


常见ORM框架及JDBC操作工具类
在Java 程序里面去连接数据库,最原始的办法是使用JDBC 的API。我们先来回顾一下使用JDBC 的方式,我们是怎么操作数据库的。
// 注册JDBC 驱动 Class.forName("com.mysql.jdbc.Driver"); // 打开连接 conn = DriverManager.getConnection(DB_URL, USER, PASSWORD); // 执行查询 stmt = conn.createStatement(); String sql= "SELECT bid, name, author_id FROM blog"; ResultSet rs = stmt.executeQuery(sql); // 获取结果集 while(rs.next()){ int bid = rs.getInt("bid"); String name = rs.getString("name"); String authorId = rs.getString("author_id"); }
首先,我们在maven 中引入MySQL 驱动的依赖(JDBC 的包在java.sql 中)。
- 第一步,注册驱动,第二步,通过DriverManager 获取一个Connection,参数里面填数据库地址,用户名和密码。
- 第三步,我们通过Connection 创建一个Statement 对象。
- 第四步,通过Statement 的execute()方法执行SQL。当然Statement 上面定义了非常多的方法。execute()方法返回一个ResultSet 对象,我们把它叫做结果集。
- 第五步,我们通过ResultSet 获取数据。转换成一个POJO 对象。
- 最后,我们要关闭数据库相关的资源,包括ResultSet、Statement、Connection,它们的关闭顺序和打开的顺序正好是相反的。这个就是我们通过JDBC 的API 去操作数据库的方法,这个仅仅是一个查询。如果我们项目当中的业务比较复杂,表非常多,各种操作数据库的增删改查的方法也比较多的话,那么这样代码会重复出现很多次。
在每一段这样的代码里面,我们都需要自己去管理数据库的连接资源,如果忘记写close()了,就可能会造成数据库服务连接耗尽。另外还有一个问题就是处理业务逻辑和处理数据的代码是耦合在一起的。如果业务流程复杂,跟数据库的交互次数多,耦合在代码里面的SQL 语句就会非常多。
如果要修改业务逻辑,或者修改数据库环境(因为不同的数据库SQL 语法略有不同),这个工作量是也是难以估计的。还有就是对于结果集的处理,我们要把ResultSet 转换成POJO 的时候,必须根据字段属性的类型一个个地去处理,写这样的代码是非常枯燥的:
int bid = rs.getInt("bid"); String name = rs.getString("name"); String authorId = rs.getString("author_id"); blog.setAuthorId(authorId); blog.setBid(bid); blog.setName(name);
也正是因为这样,我们在实际工作中是比较少直接使用JDBC 的。那么我们在Java程序里面有哪些更加简单的操作数据库的方式呢?
Apache DbUtils:
https://commons.apache.org/proper/commons-dbutils/
DbUtils 解决的最核心的问题就是结果集的映射, 可以把ResultSet 封装成JavaBean。它是怎么做的呢?首先DbUtils 提供了一个QueryRunner 类,它对数据库的增删改查的方法进行了封装,那么我们操作数据库就可以直接使用它提供的方法。在QueryRunner 的构造函数里面,我们又可以传入一个数据源,比如在这里我们Hikari,这样我们就不需要再去写各种创建和释放连接的代码了。
public class HikariUtil { private static final String PROPERTY_PATH = "/hikari.properties"; private static final Logger LOGGER = LoggerFactory.getLogger(HikariUtil.class); private static HikariDataSource dataSource; private static QueryRunner queryRunner; public static void init() { HikariConfig config = new HikariConfig(PROPERTY_PATH); dataSource = new HikariDataSource(config); queryRunner = new QueryRunner(dataSource); } public static QueryRunner getQueryRunner() { check(); return queryRunner; } public static Connection getConnection() { check(); try { Connection connection = dataSource.getConnection(); return connection; } catch (SQLException e) { throw new RuntimeException(e); } } public static void close(Connection connection) { try { if (connection != null && !connection.isClosed()) { connection.close(); } } catch (SQLException e) { throw new RuntimeException(e); } } private static void check() { if (dataSource == null || queryRunner == null) { throw new RuntimeException("DataSource has not been init"); } } }
数据源配置:
dataSource.user=root dataSource.password=123456 jdbcUrl=jdbc:mysql://localhost:3306/gp-mybatis?useUnicode=true&characterEncoding=utf8&serverTimezone=UTC dataSource.cachePrepStmts=true dataSource.prepStmtCacheSize=250 dataSource.prepStmtCacheSqlLimit=2048 dataSource.useServerPrepStmts=true dataSource.useLocalSessionState=true dataSource.rewriteBatchedStatements=true dataSource.cacheResultSetMetadata=true dataSource.cacheServerConfiguration=true dataSource.elideSetAutoCommits=true dataSource.maintainTimeStats=false dataSource.minimumIdle=10 dataSource.maximumPoolSize=30
那我们怎么把结果集转换成对象呢?比如实体类Bean 或者List 或者Map?在DbUtils 里面提供了一系列的支持泛型的ResultSetHandler。我们只要在DAO 层调用QueryRunner 的查询方法,传入这个Handler,它就可以自动把结果集转换成实体类Bean 或者List 或者Map。DAO层对象:
public class BlogDao { private static QueryRunner queryRunner; static { queryRunner = HikariUtil.getQueryRunner(); } // 返回单个对象,通过new BeanHandler<>(Class<?> clazz)来设置封装 public static void selectBlog(Integer bid) throws SQLException { String sql = "select * from blog where bid = ? "; Object[] params = new Object[]{bid}; BlogDto blogDto = queryRunner.query(sql, new BeanHandler<>(BlogDto.class), params); System.out.println(blogDto); } //返回列表,通过new BeanListHandler<>(Class<?> clazz)来设置List的泛型 public static void selectList() throws SQLException { String sql = "select * from blog"; List<BlogDto> list = queryRunner.query(sql, new BeanListHandler<>(BlogDto.class)); //list.forEach(System.out::println); } }
实体:
public class BlogDto { private Integer bid; private String name; private Integer authorId; public BlogDto() { } public Integer getBid() { return bid; } public void setBid(Integer bid) { this.bid = bid; } public String getName() { return name; } public void setName(String name) { this.name = name; } public Integer getAuthorId() { return authorId; } public void setAuthorId(Integer authorId) { this.authorId = authorId; } @Override public String toString() { return "BlogDto{" + "bid=" + bid + ", name='" + name + '\'' + ", authorId='" + authorId + '\'' + '}'; } }
没有用过DbUtils 的同学,可以思考一下通过结果集到实体类的映射是怎么实现的?也就是说,我只传了一个实体类的类型,它怎么知道这个类型有哪些属性,每个属性是什么类型?然后创建这个对象并且给这些字段赋值的?答案正是反射。大家也可以去看一下源码映证一下是不是这样。
DbUtils 要求数据库的字段跟对象的属性名称完全一致,才可以实现自动映射。
Spring JDBC:
除了DbUtils 之外,Spring 也对原生的JDBC 进行了封装,并且给我们提供了一个模板方法JdbcTemplate,来简化我们对数据库的操作。
- 第一个,我们不再需要去关心资源管理的问题。
- 第二个,对于结果集的处理,Spring JDBC 也提供了一个RowMapper 接口,可以把结果集转换成Java 对象。
看代码:比如我们要把结果集转换成Employee 对象,就可以针对一个Employee创建一个RowMapper 对象,实现RowMapper 接口,并且重写mapRow()方法。我们在mapRow()方法里面完成对结果集的处理。
public class EmployeeRowMapper implements RowMapper { @Override public Object mapRow(ResultSet resultSet, int i) throws SQLException { Employee employee = new Employee(); employee.setEmpId(resultSet.getInt("emp_id")); employee.setEmpName(resultSet.getString("emp_name")); employee.setEmail(resultSet.getString("emial")); return employee; } }
在DAO 层调用的时候就可以传入自定义的RowMapper 类,最终返回我们需要的类型。结果集和实体类类型的映射也是自动完成的。
public List<Employee> query(String sql){ new JdbcTemplate( new DruidDataSource()); return jdbcTemplate.query(sql,new EmployeeRowMapper()); }
通过这种方式,我们对于结果集的处理只需要写一次代码,然后在每一个需要映射的地方传入这个RowMapper 就可以了,减少了很多的重复代码。但是还是有问题:每一个实体类对象,都需要定义一个Mapper,然后要编写每个字段映射的getString()、getInt 这样的代码,还增加了类的数量。所以有没有办法让一行数据的字段,跟实体类的属性自动对应起来,实现自动映射呢?当然,我们肯定要解决两个问题,一个就是名称对应的问题,从下划线到驼峰命名;第二个是类型对应的问题,数据库的JDBC 类型和Java 对象的类型要匹配起来。我们可以创建一个BaseRowMapper<T>,通过反射的方式自动获取所有属性,把表字段全部赋值到属性。上面的方法就可以改成:
return jdbcTemplate.query(sql,new BaseRowMapper(Employee.class));
这样,我们在使用的时候只要传入我们需要转换的类型就可以了,不用再单独创建一个RowMapper。我们来总结一下,DbUtils 和Spring JDBC,这两个对JDBC 做了轻量级封装的框架,或者说工具类里面,都帮助我们解决了一些问题:
- 无论是QueryRunner 还是JdbcTemplate,都可以传入一个数据源进行初始化,也就是资源管理这一部分的事情,可以交给专门的数据源组件去做,不用我们手动创建和关闭;
- 对操作数据的增删改查的方法进行了封装;
- 可以帮助我们映射结果集,无论是映射成List、Map 还是实体类。
但是还是存在一些缺点:
- SQL 语句都是写死在代码里面的,依旧存在硬编码的问题;
- 参数只能按固定位置的顺序传入(数组),它是通过占位符去替换的,不能自动映射;
- 在方法里面,可以把结果集映射成实体类,但是不能直接把实体类映射成数据库的记录(没有自动生成SQL 的功能);
- 查询没有缓存的功能。
Hibernate:
要解决这些问题,使用这些工具类还是不够的,要用到我们今天讲的ORM 框架。那什么是ORM?为什么叫ORM?ORM 的全拼是Object Relational Mapping,也就是对象与关系的映射,对象是程序里面的对象,关系是它与数据库里面的数据的关系。也就是说,ORM 框架帮助我们解决的问题是程序对象和关系型数据库的相互映射的问题。
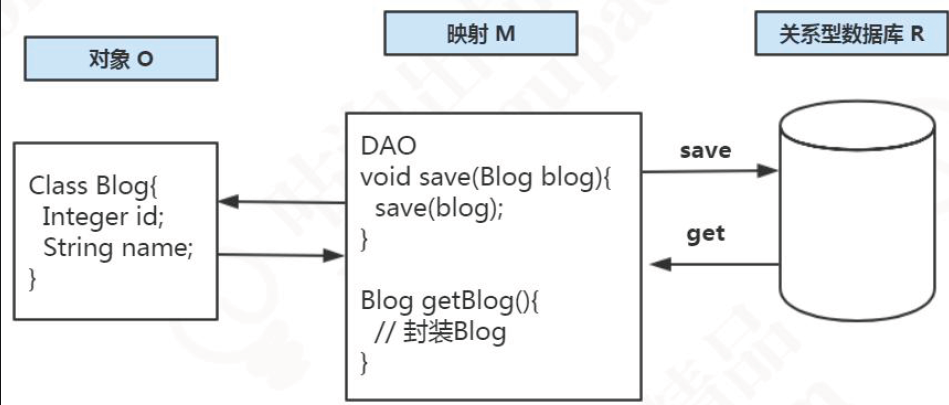
应该有很多同学是用过Hibernate 或者现在还在用的。Hibernate是一个很流行的ORM 框架,2001 年的时候就出了第一个版本。在使用Hibernate 的时候,我们需要为实体类建立一些hbm 的xml 映射文件(或者类似于@Table 的这样的注解)。例如:
<hibernate-mapping> <class name="cn.gupaoedu.vo.User" table="user"> <id name="id"> <generator class="native"/> </id> <property name="password"/> <property name="cellphone"/> <property name="username"/> </class> </hibernate-mapping>
然后通过Hibernate 提供(session)的增删改查的方法来操作对象。
//创建对象 User user = new User(); user.setPassword("123456"); user.setCellphone("18166669999"); user.setUsername("qingshan"); //获取加载配置管理类 Configuration configuration = new Configuration(); //不给参数就默认加载hibernate.cfg.xml 文件, configuration.configure(); //创建Session 工厂对象 SessionFactory factory = configuration.buildSessionFactory(); //得到Session 对象 Session session = factory.openSession(); //使用Hibernate 操作数据库,都要开启事务,得到事务对象 Transaction transaction = session.getTransaction(); //开启事务 transaction.begin(); //把对象添加到数据库中 session.save(user); //提交事务 transaction.commit(); //关闭Session session.close();
我们操作对象就跟操作数据库的数据一样。Hibernate 的框架会自动帮我们生成SQL语句(可以屏蔽数据库的差异),自动进行映射。这样我们的代码变得简洁了,程序的可读性也提高了。但是Hibernate 在业务复杂的项目中使用也存在一些问题:
- 比如使用get()、save() 、update()对象的这种方式,实际操作的是所有字段,没有办法指定部分字段,换句话说就是不够灵活。
- 这种自动生成SQL 的方式,如果我们要去做一些优化的话,是非常困难的,也就是说可能会出现性能比较差的问题。
- 不支持动态SQL(比如分表中的表名变化,以及条件、参数)。
MyBatis:
“半自动化”的ORM 框架MyBatis 就解决了这几个问题。“半自动化”是相对于Hibernate 的全自动化来说的,也就是说它的封装程度没有Hibernate 那么高,不会自动生成全部的SQL 语句,主要解决的是SQL 和对象的映射问题。在MyBatis 里面,SQL 和代码是分离的,所以会写SQL 基本上就会用MyBatis,没有额外的学习成本。我们来总结一下,MyBatis 的核心特性,或者说它解决的主要问题是什么:
- 使用连接池对连接进行管理
- SQL 和代码分离,集中管理
- 结果集映射
- 参数映射和动态SQL
- 重复SQL 的提取
- 缓存管理
- 插件机制
当然,需要明白的是,Hibernate 和MyBatis 跟DbUtils、Spring JDBC 一样,都是对JDBC 的一个封装,我们去看源码,最后一定会看到Statement 和ResultSet 这些对象。
问题来了,我们有这么多的工具和不同的框架,在实际的项目里面应该怎么选择?在一些业务比较简单的项目中,我们可以使用Hibernate;如果需要更加灵活的SQL,可以使用MyBatis,对于底层的编码,或者性能要求非常高的场合,可以用JDBC。实际上在我们的项目中,MyBatis 和Spring JDBC 是可以混合使用的。当然,我们也根据项目的需求自己写ORM 框架。下文我们将慢慢的对Mybatis进行更深入的学习。
参考:
- 业务简单的项目可以使用Hibernate
- 需要灵活的SQL,可以用MyBatis
- 对性能要求高,可以使用JDBC
- Spring JDBC可以和ORM框架混用

