


Netty实战之性能调优与设计模式
设计模式在Netty 中的应用(回顾):
单例模式要点回顾:
- 一个类在任何情况下只有一个对象,并提供一个全局访问点。
- 可延迟创建。
- 避免线程安全问题。
在我们利用netty自带的容器来管理客户端链接的NIOSocketChannel的时候我们会利用public static final ChannelGroup group = new DefaultChannelGroup(GlobalEventExecutor.INSTANCE);来管理,这里就有单例的应用,而对于单例的线程安全模式最简单的就是饿汉式。如下,当然在Netty中有很多地方都会应用到单例,这里只是举类说明:
public final class GlobalEventExecutor extends AbstractScheduledEventExecutor { ...... public static final GlobalEventExecutor INSTANCE; static { SCHEDULE_QUIET_PERIOD_INTERVAL = TimeUnit.SECONDS.toNanos(1L); INSTANCE = new GlobalEventExecutor(); } ...... }
策略模式要点回顾:
- 封装一系列可相互替换的算法家族。
- 动态选择某一个策略。
在我们的NioEventLoopGroup初始化的时候,在其中创建了一个指定大小的EventExecutor数组,而选择这个执行的过程正式利用了策略模式,而这个策略根据该数组大小是否是二次幂来决定:
public final class DefaultEventExecutorChooserFactory implements EventExecutorChooserFactory { public static final DefaultEventExecutorChooserFactory INSTANCE = new DefaultEventExecutorChooserFactory(); private DefaultEventExecutorChooserFactory() { } public EventExecutorChooser newChooser(EventExecutor[] executors) { return (EventExecutorChooser)(isPowerOfTwo(executors.length) ? new DefaultEventExecutorChooserFactory.PowerOfTwoEventExecutorChooser(executors) :
new DefaultEventExecutorChooserFactory.GenericEventExecutorChooser(executors)); } private static boolean isPowerOfTwo(int val) { return (val & -val) == val; } private static final class GenericEventExecutorChooser implements EventExecutorChooser { private final AtomicInteger idx = new AtomicInteger(); private final EventExecutor[] executors; GenericEventExecutorChooser(EventExecutor[] executors) { this.executors = executors; } public EventExecutor next() { return this.executors[Math.abs(this.idx.getAndIncrement() % this.executors.length)]; } } private static final class PowerOfTwoEventExecutorChooser implements EventExecutorChooser { private final AtomicInteger idx = new AtomicInteger(); private final EventExecutor[] executors; PowerOfTwoEventExecutorChooser(EventExecutor[] executors) { this.executors = executors; } public EventExecutor next() { return this.executors[this.idx.getAndIncrement() & this.executors.length - 1]; } } }
装饰者模式要点回顾:
- 装饰者和被装饰者实现同一个接口。
- 装饰者通常继承被装饰者,同宗同源。
- 动态修改、重载被装饰者的方法。
这是在一个不可释放的Buf中的例子:
class WrappedByteBuf extends ByteBuf { protected final ByteBuf buf; protected WrappedByteBuf(ByteBuf buf) { if (buf == null) { throw new NullPointerException("buf"); } else { this.buf = buf; } } ...... }
final class UnreleasableByteBuf extends WrappedByteBuf {
private SwappedByteBuf swappedBuf;
UnreleasableByteBuf(ByteBuf buf) {
super(buf);
}
......
public boolean release() {
return false;
}
public boolean release(int decrement) {
return false;
}
}
观察者模式要点回顾:
- 两个角色:观察者和被观察者。
- 观察者订阅消息,被观察者发布消息。
- 订阅则能收到消息,取消订阅则收不到。
这个例子是channel.writeAndFlush()方法:我们可以通过添加观察者来监听消息发送的结果,结果会被保存到ChannelFuture中:
future.channel().writeAndFlush(input).addListener(new ChannelFutureListener() { @Override public void operationComplete(ChannelFuture channelFuture) throws Exception { System.out.println("消息发送成功"); } });
迭代器模式要点回顾:
- 实现迭代器接口
- 实现对容器中的各个对象逐个访问的方法。
复合ByteBuf:
public class CompositeByteBuf extends AbstractReferenceCountedByteBuf implements Iterable<ByteBuf> { public byte getByte(int index) { return this._getByte(index); } }
责任链模式(可以说是Netty的大心脏了):
责任链:是指多个对象都有机会处理同一个请求,从而避免请求的发送者和接收者之间的耦合关系。然后,将这些对象连成一条链,并且沿着这条链往下传递请求,直到有一个对象可以处理它为止。在每个对象处理过程中,每个对象只处理它自己关心的那一部分,不相关的可以继续往下传递,直到链中的某个对象不想处理,可以将请求终止或丢弃。责任链模式要点回顾:
- 需要有一个顶层责任处理接口(ChannelHandler)。
- 需要有动态创建链、添加和删除责任处理器的接口(ChannelPipeline)。
- 需要有上下文机制(ChannelHandlerContext)。
- 需要有责任终止机制(不调用ctx.fireXXX()方法,则终止传播)。
AbstractChannelHandlerContext:
private AbstractChannelHandlerContext findContextInbound() { AbstractChannelHandlerContext ctx = this; do { ctx = ctx.next; } while(!ctx.inbound); return ctx; }
工厂模式要点回顾:
- 将创建对象的逻辑封装起来。
ReflectiveChannelFactory:对于SocketChannel的初始化,正是利用了工厂模式进行反射初始化实例:
public class ReflectiveChannelFactory<T extends Channel> implements ChannelFactory<T> { private final Class<? extends T> clazz; public ReflectiveChannelFactory(Class<? extends T> clazz) { if (clazz == null) { throw new NullPointerException("clazz"); } else { this.clazz = clazz; } } public T newChannel() { try { return (Channel)this.clazz.newInstance(); } catch (Throwable var2) { throw new ChannelException("Unable to create Channel from class " + this.clazz, var2); } } public String toString() { return StringUtil.simpleClassName(this.clazz) + ".class"; } }
Netty 高性能并发调优
对于线程池的合理利用是提高程序性能的有效途径之一,这里我通过线程池来测试Netty的性能,这里按照我们原来的代码来启动一个服务端:
public class Server { public static void main(String[] args) { EventLoopGroup bossGroup = new NioEventLoopGroup(); EventLoopGroup workerGroup = new NioEventLoopGroup(); ServerBootstrap bootstrap = new ServerBootstrap(); bootstrap.group(bossGroup, workerGroup) .channel(NioServerSocketChannel.class) .childOption(ChannelOption.SO_REUSEADDR, true); bootstrap.childHandler(new ChannelInitializer<SocketChannel>() { @Override protected void initChannel(SocketChannel ch) { //自定义长度的解码,每次发送一个long类型的长度数据 //一会每次传递一个系统的时间戳 ch.pipeline().addLast(new FixedLengthFrameDecoder(Long.BYTES));
ch.pipeline().addLast(ServerHandler.INSTANCE);
} }); ChannelFuture channelFuture = bootstrap.bind(8080).addListener(new ChannelFutureListener() { public void operationComplete(ChannelFuture channelFuture) throws Exception { System.out.println("bind success in port: " + port); } }); } }
这里唯一有变化的就是处理的ChannelHadler:
@ChannelHandler.Sharable public class ServerHandler extends SimpleChannelInboundHandler<ByteBuf> { public static final ChannelHandler INSTANCE = new ServerHandler();
//channelread0是主线程 @Override protected void channelRead0(ChannelHandlerContext ctx, ByteBuf msg) { ByteBuf data = Unpooled.directBuffer(); //从客户端读一个时间戳 data.writeBytes(msg); //模拟一次业务处理,有可能是数据库操作,也有可能是逻辑处理 Object result = getResult(data); //重新写会给客户端 ctx.channel().writeAndFlush(result); } //模拟去数据库拿到一个结果 protected Object getResult(ByteBuf data) { int level = ThreadLocalRandom.current().nextInt(1, 1000); //计算出每次响应需要的时间,用来做作为QPS的参考数据 //90.0% == 1ms 1000 100 > 1ms int time; if (level <= 900) { time = 1; //95.0% == 10ms 1000 50 > 10ms } else if (level <= 950) { time = 10; //99.0% == 100ms 1000 10 > 100ms } else if (level <= 990) { time = 100; //99.9% == 1000ms 1000 1 > 1000ms } else { time = 1000; } try { Thread.sleep(time); } catch (InterruptedException e) { } return data; } }
客户端代码:
public class Client { private static final String SERVER_HOST = "127.0.0.1"; public static void main(String[] args) throws Exception { new Client().start(8080); } public void start(int port) throws Exception { EventLoopGroup eventLoopGroup = new NioEventLoopGroup(); final Bootstrap bootstrap = new Bootstrap(); bootstrap.group(eventLoopGroup) .channel(NioSocketChannel.class) .option(ChannelOption.SO_REUSEADDR, true) .handler(new ChannelInitializer<SocketChannel>() { @Override protected void initChannel(SocketChannel ch) { ch.pipeline().addLast(new FixedLengthFrameDecoder(Long.BYTES)); ch.pipeline().addLast(ClientHandler.INSTANCE); } }); //客户端每秒钟向服务端发起1000次请求 for (int i = 0; i < 1000; i++) { bootstrap.connect(SERVER_HOST, port).get(); } } }
·客户端Handler:
@ChannelHandler.Sharable public class ClientHandler extends SimpleChannelInboundHandler<ByteBuf> { public static final ChannelHandler INSTANCE = new ClientHandler(); private static AtomicLong beginTime = new AtomicLong(0); //总响应时间 private static AtomicLong totalResponseTime = new AtomicLong(0); //总请求数 private static AtomicInteger totalRequest = new AtomicInteger(0); public static final Thread THREAD = new Thread(){ @Override public void run() { try { while (true) { long duration = System.currentTimeMillis() - beginTime.get(); if (duration != 0) { System.out.println("QPS: " + 1000 * totalRequest.get() / duration + ", " + "平均响应时间: " + ((float) totalResponseTime.get()) / totalRequest.get() + "ms."); Thread.sleep(2000); } } } catch (InterruptedException ignored) { } } }; @Override public void channelActive(final ChannelHandlerContext ctx) {
//上线,定时发送 ctx.executor().scheduleAtFixedRate(new Runnable() { public void run() { ByteBuf byteBuf = ctx.alloc().ioBuffer(); //将当前系统时间发送到服务端 byteBuf.writeLong(System.currentTimeMillis()); ctx.channel().writeAndFlush(byteBuf); } }, 0, 1, TimeUnit.SECONDS); } @Override protected void channelRead0(ChannelHandlerContext ctx, ByteBuf msg) { //获取一个响应时间差,本次请求的响应时间 totalResponseTime.addAndGet(System.currentTimeMillis() - msg.readLong()); //每次自增 totalRequest.incrementAndGet(); //第一次是0 会进入这里,同事设置开始时间为当前系统时间,启动线程 if (beginTime.compareAndSet(0, System.currentTimeMillis())) { THREAD.start(); } } }
通过测试我们会发现服务的性能是越来越差,这样下去那么最后会导致无法再提供服务了:
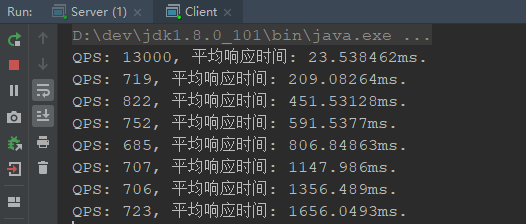
接下去我们通过线程池去解决这个问题,重新写一个Handler来处理请求(线程池大小经过测试,在我的机器上100左右为最佳机器性能决定线程池大小性能):
@ChannelHandler.Sharable public class ServerThreadPoolHandler extends ServerHandler { public static final ChannelHandler INSTANCE = new ServerThreadPoolHandler(); private static ExecutorService threadPool = Executors.newFixedThreadPool(100); @Override protected void channelRead0(final ChannelHandlerContext ctx, ByteBuf msg) { final ByteBuf data = Unpooled.directBuffer(); data.writeBytes(msg); threadPool.submit(new Runnable() { public void run() { Object result = getResult(data); ctx.channel().writeAndFlush(result); } }); } }
利用线程池处理再来看性能结果,可以看到性能有非常好的提升:
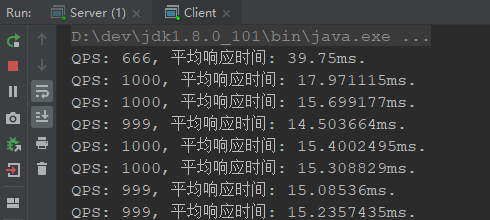
除了自己定义的Handler中进行线程池的处理之外,Netty本身就给我们提供了这么一个机制,这个主要是在ch.pipeline().addLast(ServerHandler.INSTANCE);的时候指定一个线程池大小:
final EventLoopGroup businessGroup = new NioEventLoopGroup(100); ch.pipeline().addLast(businessGroup, ServerHandler.INSTANCE);
在然我们来看看自带的线程池是否也能达到我们要的性能,可以看到性能也是有很明显地提高的:


