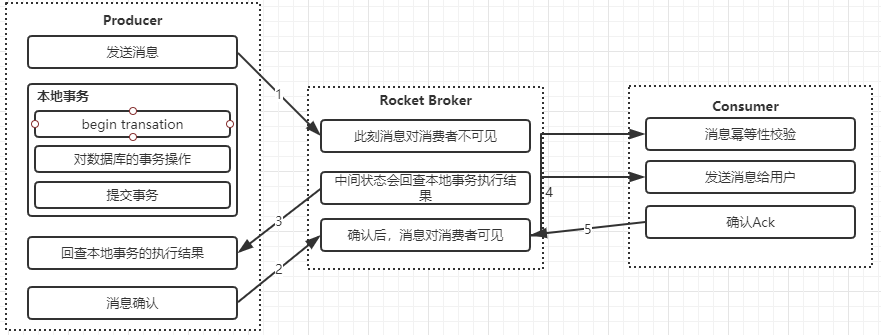
- 生产者执行本地事务,修改订单支付状态
- 生产者发送事务消息到broker上,消息发送到broker上在没有确认之前,消息对于consumer是不可见状态
- 生产者确认事务消息,broker 确定是事务状态,校验通过生产者提交事务。使得发送到broker上的事务消息对于消费者可见
- 消费者获取到消息进行消费,消费完之后执行ack进行确认
这里可能会存在一个问题,生产者本地事务成功后,发送事务确认消息到broker上失败了怎么办?这个时候意味着消费者无法正常消费到这个消息。所以RocketMQ提供了消息回查机制,如果事务消息一直处于中间状态,broker会发起重试去查询broker上这个事务的处理状态。一旦发现事务处理成功,则把当前这条消息设置为可见。
RocketMQ事务消息的实践:
生产者producer:
public class TransactionProducer { public static void main(String[] args) throws MQClientException, UnsupportedEncodingException, InterruptedException { TransactionMQProducer transactionMQProducer=new TransactionMQProducer("tx_producer"); transactionMQProducer.setNamesrvAddr("192.168.1.101:9876;192.168.1.102:9876"); ExecutorService executorService= Executors.newFixedThreadPool(10); transactionMQProducer.setExecutorService(executorService); transactionMQProducer.setTransactionListener(new TransactionListenerLocal()); //本地事务的监听 transactionMQProducer.start(); for(int i=0;i<10;i++){ String orderId= UUID.randomUUID().toString(); String body="{'operation':'doOrder','orderId':'"+orderId+"'}"; Message message=new Message("testTopic2", null,orderId,body.getBytes(RemotingHelper.DEFAULT_CHARSET)); transactionMQProducer.sendMessageInTransaction(message,orderId); Thread.sleep(1000); } } }
TransactionListenerLocal:
public class TransactionListenerLocal implements TransactionListener { private Map<String,Boolean> results=new ConcurrentHashMap<>(); //执行本地事务 @Override public LocalTransactionState executeLocalTransaction(Message message, Object o) { System.out.println("开始执行本地事务:"+o.toString()); //o String orderId=o.toString(); //模拟数据库保存(成功/失败) boolean result=Math.abs(Objects.hash(orderId))%2==0; if(!result) { results.put(orderId, result); // } return result? LocalTransactionState.COMMIT_MESSAGE: LocalTransactionState.UNKNOW; } //提供给事务执行状态检查的回调方法,给broker用的(异步回调) //如果回查失败,消息就丢弃 @Override public LocalTransactionState checkLocalTransaction(MessageExt messageExt) { String orderId=messageExt.getKeys(); System.out.println("执行事务回调检查: orderId:"+orderId); if(results.size()==0){ return LocalTransactionState.COMMIT_MESSAGE; } return LocalTransactionState.COMMIT_MESSAGE; } }
消费端 consumer:
public class TransactionConsumer { //rocketMQ 除了在同一个组和不同组之间的消费者的特性和kafka相同之外 //RocketMQ可以支持广播消息,就意味着,同一个group的每个消费者都可以消费同一个消息 public static void main(String[] args) throws MQClientException { DefaultMQPushConsumer defaultMQPushConsumer= new DefaultMQPushConsumer("tx_consumer"); defaultMQPushConsumer.setNamesrvAddr("192.168.1.101:9876;192.168.1.102:9876"); defaultMQPushConsumer.setConsumeFromWhere(ConsumeFromWhere.CONSUME_FROM_FIRST_OFFSET); //subExpression 可以支持sql的表达式. or and a=? ,,, defaultMQPushConsumer.subscribe("testTopic2","*"); defaultMQPushConsumer.registerMessageListener(new MessageListenerConcurrently() { @Override public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> list, ConsumeConcurrentlyContext consumeConcurrentlyContext) { list.stream().forEach(message->{ System.out.println("开始业务处理逻辑:消息体:"+new String(message.getBody())+"->key:"+message.getKeys()); }); return ConsumeConcurrentlyStatus.CONSUME_SUCCESS; //签收 } }); defaultMQPushConsumer.start(); } }
RocketMQ事务消息的三种状态:
- ROLLBACK_MESSAGE:回滚事务
- COMMIT_MESSAGE: 提交事务
- UNKNOW: broker会定时的回查Producer消息状态,直到彻底成功或失败。
当executeLocalTransaction方法返回ROLLBACK_MESSAGE时,表示直接回滚事务,当返回COMMIT_MESSAGE提交事务当返回UNKNOW时,Broker会在一段时间之后回查checkLocalTransaction,根据checkLocalTransaction返回状态执行事务的操作(回滚或提交),如示例中,当返回ROLLBACK_MESSAGE时消费者不会收到消息,且不会调用回查函数,当返回COMMIT_MESSAGE时事务提交,消费者收到消息,当返回UNKNOW时,在一段时间之后调用回查函数,并根据status判断返回提交或回滚状态,返回提交状态的消息将会被消费者消费,所以此时消费者可以消费部分消息
消息的存储和发送:
由于分布式消息队列对于可靠性的要求比较高,所以需要保证生产者将消息发送到broker之后,保证消息是不出现丢失的,因此消息队列就少不了对于可靠性存储的要求
从主流的几种MQ消息队列采用的存储方式来看,主要会有三种
- 分布式KV存储,比如ActiveMQ中采用的levelDB、Redis, 这种存储方式对于消息读写能力要求不高的情况下可以使用
- 文件系统存储,常见的比如kafka、RocketMQ、RabbitMQ都是采用消息刷盘到所部署的机器上的文件系统来做持久化,这种方案适合对于有高吞吐量要求的消息中间件,因为消息刷盘是一种高效率,高可靠、高性能的持久化方式,除非磁盘出现故障,否则一般是不会出现无法持久化的问题
- 关系型数据库,比如ActiveMQ可以采用mysql作为消息存储,关系型数据库在单表数据量达到千万级的情况下IO性能会出现瓶颈,所以ActiveMQ并不适合于高吞吐量的消息队列场景。总的来说,对于存储效率,文件系统要优于分布式KV存储,分布式KV存储要优于关系型数据库
消息的存储结构:
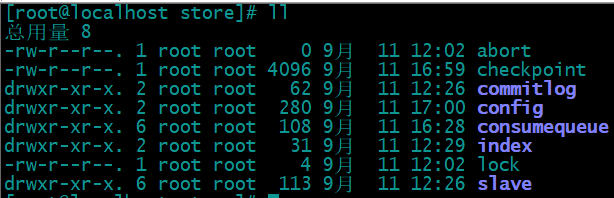
RocketMQ就是采用文件系统的方式来存储消息,消息的存储是由ConsumeQueue和CommitLog配合完成的。CommitLog是消息真正的物理存储文件。ConsumeQueue是消息的逻辑队列,有点类似于数据库的索引文件,里面存储的是指向CommitLog文件中消息存储的地址。每个Topic下的每个Message Queue都会对应一个ConsumeQueue文件,文件的地址是:${store_home}/consumequeue/${topicNmae}/${queueId}/${filename}, 默认路径: /root/store在rocketMQ的文件存储目录下,可以看到这样一个结构的的而文件。
CommitLog:
CommitLog是用来存放消息的物理文件,每个broker上的commitLog本当前机器上的所有consumerQueue共享,不做任何的区分。CommitLog中的文件默认大小为1G,可以动态配置; 当一个文件写满以后,会生成一个新的commitlog文件。所有的Topic数据是顺序写入在CommitLog文件中的。文件名的长度为20位,左边补0,剩余未起始偏移量,比如00000000000000000000 表示第一个文件, 文件大小为102410241024,当第一个文件写满之后,生成第二个文件000000000001073741824 表示第二个文件,起始偏移量为1073741824。
ConsumeQueue:
consumeQueue表示消息消费的逻辑队列,这里面包含MessageQueue在commitlog中的其实物理位置偏移量offset,消息实体内容的大小和Message Tag的hash值。对于实际物理存储来说,consumeQueue对应每个topic和queueid下的文件,每个consumeQueue类型的文件也是有大小,每个文件默认大小约为600W个字节,如果文件满了后会也会生成一个新的文件。
IndexFile:
索引文件,如果一个消息包含Key值的话,会使用IndexFile存储消息索引。Index索引文件提供了对CommitLog进行数据检索,提供了一种通过key或者时间区间来查找CommitLog中的消息的方法。在物理存储中,文件名是以创建的时间戳明明,固定的单个IndexFile大小大概为400M,一个IndexFile可以保存2000W个索引。
abort:
broker在启动的时候会创建一个空的名为abort的文件,并在shutdown时将其删除,用于标识进程是否正常退出,如果不正常退出,会在启动时做故障恢复。
Config:

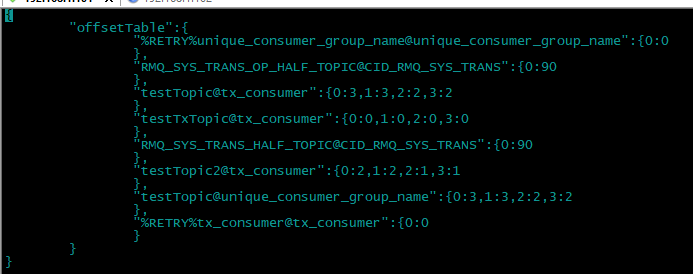
可以看到这个里面保存了 消费端consumer的偏移量:
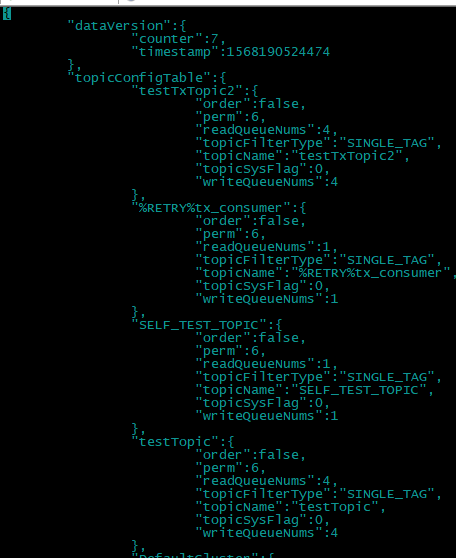
以及topic的一些配置信息:
消息存储的整体结构:

RocketMQ的消息存储采用的是混合型的存储结构,也就是Broker单个实例下的所有队列公用一个日志数据文件CommitLog。这个是和Kafka又一个不同之处。为什么不采用kafka的设计,针对不同的partition存储一个独立的物理文件呢?这是因为在kafka的设计中,一旦kafka中Topic的Partition数量过多,队列文件会过多,那么会给磁盘的IO读写造成比较大的压力,也就造成了性能瓶颈。所以RocketMQ进行了优化,消息主题统一存储在CommitLog中。当然它也有它的优缺点
- 优点在于:由于消息主题都是通过CommitLog来进行读写,ConsumerQueue中只存储很少的数据,所以队列更加轻量化。对于磁盘的访问是串行化从而避免了磁盘的竞争
- 缺点在于:消息写入磁盘虽然是基于顺序写,但是读的过程确是随机的。读取一条消息会先读取ConsumeQueue,再读CommitLog,会降低消息读的效率。
消息发送到消息接收的整体流程:
1. Producer将消息发送到Broker后,Broker会采用同步或者异步的方式把消息写入到CommitLog。RocketMQ所有的消息都会存放在CommitLog中,为了保证消息存储不发生混乱,对CommitLog写之前会加锁,同时也可以使得消息能够被顺序写入到CommitLog,只要消息被持久化到磁盘文件CommitLog,那么就可以保证Producer发送的消息不会丢失。
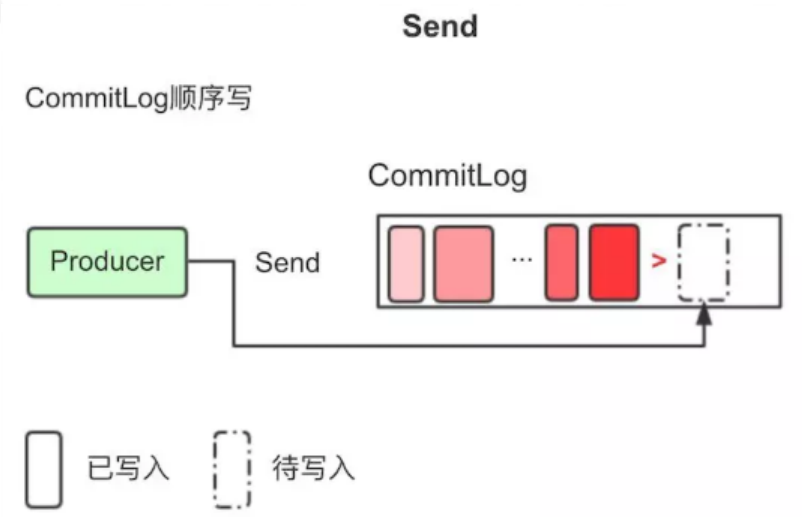
2. commitLog持久化后,会把里面的消息Dispatch到对应的Consume Queue上,Consume Queue相当于kafka中的partition,是一个逻辑队列,存储了这个Queue在CommiLog中的起始offset,log大小和MessageTag的hashCode。

3. 当消费者进行消息消费时,会先读取consumerQueue , 逻辑消费队列ConsumeQueue保存了指定Topic下的队列消息在CommitLog中的起始物理偏移量Offset,消息大小、和消息Tag的HashCode值
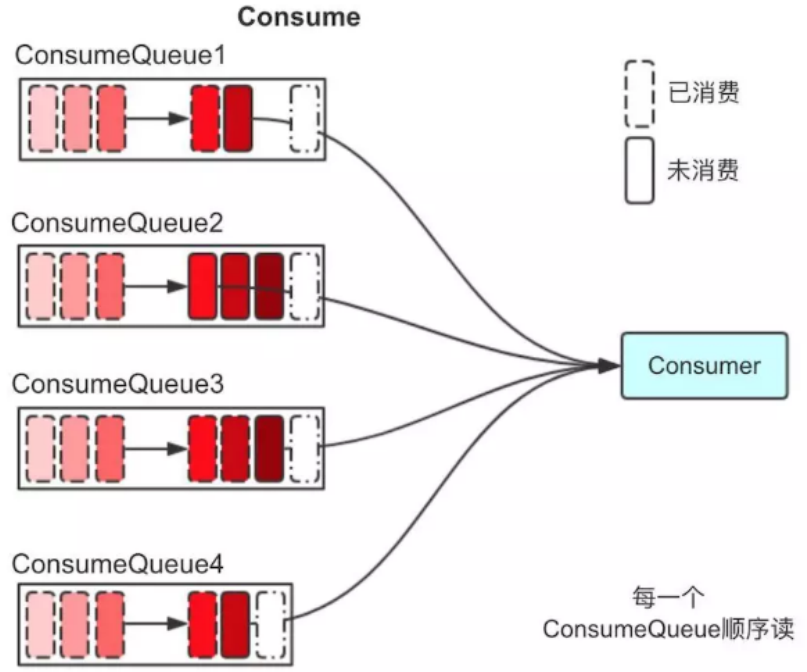
4. 直接从consumequeue中读取消息是没有数据的,真正的消息主体在commitlog中,所以还需要从commitlog中读取消息

什么时候清理物理消息文件?那消息文件到底删不删,什么时候删?
消息存储在CommitLog之后,的确是会被清理的,但是这个清理只会在以下任一条件成立才会批量删除消息文件(CommitLog):
- 消息文件过期(默认48小时),且到达清理时点(默认是凌晨4点),删除过期文件。
- 消息文件过期(默认48小时),且磁盘空间达到了水位线(默认75%),删除过期文件。
- 磁盘已经达到必须释放的上限(85%水位线)的时候,则开始批量清理文件(无论是否过期),直到空间充足。
注:若磁盘空间达到危险水位线(默认90%),出于保护自身的目的,broker会拒绝写入服务。

