


Netty编码的艺术
Netty 编码器原理和数据输出:
Netty 默认提供了丰富的编解码框架供用户集成使用,我们只对较常用的Java 序列化编码器进行讲解。其它的编码器,实现方式大同小异。其实编码器和解码器比较类似, 编码器也是一个handler, 并且属于outbounfHandle, 就是将准备发出去的数据进行拦截, 拦截之后进行相应的处理之后再次进发送处理, 如果理解了解码器, 那么编码器的相关内容理解起来也比较容易。
我们在前面的章节学习Pipeline 的时候, 讲解了write 事件的传播过程, 但在实际使用的时候, 我们通常不会调用channel 的write 方法, 因为该方法只会写入到发送数据的缓存中, 并不会直接写入channel 中, 如果想写入到channel中, 还需要调用flush 方法。实际使用过程中, 我们用的更多的是writeAndFlush()方法, 这方法既能将数据写到发送缓存中, 也能刷新到channel 中。我们看一个最简单的使用的场景:
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception { ctx.channel().writeAndFlush("test data"); }
这个地方小伙伴们肯定不陌生,通过这种方式,可以将数据发送到channel 中, 对方可以收到响应。简单回顾一下跟到writeAndFlush()方法中, 首先会走到AbstractChannel 的writeAndFlush()方法:
public ChannelFuture writeAndFlush(Object msg) { return pipeline.writeAndFlush(msg); }
继续跟到DefualtChannelPipeline 中的writeAndFlush()方法中:
public final ChannelFuture writeAndFlush(Object msg) { return tail.writeAndFlush(msg); }
这里我们看到, writeAndFlush 是从tail 节点进行传播, 有关事件传播, 我们在Pipeline 中进行过剖析, 相信这个不会陌生。继续跟, 会跟到AbstractChannelHandlerContext 中的writeAndFlush()方法:
public ChannelFuture writeAndFlush(Object msg, ChannelPromise promise) { if (msg == null) { throw new NullPointerException("msg"); } if (!validatePromise(promise, true)) { ReferenceCountUtil.release(msg); // cancelled return promise; } write(msg, true, promise); return promise; }
继续跟write()方法:
private void write(Object msg, boolean flush, ChannelPromise promise) {
//findContextOutbound()寻找前一个outbound 节点
//最后到head 节点结束 AbstractChannelHandlerContext next = findContextOutbound(); final Object m = pipeline.touch(msg, next); EventExecutor executor = next.executor(); if (executor.inEventLoop()) { if (flush) { next.invokeWriteAndFlush(m, promise); } else {//没有调flush next.invokeWrite(m, promise); } } else { AbstractWriteTask task; if (flush) { task = WriteAndFlushTask.newInstance(next, m, promise); } else { task = WriteTask.newInstance(next, m, promise); } safeExecute(executor, task, promise, m); } }
这里的逻辑我们也不陌生, 找到下一个节点, 因为writeAndFlush 是从tail 节点开始的, 并且是outBound 的事件, 所以这里会找到tail 节点的上一个outBoundHandler, 有可能是编码器, 也有可能是我们业务处理的handler 。if(executor.inEventLoop()) 判断是否是eventLoop 线程, 如果不是, 则封装成task 通过nioEventLoop 异步执行, 我们这里先按照是eventLoop 线程分析。首先, 这里通过flush 判断是否调用了flush, 这里显然是true, 因为我们调用的方法是writeAndFlush()方法,我们跟到invokeWriteAndFlush 中:
private void invokeWriteAndFlush(Object msg, ChannelPromise promise) { if (invokeHandler()) { invokeWrite0(msg, promise);//写入 invokeFlush0();//刷新 } else { writeAndFlush(msg, promise); } }
这里就真相大白了, 其实在writeAndFlush()方法中, 首先调用write, write 完成之后再调用flush 方法进行的刷新。首先跟到invokeWrite0()方法中:
private void invokeWrite0(Object msg, ChannelPromise promise) { try { ((ChannelOutboundHandler) handler()).write(this, msg, promise); } catch (Throwable t) { notifyOutboundHandlerException(t, promise); } }
该方法我们在pipeline 中已经进行过分析, 就是调用当前handler 的write 方法, 如果当前handler 中write 方法是继续往下传播, 在会继续传播写事件, 直到传播到head 节点, 最后会走到HeadContext 的write 方法中,跟到HeadContext的write 方法中:
public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception { unsafe.write(msg, promise); }
这里通过当前channel 的unsafe 对象对将当前消息写到缓存中, 回到invokeWriteAndFlush()方法再看invokeFlush0()方法:
private void invokeFlush0() { try { ((ChannelOutboundHandler) handler()).flush(this); } catch (Throwable t) { notifyHandlerException(t); } }
同样, 这里会调用当前handler 的flush 方法, 如果当前handler 的flush 方法是继续传播flush 事件, 则flush 事件会继续往下传播, 直到最后会调用head 节点的flush 方法, 如果我们熟悉pipeline 的话, 对这里的逻辑不会陌生。跟到HeadContext 的flush 方法中:
public void flush(ChannelHandlerContext ctx) throws Exception { unsafe.flush(); }
这里同样, 会通过当前channel 的unsafe 对象通过调用flush 方法将缓存的数据刷新到channel 中,。以上就是writeAndFlush 的相关逻辑, 整体上比较简单, 掌握了Pipeline 的小伙伴应该很容易理解。
MessageToByteEncoder 抽象编码器:
同解码器一样, 编码器中也有一个抽象类叫MessageToByteEncoder, 其中定义了编码器的骨架方法, 具体编码逻辑交给子类实现。解码器同样也是个handler, 将写出的数据进行截取处理, 我们在学习Pipeline 时我们知道, 写数据的时候会传递write 事件, 传递过程中会调用handler 的write 方法, 所以编码器码器可以重写write 方法, 将数据编码成二进制字节流然后再继续传递write 事件。首先来看MessageToByteEncoder 的类声明:MessageToByteEncoder 负责将POJO 对象编码成ByteBuf,用户的编码器继承MessageToByteEncoder,实现void encode(ChannelHandlerContextctx, I msg, ByteBuf out)接口接口,示例代码如下:
public class IntegerEncoder extends MessageToByteEncoder<Integer> {
@Override public void encode(ChannelHandlerContext ctx, Integer msg,ByteBuf out) throws Exception { out.writeInt(msg); } }
它的实现原理如下:调用write 操作时,首先判断当前编码器是否支持需要发送的消息,如果不支持则直接透传;如果支持则判断缓冲区的类型,对于直接内存分配ioBuffer(堆外内存),对于堆内存通过heapBuffer 方法分配,源码如下:
public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception { ByteBuf buf = null; try { if (acceptOutboundMessage(msg)) { @SuppressWarnings("unchecked") I cast = (I) msg; buf = allocateBuffer(ctx, cast, preferDirect); try { encode(ctx, cast, buf); } finally { ReferenceCountUtil.release(cast); } if (buf.isReadable()) { ctx.write(buf, promise); } else { buf.release(); ctx.write(Unpooled.EMPTY_BUFFER, promise); } buf = null; } else { ctx.write(msg, promise); } } catch (EncoderException e) { throw e; } catch (Throwable e) { throw new EncoderException(e); } finally { if (buf != null) { buf.release(); } } }
编码使用的缓冲区分配完成之后,调用encode 抽象方法进行编码,方法定义如下:它由子类负责具体实现。
protected abstract void encode(ChannelHandlerContext ctx, I msg, ByteBuf out) throws Exception;
编码完成之后,调用ReferenceCountUtil 的release 方法释放编码对象msg。对编码后的ByteBuf 进行以下判断:
- 如果缓冲区包含可发送的字节,则调用ChannelHandlerContext 的write 方法发送ByteBuf;
- 如果缓冲区没有包含可写的字节,则需要释放编码后的ByteBuf,写入一个空的ByteBuf 到ChannelHandlerContext中。
发送操作完成之后,在方法退出之前释放编码缓冲区ByteBuf 对象。
写入Buffer 队列:
前面的章节我们介绍过, writeAndFlush 方法其实最终会调用write 和flush 方法,write 方法最终会传递到head 节点, 调用HeadContext 的write 方法:
public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception { unsafe.write(msg, promise); }
这里通过unsafe 对象的write 方法, 将消息写入到缓存中。我们跟到AbstractUnsafe 的write 方法中:
public final void write(Object msg, ChannelPromise promise) { assertEventLoop(); //负责缓冲写进来的byteBuf ChannelOutboundBuffer outboundBuffer = this.outboundBuffer; if (outboundBuffer == null) { safeSetFailure(promise, WRITE_CLOSED_CHANNEL_EXCEPTION); ReferenceCountUtil.release(msg); return; }
int size; try { //非堆外内存转化为堆外内存 msg = filterOutboundMessage(msg); size = pipeline.estimatorHandle().size(msg); if (size < 0) { size = 0; } } catch (Throwable t) { safeSetFailure(promise, t); ReferenceCountUtil.release(msg); return; }
//插入写队列 outboundBuffer.addMessage(msg, size, promise); }
首先看ChannelOutboundBuffer outboundBuffer = this.outboundBuffer,ChannelOutboundBuffer 的功能就是缓存写入的ByteBuf。我们继续看try 块中的msg = filterOutboundMessage(msg) ,这步的意义就是将非堆外内存转化为堆外内存,filterOutboundMessage 方法方法最终会调用AbstractNioByteChannel 中的filterOutboundMessage 方法:
protected final Object filterOutboundMessage(Object msg) { if (msg instanceof ByteBuf) { ByteBuf buf = (ByteBuf) msg; //是堆外内存, 直接返回 if (buf.isDirect()) { return msg; } return newDirectBuffer(buf); } if (msg instanceof FileRegion) { return msg; } throw new UnsupportedOperationException( "unsupported message type: " + StringUtil.simpleClassName(msg) + EXPECTED_TYPES); }
首先判断msg 是否byteBuf 对象, 如果是, 判断是否堆外内存, 如果是堆外内存, 则直接返回, 否则, 通过newDirectBuffer(buf)这种方式转化为堆外内存。回到write 方法中,outboundBuffer.addMessage(msg, size, promise)将已经转化为堆外内存的msg 插入到写队列。我们跟到addMessage()方法当中, 这是ChannelOutboundBuffer 中的方法:
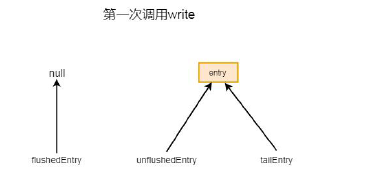
public void addMessage(Object msg, int size, ChannelPromise promise) { Entry entry = Entry.newInstance(msg, size, total(msg), promise); if (tailEntry == null) { flushedEntry = null; tailEntry = entry; } else { Entry tail = tailEntry; tail.next = entry; tailEntry = entry; }
if (unflushedEntry == null) { unflushedEntry = entry; }
incrementPendingOutboundBytes(size, false); }
首先通过Entry.newInstance(msg, size, total(msg), promise) 的方式将msg 封装成entry,然后通过调整tailEntry,flushedEntry, unflushedEntry 三个指针, 完成entry 的添加。这三个指针均是ChannelOutboundBuffer 的成员变量:flushedEntry 指向第一个被flush 的entryunflushedEntry 指向第一个未被flush 的entry也就是说, 从flushedEntry 到unflushedEntry 之间的entry, 都是被已经被flush 的entry。tailEntry 指向最后一个entry,也就是从unflushedEntry 到tailEntry 之间的entry 都是没flush 的entry。我们回到代码中,创建了entry 之后首先判断尾指针是否为空, 在第一次添加的时候, 均是空, 所以会将flushedEntry 设置为null, 并且将尾指针设置为当前创建的entry,最后判断unflushedEntry 是否为空, 如果第一次添加这里也是空, 所以这里将unflushedEntry 设置为新创建的entry。第一次添加如下图所示:
如果不是第一次调用write 方法, 则会进入if (tailEntry == null) 中else 块:Entry tail = tailEntry 这里tail 就是当前尾节点,tail.next = entry 代表尾节点的下一个节点指向新创建的entry,tailEntry = entry 将尾节点也指向entry这样就完成了添加操作, 其实就是将新创建的节点追加到原来尾节点之后,第二次添加if (unflushedEntry == null) 会返回false, 所以不会进入if 块。第二次添加之后指针的指向情况如下图所示:
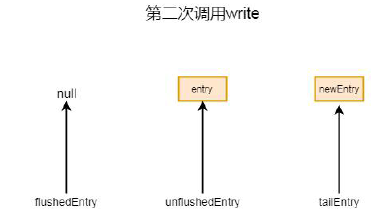
以后每次调用write, 如果没有调用flush 的话都会在尾节点之后进行追加。回到代码中, 看这一步incrementPendingOutboundBytes(size, false),这步统计当前有多少字节需要被写出, 我们跟到这个方法中:
private void incrementPendingOutboundBytes(long size, boolean invokeLater) { if (size == 0) { return; }
//TOTAL_PENDING_SIZE_UPDATER 当前缓冲区里面有多少待写的字节 long newWriteBufferSize = TOTAL_PENDING_SIZE_UPDATER.addAndGet(this, size); //getWriteBufferHighWaterMark() 最高不能超过64k if (newWriteBufferSize > channel.config().getWriteBufferHighWaterMark()) { setUnwritable(invokeLater); } }
看这一步: long newWriteBufferSize = TOTAL_PENDING_SIZE_UPDATER.addAndGet(this, size) 。TOTAL_PENDING_SIZE_UPDATER 表示当前缓冲区还有多少待写的字节, addAndGet 就是将当前的ByteBuf 的长度进行累加, 累加到newWriteBufferSize 中。再继续看判断if (newWriteBufferSize >channel.config().getWriteBufferHighWaterMark()) .其中channel.config().getWriteBufferHighWaterMark() 表示写buffer的高水位值, 默认是64KB, 也就是说写buffer 的最大长度不能超过64KB 。如果超过了64KB, 则会调用setUnwritable(invokeLater)方法设置写状态,我们跟到setUnwritable(invokeLater)方法中:
private void setUnwritable(boolean invokeLater) { for (;;) { final int oldValue = unwritable; final int newValue = oldValue | 1; if (UNWRITABLE_UPDATER.compareAndSet(this, oldValue, newValue)) { if (oldValue == 0 && newValue != 0) { fireChannelWritabilityChanged(invokeLater); } break; } } }
这里通过自旋和cas 操作, 传播一个ChannelWritabilityChanged 事件, 最终会调用handler 的channelWritabilityChanged 方法进行处理,以上就是写buffer 的相关逻辑。
刷新Buffer 队列:
通过前面的学习我们知道, flush 方法通过事件传递, 最终会传递到HeadContext 的flush 方法:
public void flush(ChannelHandlerContext ctx) throws Exception { unsafe.flush(); }
这里最终会调用AbstractUnsafe 的flush 方法:
public final void flush() { assertEventLoop(); ChannelOutboundBuffer outboundBuffer = this.outboundBuffer; if (outboundBuffer == null) { return; } outboundBuffer.addFlush(); flush0(); }
这里首先也是拿到ChannelOutboundBuffer 对象,然后我们看 outboundBuffer.addFlush() 这一步:
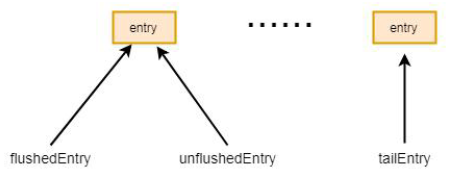
public void addFlush() { Entry entry = unflushedEntry; if (entry != null) { if (flushedEntry == null) { // there is no flushedEntry yet, so start with the entry flushedEntry = entry; } do { flushed ++; if (!entry.promise.setUncancellable()) { // Was cancelled so make sure we free up memory and notify about the freed bytes int pending = entry.cancel(); decrementPendingOutboundBytes(pending, false, true); } entry = entry.next; } while (entry != null); // All flushed so reset unflushedEntry unflushedEntry = null; } }
首先声明一个entry 指向unflushedEntry, 也就是第一个未flush 的entry。通常情况下unflushedEntry 是不为空的, 所以进入if,再未刷新前flushedEntry 通常为空, 所以会执行到flushedEntry = entry,也就是flushedEntry 指向entry。经过上述操作, 缓冲区的指针情况如图所示:
然后通过do-while 将, 不断寻找unflushedEntry 后面的节点, 直到没有节点为止,flushed 自增代表需要刷新多少个节点。循环中我们关注这一步:
decrementPendingOutboundBytes(pending, false, true);
这一步也是统计缓冲区中的字节数, 但是是和上一小节的incrementPendingOutboundBytes 正好是相反, 因为这里是刷新, 所以这里要减掉刷新后的字节数,我们跟到方法中:
private void decrementPendingOutboundBytes(long size, boolean invokeLater, boolean notifyWritability) { if (size == 0) { return; }
//从总的大小减去 long newWriteBufferSize = TOTAL_PENDING_SIZE_UPDATER.addAndGet(this, -size); //直到减到小于某一个阈值32 个字节 if (notifyWritability && newWriteBufferSize < channel.config().getWriteBufferLowWaterMark()) { //设置写状态 setWritable(invokeLater); } }
同样TOTAL_PENDING_SIZE_UPDATER 代表缓冲区的字节数, 这里的addAndGet 中参数是-size, 也就是减掉size 的长度。再看if (notifyWritability && newWriteBufferSize < channel.config().getWriteBufferLowWaterMark()) 。getWriteBufferLowWaterMark()代表写buffer 的第水位值, 也就是32k, 如果写buffer 的长度小于这个数, 就通过setWritable 方法设置写状态,也就是通道由原来的不可写改成可写。回到addFlush 方法,遍历do-while 循环结束之后, 将unflushedEntry 指为空, 代表所有的entry 都是可写的。经过上述操作, 缓冲区的指针情况如下图所示:
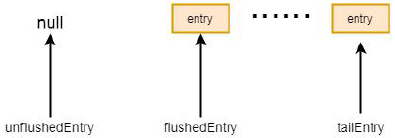
回到AbstractUnsafe 的flush 方法,指针调整完之后, 我们跟到flush0()方法中:
protected void flush0() { if (inFlush0) { return; } final ChannelOutboundBuffer outboundBuffer = this.outboundBuffer; if (outboundBuffer == null || outboundBuffer.isEmpty()) { return; } inFlush0 = true; if (!isActive()) { try { if (isOpen()) { outboundBuffer.failFlushed(FLUSH0_NOT_YET_CONNECTED_EXCEPTION, true); } else { outboundBuffer.failFlushed(FLUSH0_CLOSED_CHANNEL_EXCEPTION, false); } } finally { inFlush0 = false; } return; } try { doWrite(outboundBuffer); } catch (Throwable t) { if (t instanceof IOException && config().isAutoClose()) { close(voidPromise(), t, FLUSH0_CLOSED_CHANNEL_EXCEPTION, false); } else { outboundBuffer.failFlushed(t, true); } } finally { inFlush0 = false; } }
if (inFlush0) 表示判断当前flush 是否在进行中, 如果在进行中, 则返回, 避免重复进入。我们重点关注doWrite()方法,跟到AbstractNioByteChannel 的doWrite 方法中去:
protected void doWrite(ChannelOutboundBuffer in) throws Exception { int writeSpinCount = -1; boolean setOpWrite = false; for (;;) { //每次拿到当前节点 Object msg = in.current(); if (msg == null) { clearOpWrite(); return; }
if (msg instanceof ByteBuf) { //转化成ByteBuf ByteBuf buf = (ByteBuf) msg; //如果没有可写的值 int readableBytes = buf.readableBytes(); if (readableBytes == 0) { //移除 in.remove(); continue; }
boolean done = false; long flushedAmount = 0; if (writeSpinCount == -1) { writeSpinCount = config().getWriteSpinCount(); }
for (int i = writeSpinCount - 1; i >= 0; i --) { //将buf 写入到socket 里面 //localFlushedAmount 代表向jdk 底层写了多少字节 int localFlushedAmount = doWriteBytes(buf); //如果一个字节没写, 直接break if (localFlushedAmount == 0) { setOpWrite = true; break; }
//统计总共写了多少字节 flushedAmount += localFlushedAmount; //如果buffer 全部写到jdk 底层 if (!buf.isReadable()) { //标记全写道 done = true; break; } } in.progress(flushedAmount); if (done) { //移除当前对象 in.remove(); } else { break; } } else if (msg instanceof FileRegion) { //代码省略 } else { throw new Error(); } } incompleteWrite(setOpWrite); }
首先是一个无限for 循环,Object msg = in.current() 这一步是拿到flushedEntry 指向的entry 中的msg,跟到current()方法中:
public Object current() { Entry entry = flushedEntry; if (entry == null) { return null; } return entry.msg; }
这里直接拿到flushedEntry 指向的entry 中关联的msg, 也就是一个ByteBuf。回到doWrite 方法:如果msg 为null, 说明没有可以刷新的entry, 则调用clearOpWrite()方法清除写标识;如果msg 不为null, 则会判断是否是ByteBuf 类型, 如果是ByteBuf, 就进入if 块中的逻辑。if 块中首先将msg 转化为ByteBuf, 然后判断ByteBuf 是否可读, 如果不可读, 则通过in.remove()将当前的byteBuf 所关联的entry 移除, 然后跳过这次循环进入下次循环。remove 方法稍后分析, 这里我们先继续往下看: boolean done= false 这里设置一个标识, 标识刷新操作是否执行完成, 这里默认值为false 代表走到这里没有执行完。writeSpinCount = config().getWriteSpinCount() 这里是获得一个写操作的循环次数, 默认是16,然后根据这个循环次数, 进行循环的写操作。在循环中, 关注这一步:
int localFlushedAmount = doWriteBytes(buf);
这一步就是将buf 的内容写到channel 中, 并返回写的字节数, 这里会调用NioSocketChannel 的doWriteBytes,我们跟到doWriteBytes()方法中:
protected int doWriteBytes(ByteBuf buf) throws Exception { final int expectedWrittenBytes = buf.readableBytes(); return buf.readBytes(javaChannel(), expectedWrittenBytes); }
这里首先拿到buf 的可读字节数, 然后通过readBytes 将可读字节写入到jdk 底层的channel 中。回到doWrite 方法,将内容写的jdk 底层的channel 之后, 如果一个字节都没写, 说明现在channel 可能不可写, 将setOpWrite 设置为true,用于标识写操作位, 并退出循环。如果已经写出字节, 则通过flushedAmount += localFlushedAmount 累加写出的字节数,然后根据是buf 是否没有可读字节数判断是否buf 的数据已经写完, 如果写完, 将done 设置为true, 说明写操作完成, 并退出循环。因为有时候不一定一次就能将byteBuf 所有的字节写完, 所以这里会继续通过循环进行写出, 直到循环到16 次。如果ByteBuf 内容完全写完, 会通过in.remove()将当前entry 移除掉,我们跟到remove 方法中:
public boolean remove() { //拿到当前第一个flush 的entry Entry e = flushedEntry; if (e == null) { clearNioBuffers(); return false; }
Object msg = e.msg; ChannelPromise promise = e.promise; int size = e.pendingSize; removeEntry(e); if (!e.cancelled) { ReferenceCountUtil.safeRelease(msg); safeSuccess(promise); decrementPendingOutboundBytes(size, false, true); }
e.recycle(); return true; }
首先拿到当前的flushedEntry,我们重点关注removeEntry 这步, 跟进去:
private void removeEntry(Entry e) { if (-- flushed == 0) { //位置为空 flushedEntry = null; //如果是最后一个节点 if (e == tailEntry) { //全部设置为空 tailEntry = null; unflushedEntry = null; } } else { //移动到下一个节点 flushedEntry = e.next; } }
if (-- flushed == 0) 表示当前节点是否为需要刷新的最后一个节点, 如果是, 则flushedEntry 指针设置为空。如果当前节点是tailEntry 节点, 说明当前节点是最后一个节点, 将tailEntry 和unflushedEntry 两个指针全部设置为空。如果当前节点不是需要刷新的最后的一个节点, 则通过flushedEntry = e.nex t 这步将flushedEntry 指针移动到下一个节点。以上就是flush 操作的相关逻辑。
数据输出回调:
首先我们看一段写在handler 中的业务代码:
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception { ChannelFuture future = ctx.writeAndFlush("test data"); future.addListener(new ChannelFutureListener() { @Override public void operationComplete(ChannelFuture future) throws Exception { if (future.isSuccess()){ System.out.println("写出成功"); }else{ System.out.println("写出失败"); } } }); }
这种写法小伙伴们应该已经不陌生了, 首先调用writeAndFlush 方法将数据写出, 然后返回的future 进行添加Listener,并且重写回调函数。这只是一个最简单的示例, 在回调函数中判断future 的状态成功与否, 成功的话就打印"写出成功",否则节打印"写出失败"。这里如果写在handler 中通常是NioEventLoop 线程执行的, 在future 返回之后才会执行添加listener 的操作, 如果在用户线程中writeAndFlush 是异步执行的, 在添加监听的时候有可能写出操作没有执行完毕, 等写出操作执行完毕之后才会执行回调。以上逻辑在代码中如何体现的呢?我们首先跟到writeAndFlush 的方法中去,会走到AbstractChannelHandlerContext 中的writeAndFlush 方法中:
public ChannelFuture writeAndFlush(Object msg) { return writeAndFlush(msg, newPromise()); }
这里的逻辑在之前的章节中剖析过, 想必大家并不陌生,我们重点关注newPromise()方法, 跟进去:
public ChannelPromise newPromise() { return new DefaultChannelPromise(channel(), executor()); }
这里直接创建了DefaultChannelPromise 这个对象并传入了当前channel 和当前channel 绑定NioEventLoop 对象。在DefaultChannelPromise 构造方法中, 也会将channel 和NioEventLoop 对象绑定在自身成员变量中。回到writeAndFlush()方法继续跟:
public ChannelFuture writeAndFlush(Object msg, ChannelPromise promise) { if (msg == null) { throw new NullPointerException("msg"); } if (!validatePromise(promise, true)) { ReferenceCountUtil.release(msg); return promise; } write(msg, true, promise); return promise; }
这里的逻辑也不陌生, 注意这里最后返回了promise, 其实就是我们上一步创建DefaultChannelPromise 对象,DefaultChannelPromise 实现了ChannelFuture 接口, 所以方法如果返回该对象可以被ChannelFuture 类型接收。我们继续跟write 方法:
private void write(Object msg, boolean flush, ChannelPromise promise) { AbstractChannelHandlerContext next = findContextOutbound(); final Object m = pipeline.touch(msg, next); EventExecutor executor = next.executor(); if (executor.inEventLoop()) { if (flush) { next.invokeWriteAndFlush(m, promise); } else { next.invokeWrite(m, promise); } } else { AbstractWriteTask task; if (flush) { task = WriteAndFlushTask.newInstance(next, m, promise); } else { task = WriteTask.newInstance(next, m, promise); } safeExecute(executor, task, promise, m); } }
这里的逻辑我们同样不陌生, 如果nioEventLoop 线程, 我们继续调invokeWriteAndFlush 方法, 如果不是nioEventLoop 线程则将writeAndFlush 事件封装成task, 交给eventLoop 线程异步。这里如果是异步执行, 则到这一步之后, 我们的业务代码中, writeAndFlush 就会返回并添加监听, 有关添加监听的逻辑稍后分析。走到这里, 无论同步异步, 都会执行到invokeWriteAndFlush 方法,最终调用unsafe 的write 方法, 并传入了promise 对象,跟到AbstractUnsafe 的write 方法中:
public final void write(Object msg, ChannelPromise promise) {
assertEventLoop(); //负责缓冲写进来的byteBuf ChannelOutboundBuffer outboundBuffer = this.outboundBuffer; if (outboundBuffer == null) { safeSetFailure(promise, WRITE_CLOSED_CHANNEL_EXCEPTION); // release message now to prevent resource-leak ReferenceCountUtil.release(msg); return; } int size; try { msg = filterOutboundMessage(msg); size = pipeline.estimatorHandle().size(msg); if (size < 0) { size = 0; } } catch (Throwable t) { safeSetFailure(promise, t); ReferenceCountUtil.release(msg); return; }//插入写队列 outboundBuffer.addMessage(msg, size, promise); }
这里的逻辑之前剖析过, 这里我们首先关注两个部分, 首先看在catch 中safeSetFailure 这步。因为是catch 块, 说明发生了异常, 写到缓冲区不成功, safeSetFailure 就是设置写出失败的状态。我们跟到safeSetFailure 方法中:
protected final void safeSetFailure(ChannelPromise promise, Throwable cause) { if (!(promise instanceof VoidChannelPromise) && !promise.tryFailure(cause)) { logger.warn("Failed to mark a promise as failure because it's done already: {}", promise, cause); } }
这里看if 判断, 首先我们的promise 是DefaultChannelPromise, 所以!(promise instanceof VoidChannelPromise)为true。重点分析promise.tryFailure(cause), 这里是设置失败状态, 这里会调用DefaultPromise 的tryFailure 方法,跟进tryFailure 方法:
public boolean tryFailure(Throwable cause) { if (setFailure0(cause)) { notifyListeners(); return true; } return false; }
再跟到setFailure0(cause)中:
private boolean setValue0(Object objResult) { if (RESULT_UPDATER.compareAndSet(this, null, objResult) || RESULT_UPDATER.compareAndSet(this, UNCANCELLABLE, objResult)) { checkNotifyWaiters(); return true; } return false; }
这里在if 块中的cas 操作, 会将参数objResult 的值设置到DefaultPromise 的成员变量result 中, 表示当前操作为异常状态。
回到tryFailure 方法,我们关注notifyListeners()这个方法, 这个方法是执行添加监听的回调函数, 当writeAndFlush 和addListener 是异步执行的时候, 这里有可能添加已经添加, 所以通过这个方法可以调用添加监听后的回调。如果writeAndFlush 和addListener 是同步执行的时候, 也就是都在NioEventLoop 线程中执行的时候, 那么走到这里addListener 还没执行, 所以这里不能回调添加监听的回调函数, 那么回调是什么时候执行的呢?我们在剖析addListener 步骤的时候会给大家分析。具体执行回调我们再讲解添加监听的时候进行剖析,以上就是记录异常状态的大概逻辑。回到AbstractUnsafe 的write 方法,我们再关注这一步:outboundBuffer.addMessage(msg, size, promise);跟到addMessage()方法中:
public void addMessage(Object msg, int size, ChannelPromise promise) { Entry entry = Entry.newInstance(msg, size, total(msg), promise); ...... }
我们只需要关注包装Entry 的newInstance 方法, 该方法传入promise 对象,跟到newInstance 中:
static Entry newInstance(Object msg, int size, long total, ChannelPromise promise) { Entry entry = RECYCLER.get(); entry.msg = msg; entry.pendingSize = size; entry.total = total; entry.promise = promise; return entry; }
这里将promise 设置到Entry 的成员变量中了, 也就是说, 每个Entry 都关联了唯一的一个promise,我们回到AbstractChannelHandlerContext 的invokeWriteAndFlush 方法中:
private void invokeWriteAndFlush(Object msg, ChannelPromise promise) { if (invokeHandler()) { invokeWrite0(msg, promise); invokeFlush0(); } else { writeAndFlush(msg, promise); } }
我们刚才分析了write 操作中promise 的传递以及状态设置的大概过程, 我们继续看在flush 中promise 的操作过程。这里invokeFlush0()并没有传入promise 对象, 是因为我们刚才分析过, promise 对象会绑定在缓冲区中entry 的成员变量中, 可以通过其成员变量拿到promise 对象。invokeFlush0()我们之前也分析过, 通过事件传递, 最终会调用AbstractUnsafe 的flush 方法:
public final void flush() { assertEventLoop(); ChannelOutboundBuffer outboundBuffer = this.outboundBuffer; if (outboundBuffer == null) { return; } outboundBuffer.addFlush(); flush0(); }
这块逻辑之前已分析过, 跟进去看flush0 方法的doWrite 方法:
protected void doWrite(ChannelOutboundBuffer in) throws Exception { int writeSpinCount = -1; boolean setOpWrite = false; for (;;) { Object msg = in.current(); if (msg == null) { clearOpWrite(); return; } if (msg instanceof ByteBuf) { //代码省略 boolean done = false; //代码省略 if (done) { //移除当前对象 in.remove(); } else { break; } } else if (msg instanceof FileRegion) { //代码省略 } else { throw new Error(); } } incompleteWrite(setOpWrite); }
省略了大段代码, 我们重点关注in.remove()这里, 之前介绍过, 如果done 为true, 说明刷新事件已完成, 则移除当前entry 节点,我们跟到remove()方法中:
public boolean remove() { Entry e = flushedEntry; if (e == null) { clearNioBuffers(); return false; }
Object msg = e.msg; ChannelPromise promise = e.promise; int size = e.pendingSize; removeEntry(e); if (!e.cancelled) { ReferenceCountUtil.safeRelease(msg); safeSuccess(promise); decrementPendingOutboundBytes(size, false, true); }
e.recycle(); return true; }
这里我们看这一步:
ChannelPromise promise = e.promise;
之前我们剖析过promise 对象会绑定在entry 中, 而这步就是从entry 中获取promise 对象,等remove 操作完成, 会执行到这一步:
safeSuccess(promise);
这一步正好和我们刚才分析的safeSetFailure 相反, 这里是设置成功状态,跟到safeSuccess 方法中:
private static void safeSuccess(ChannelPromise promise) { if (!(promise instanceof VoidChannelPromise)) { PromiseNotificationUtil.trySuccess(promise, null, logger); } }
再跟到trySuccess 方法中:
public static <V> void trySuccess(Promise<? super V> p, V result, InternalLogger logger) { if (!p.trySuccess(result) && logger != null) { Throwable err = p.cause(); if (err == null) { logger.warn("Failed to mark a promise as success because it has succeeded already: {}", p); } else { logger.warn( "Failed to mark a promise as success because it has failed already: {}, unnotified cause:", p, err); } } }
这里再继续跟if 中的trySuccess 方法, 最后会走到DefaultPromise 的trySuccess 方法:
public boolean trySuccess(V result) { if (setSuccess0(result)) { notifyListeners(); return true; } return false; }
这里跟到setSuccess0 方法中:
private boolean setSuccess0(V result) { return setValue0(result == null ? SUCCESS : result); }
这里的逻辑我们刚才剖析过了, 这里参数传入一个信号SUCCESS, 表示设置成功状。再继续跟setValue 方法:
private boolean setValue0(Object objResult) { if (RESULT_UPDATER.compareAndSet(this, null, objResult) || RESULT_UPDATER.compareAndSet(this, UNCANCELLABLE, objResult)) { checkNotifyWaiters(); return true; } return false; }
同样, 在if 判断中, 通过cas 操作将参数传入的SUCCESS 对象赋值到DefaultPromise 的属性result 中, 我们看这个属性: private volatile Object result; 这里是Object 类型, 也就是可以赋值成任何类型。SUCCESS 是一个Signal 类型的对象, 这里我们可以简单理解成一种状态, SUCCESS 表示一种成功的状态。通过上述cas 操作, result 的值将赋值成SUCCESS,我们回到trySuccess 方法:
public boolean trySuccess(V result) { if (setSuccess0(result)) { notifyListeners(); return true; } return false; }
设置完成功状态之后, 则会通过notifyListeners()执行监听中的回调。我们看用户代码:
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception { ChannelFuture future = ctx.writeAndFlush("test data"); future.addListener(new ChannelFutureListener() { @Override public void operationComplete(ChannelFuture future) throws Exception { if (future.isSuccess()){ System.out.println("写出成功"); }else{ System.out.println("写出失败"); } } }); }
在回调中会判断future.isSuccess(), promise 设置为成功状态这里会返回true, 从而打印写出成功"。跟到isSuccess 方法中, 这里会调用DefaultPromise 的isSuccess 方法:
public boolean isSuccess() { Object result = this.result; return result != null && result != UNCANCELLABLE && !(result instanceof CauseHolder); }
我们看到首先会拿到result 对象, 然后判断result 不为空, 并且不是UNCANCELLABLE, 并且不属于CauseHolder 对象.我们刚才分析如果promise 设置为成功装载, 则result 为SUCCESS, 所以这里条件成立, 可以执行if (future.isSuccess())中if 块的逻辑。和设置错误状态的逻辑一样, 这里也有同样的问题, 如果writeAndFlush 是和addListener 是异步操作,那么执行到回调的时候, 可能addListener 已经添加完成, 所以可以正常的执行回调。那么如果writeAndFlush 是和addListener 是同步操作, writeAndFlush 在执行回调的时候, addListener 并没有执行, 所以无法执行回调方法, 那么回调方法是如何执行的呢,?我们看addListener 这个方法,addListener 传入ChannelFutureListener 对象, 并重写了operationComplete 方法, 也就是执行回调的方法,会执行到DefaultChannelPromise 的addListener 方法, 跟进去:
public ChannelPromise addListener(GenericFutureListener<? extends Future<? super Void>> listener) { super.addListener(listener); return this; }
跟到父类的addListener 中:
public Promise<V> addListener(GenericFutureListener<? extends Future<? super V>> listener) { checkNotNull(listener, "listener"); synchronized (this) { addListener0(listener); } if (isDone()) { notifyListeners(); } return this; }
这里通过addListener0 方法添加listener, 因为添加listener 有可能会在不同的线程中操作, 比如用户线程和NioEventLoop 线程, 为了防止并发问题, 这里简单粗暴的加了个synchronized 关键字。跟到addListener0 方法中:
private void addListener0(GenericFutureListener<? extends Future<? super V>> listener) { if (listeners == null) { listeners = listener; } else if (listeners instanceof DefaultFutureListeners) { ((DefaultFutureListeners) listeners).add(listener); } else { listeners = new DefaultFutureListeners((GenericFutureListener<? extends Future<V>>) listeners, listener); } }
如果是第一次添加listener, 则成员变量listeners 为null, 这样就把参数传入的GenericFutureListener 赋值到成员变量listeners 。如果是第二次添加listener, listeners 不为空, 会走到else if 判断, 因为第一次添加的listener 是GenericFutureListener 类型, 并不是DefaultFutureListeners 类型, 所以else if 判断返回false, 进入到else 块中。else块中, 通过new 的方式创建一个DefaultFutureListeners 对象并赋值到成员变量listeners 中。DefaultFutureListeners的构造方法中, 第一个参数传入DefaultPromise 中的成员变量listeners, 也就是第一次添加的GenericFutureListener对象, 第二个参数为第二次添加的GenericFutureListener 对象, 这里通过两个GenericFutureListener 对象包装成一个DefaultFutureListeners 对象。我们看listeners 的定义:
private Object listeners;
这里是个Object 类型, 所以可以保存任何类型的对象。再看DefaultFutureListeners 的构造方法:
DefaultFutureListeners( GenericFutureListener<? extends Future<?>> first, GenericFutureListener<? extends Future<?>> second) { listeners = new GenericFutureListener[2]; listeners[0] = first; listeners[1] = second; size = 2; if (first instanceof GenericProgressiveFutureListener) { progressiveSize ++; } if (second instanceof GenericProgressiveFutureListener) { progressiveSize ++; } }
在DefaultFutureListeners 类中也定义了一个成员变量listeners, 类型为GenericFutureListener 数组。构造方法中初始化listeners 这个数组, 并且数组中第一个值赋值为我们第一次添加的GenericFutureListener, 第二个赋值为我们第二次添加的GenericFutureListener。回到addListener0 方法中:
private void addListener0(GenericFutureListener<? extends Future<? super V>> listener) { if (listeners == null) { listeners = listener; } else if (listeners instanceof DefaultFutureListeners) { ((DefaultFutureListeners) listeners).add(listener); } else { listeners = new DefaultFutureListeners((GenericFutureListener<? extends Future<V>>) listeners, listener); } }
经过两次添加listener, 属性listeners 的值就变成了DefaultFutureListeners 类型的对象, 如果第三次添加listener, 则会走到else if 块中, DefaultFutureListeners 对象通过调用add 方法继续添加listener。跟到add 方法中:
public void add(GenericFutureListener<? extends Future<?>> l) { GenericFutureListener<? extends Future<?>>[] listeners = this.listeners; final int size = this.size; if (size == listeners.length) { this.listeners = listeners = Arrays.copyOf(listeners, size << 1); }
listeners[size] = l; this.size = size + 1; //代码省略 }
这里的逻辑也比较简单, 就是为当前的数组对象listeners 中追加新的GenericFutureListener 对象, 如果listeners 容量不足则进行扩容操作。根据以上逻辑, 就完成了listener 的添加逻辑。那么再看我们刚才遗留的问题, 如果writeAndFlush 和addListener 是同步进行的, writeAndFlush 执行回调时还没有addListener 还没有执行回调, 那么回调是如何执行的呢?回到DefaultPromise 的addListener 中:
public Promise<V> addListener(GenericFutureListener<? extends Future<? super V>> listener) { checkNotNull(listener, "listener"); synchronized (this) { addListener0(listener); } if (isDone()) { notifyListeners(); } return this; }
我们分析完了addListener0 方法, 再往下看。这个会有if 判断isDone(), isDone 方法, 就是程序执行到这一步的时候, 判断刷新事件是否执行完成,跟到isDone 方法中:
private static boolean isDone0(Object result) { return result != null && result != UNCANCELLABLE; }
这里判断result 不为null 并且不为UNCANCELLABLE, 则就表示完成。因为成功的状态是SUCCESS, 所以flush 成功这里会返回true。回到addListener 中,如果执行完成, 就通过notifyListeners()方法执行回调, 这也解释刚才的问题, 在同步操作中, writeAndFlush 在执行回调时并没有添加listener, 所以添加listener 的时候会判断writeAndFlush 的执行状态, 如果状态时完成, 则会这里执行回调。同样, 在异步操作中, 走到这里writeAndFlush 可能还没完成, 所以这里不会执行回调, 由writeAndFlush 执行回调。所以, 无论writeAndFlush 和addListener 谁先完成, 都可以执行到回调方法。跟到notifyListeners()方法中:
private void notifyListeners() { EventExecutor executor = executor(); if (executor.inEventLoop()) { final InternalThreadLocalMap threadLocals = InternalThreadLocalMap.get(); final int stackDepth = threadLocals.futureListenerStackDepth(); if (stackDepth < MAX_LISTENER_STACK_DEPTH) { threadLocals.setFutureListenerStackDepth(stackDepth + 1); try { notifyListenersNow(); } finally { threadLocals.setFutureListenerStackDepth(stackDepth); } return; } } safeExecute(executor, new Runnable() { @Override public void run() { notifyListenersNow(); } }); }
这里首先判断是否是eventLoop 线程, 如果是eventLoop 线程则执行if 块中的逻辑, 如果不是eventLoop 线程, 则把执行回调的逻辑封装成task 丢到EventLoop 的任务队列中异步执行。我们重点关注notifyListenersNow()方法, 跟进去:
private void notifyListenersNow() { Object listeners; synchronized (this) { if (notifyingListeners || this.listeners == null) { return; } notifyingListeners = true; listeners = this.listeners; this.listeners = null; } for (;;) { if (listeners instanceof DefaultFutureListeners) { notifyListeners0((DefaultFutureListeners) listeners); } else { notifyListener0(this, (GenericFutureListener<? extends Future<V>>) listeners); } //代码省略 } }
在无限for 循环中, 首先首先判断listeners 是不是DefaultFutureListeners 类型, 根据我们之前的逻辑, 如果只添加了一个listener, 则listeners 是GenericFutureListener 类型。通常在添加的时候只会添加一个listener, 所以我们跟到else块中的notifyListener0 方法:
private static void notifyListener0(Future future, GenericFutureListener l) { try { l.operationComplete(future); } catch (Throwable t) { logger.warn("An exception was thrown by " + l.getClass().getName() + ".operationComplete()", t); } }
自定义编、解码:
尽管Netty 预置了丰富的编解码类库功能,但是在实际的业务开发过程中,总是需要对编解码功能做一些定制。使用Netty 的编解码框架,可以非常方便的进行协议定制。
MessageToMessageDecoder 抽象解码器:
MessageToMessageDecoder 实际上是Netty 的二次解码器,它的职责是将一个对象二次解码为其它对象。为什么称它为二次解码器呢?我们知道,从SocketChannel 读取到的TCP 数据报是ByteBuffer,实际就是字节数组。我们首先需要将ByteBuffer 缓冲区中的数据报读取出来,并将其解码为Java 对象;然后对Java 对象根据某些规则做二次解码,将其解码为另一个POJO 对象。因为MessageToMessageDecoder 在ByteToMessageDecoder 之后,所以称之为二次解码器。
二次解码器在实际的商业项目中非常有用,以HTTP+XML 协议栈为例,第一次解码往往是将字节数组解码成HttpRequest 对象,然后对HttpRequest 消息中的消息体字符串进行二次解码,将XML 格式的字符串解码为POJO 对象,这就用到了二次解码器。类似这样的场景还有很多,不再一一枚举。事实上,做一个超级复杂的解码器将多个解码器组合成一个大而全的MessageToMessageDecoder 解码器似乎也能解决多次解码的问题,但是采用这种方式的代码可维护性会非常差。例如,如果我们打算在HTTP+XML 协议栈中增加一个打印码流的功能,即首次解码获取HttpRequest 对象之后打印XML 格式的码流。如果采用多个解码器组合,在中间插入一个打印消息体的Handler 即可,不需要修改原有的代码;如果做一个大而全的解码器,就需要在解码的方法中增加打印码流的代码,可扩展性和可维护性都会变差。
用户的解码器只需要实现void decode(ChannelHandlerContext ctx, I msg, List<Object> out)抽象方法即可,由于它是将一个POJO 解码为另一个POJO,所以一般不会涉及到半包的处理,相对于ByteToMessageDecoder 更加简单些。它的继承关系图如下所示:
MessageToMessageEncoder 抽象编码器:
将一个POJO 对象编码成另一个对象,以HTTP+XML 协议为例,它的一种实现方式是:先将POJO 对象编码成XML字符串,再将字符串编码为HTTP 请求或者应答消息。对于复杂协议,往往需要经历多次编码,为了便于功能扩展,可以通过多个编码器组合来实现相关功能。用户的解码器继承MessageToMessageEncoder 解码器,实现void encode(Channel HandlerContext ctx, I msg,List<Object> out)方法即可。注意,它与MessageToByteEncoder 的区别是输出是对象列表而不是ByteBuf,示例代码如下:
public class LengthFieldPrepender extends MessageToMessageEncoder<ByteBuf> { ...... @Override protected void encode(ChannelHandlerContext ctx, ByteBuf msg, List<Object> out) throws Exception { ......out.add(msg.retain()); } }
MessageToMessageEncoder 编码器的实现原理与之前分析的MessageToByteEncoder 相似,唯一的差别是它编码后的输出是个中间对象,并非最终可传输的ByteBuf。
ObjectEncoder 序列化编码器:
ObjectEncoder 是Java 序列化编码器,它负责将实现Serializable 接口的对象序列化为byte [],然后写入到ByteBuf中用于消息的跨网络传输。下面我们一起分析下它的实现,首先,我们发现它继承自MessageToByteEncoder,它的作用就是将对象编码成ByteBuf:如果要使用Java 序列化,对象必须实现Serializable 接口,因此,它的泛型类型为Serializable。MessageToByteEncoder 的子类只需要实现encode(ChannelHandlerContext ctx, I msg, ByteBuf out)方法即可,下面我们重点关注encode 方法的实现:
public class ObjectEncoder extends MessageToByteEncoder<Serializable> { private static final byte[] LENGTH_PLACEHOLDER = new byte[4]; @Override protected void encode(ChannelHandlerContext ctx, Serializable msg, ByteBuf out) throws Exception { int startIdx = out.writerIndex(); ByteBufOutputStream bout = new ByteBufOutputStream(out); bout.write(LENGTH_PLACEHOLDER); ObjectOutputStream oout = new CompactObjectOutputStream(bout); oout.writeObject(msg); oout.flush(); oout.close(); int endIdx = out.writerIndex(); out.setInt(startIdx, endIdx - startIdx - 4); } }
首先创建ByteBufOutputStream 和ObjectOutputStream,用于将Object 对象序列化到ByteBuf 中,值得注意的是在writeObject 之前需要先将长度字段(4 个字节)预留,用于后续长度字段的更新。依次写入长度占位符(4 字节)、序列化之后的Object 对象,之后根据ByteBuf 的writeIndex 计算序列化之后的码流长度,最后调用ByteBuf 的setInt(int index, int value)更新长度占位符为实际的码流长度。有个细节需要注意,更新码流长度字段使用了setInt 方法而不是writeInt,原因就是setInt 方法只更新内容,并不修改readerIndex 和writerIndex。
LengthFieldPrepender 通用编码器:
如果协议中的第一个字段为长度字段,Netty 提供了LengthFieldPrepender 编码器,它可以计算当前待发送消息的二进制字节长度,将该长度添加到ByteBuf 的缓冲区头中,如图所示:

通过LengthFieldPrepender 可以将待发送消息的长度写入到ByteBuf 的前2 个字节,编码后的消息组成为长度字段+原消息的方式。
通过设置LengthFieldPrepender 为true,消息长度将包含长度本身占用的字节数,打开LengthFieldPrepender 后,上图示例中的编码结果如下图所示:

LengthFieldPrepender 工作原理分析如下:首先对长度字段进行设置,如果需要包含消息长度自身,则在原来长度的基础之上再加上lengthFieldLength 的长度。如果调整后的消息长度小于0,则抛出参数非法异常。对消息长度自身所占的字节数进行判断,以便采用正确的方法将长度字段写入到ByteBuf 中,共有以下6 种可能:
- 长度字段所占字节为1:如果使用1 个Byte 字节代表消息长度,则最大长度需要小于256 个字节。对长度进行校验,如果校验失败,则抛出参数非法异常;若校验通过,则创建新的ByteBuf 并通过writeByte 将长度值写入到ByteBuf 中;
- 长度字段所占字节为2:如果使用2 个Byte 字节代表消息长度,则最大长度需要小于65536 个字节,对长度进行校验,如果校验失败,则抛出参数非法异常;若校验通过,则创建新的ByteBuf 并通过writeShort 将长度值写入到ByteBuf中;
- 长度字段所占字节为3:如果使用3 个Byte 字节代表消息长度,则最大长度需要小于16777216 个字节,对长度进行校验,如果校验失败,则抛出参数非法异常;若校验通过,则创建新的ByteBuf 并通过writeMedium 将长度值写入到ByteBuf 中;
- 长度字段所占字节为4:创建新的ByteBuf,并通过writeInt 将长度值写入到ByteBuf 中;
- 长度字段所占字节为8:创建新的ByteBuf,并通过writeLong 将长度值写入到ByteBuf 中;
- 其它长度值:直接抛出Error。
相关代码如下:
protected void encode(ChannelHandlerContext ctx, ByteBuf msg, List<Object> out) throws Exception { int length = msg.readableBytes() + lengthAdjustment; if (lengthIncludesLengthFieldLength) { length += lengthFieldLength; } if (length < 0) { throw new IllegalArgumentException( "Adjusted frame length (" + length + ") is less than zero"); } switch (lengthFieldLength) { case 1: if (length >= 256) { throw new IllegalArgumentException( "length does not fit into a byte: " + length); } out.add(ctx.alloc().buffer(1).order(byteOrder).writeByte((byte) length)); break; case 2: if (length >= 65536) { throw new IllegalArgumentException( "length does not fit into a short integer: " + length); } out.add(ctx.alloc().buffer(2).order(byteOrder).writeShort((short) length)); break; case 3: if (length >= 16777216) { throw new IllegalArgumentException( "length does not fit into a medium integer: " + length); } out.add(ctx.alloc().buffer(3).order(byteOrder).writeMedium(length)); break; case 4: out.add(ctx.alloc().buffer(4).order(byteOrder).writeInt(length)); break; case 8: out.add(ctx.alloc().buffer(8).order(byteOrder).writeLong(length)); break; default: throw new Error("should not reach here"); } out.add(msg.retain()); }
