


Mycat节点扩缩容及高可用集群方案
数据迁移与扩容实践:
工具目前从 mycat1.6,准备工作:1、mycat 所在环境安装 mysql 客户端程序。 2、mycat 的 lib 目录下添加 mysql 的 jdbc 驱动包。 3、对扩容缩容的表所有节点数据进行备份,以便迁移失败后的数据恢复。
步骤:
1、复制 schema.xml、rule.xml 并重命名为 newSchema.xml、newRule.xml 放于 conf 目录下。
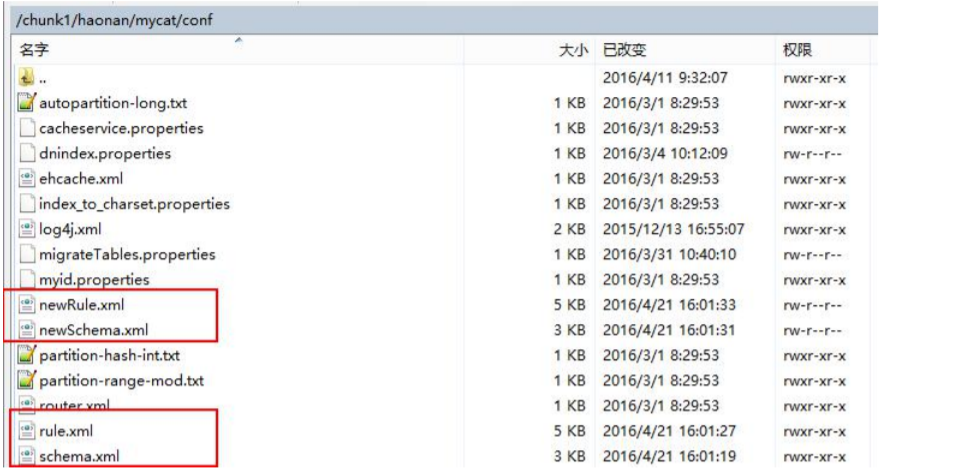
2、修改 newSchema.xml 和 newRule.xml 配置文件为扩容缩容后的 mycat 配置参数(表的节点数、 数据源、路由规则)。由于我原先只有138,139两个节点,现在选择进行扩容,以一个节点为例。我们先修改 rule.xml,将原先的取模算法中对 2 取模改成对 3 取模,接下去我新增的节点在另外的主机上。所以在 newSchema.xml上加入以下信息:
<dataNode name="db_user_dataNode3" dataHost="db_userHOST3" database="db_user" />
<dataHost name="db_userHOST3" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="userHost3" url="192.168.254.137:3306" user="root" password="wuzhenzhao">
</writeHost>
</dataHost>
加完以后,在对应分区的 schema 标签中将原先的 dataNode="db_user_dataNode$1-2" 修改为 dataNode="db_user_dataNode$1-3"。
3、修改 conf 目录下的 migrateTables.properties 配置文件,告诉工具哪些表需要进行扩容或缩 容,没有出现在此配置文件的 schema 表不会进行数据迁移,格式:

4、修改 bin 目录下的 dataMigrate.sh 脚本文件,参数如下:
tempFileDir 临时文件路径,目录不存在将自动创建 isAwaysUseMaster 默认 true:不论是否发生主备切换,都使用主数据源数据,false:使用当前数据源 mysqlBin:mysql bin 路径 cmdLength mysqldump 命令行长度限制 默认 110k 110*1024。在 LINUX 操作系统有限制单条命令行的长度是 128KB,也就是 131072 字节,这个值可能不同操作系统不同内核都不一样,如果执行迁移时报 Cannot run program "sh": error=7, Argument list too long 说明这个值设置大了,需要调小此值。 charset 导入导出数据所用字符集 默认 utf8 deleteTempFileDir 完成扩容缩容后是否删除临时文件 默认为 true threadCount 并行线程数(涉及生成中间文件和导入导出数据)默认为迁移程序所在主机环境的 cpu 核数*2 delThreadCount 每个数据库主机上清理冗余数据的并发线程数,默认为当前脚本程序所在主机 cpu 核数/2 queryPageSize 读取迁移节点全部数据时一次加载的数据量 默认 10w 条
5、停止 mycat 服务(如果可以确保扩容缩容过程中不会有写操作,也可以不停止 mycat 服 务)。
6、通过 crt 等工具进入 mycat 根目录,执行 bin/ dataMigrate.sh 脚本,开始扩容/缩容过程:

7、扩容缩容成功后,将 newSchema.xml 和 newRule.xml 重命名为 schema.xml 和 rule.xml 并替 换掉原文件,重启 mycat 服务,整个扩容缩容过程完成。
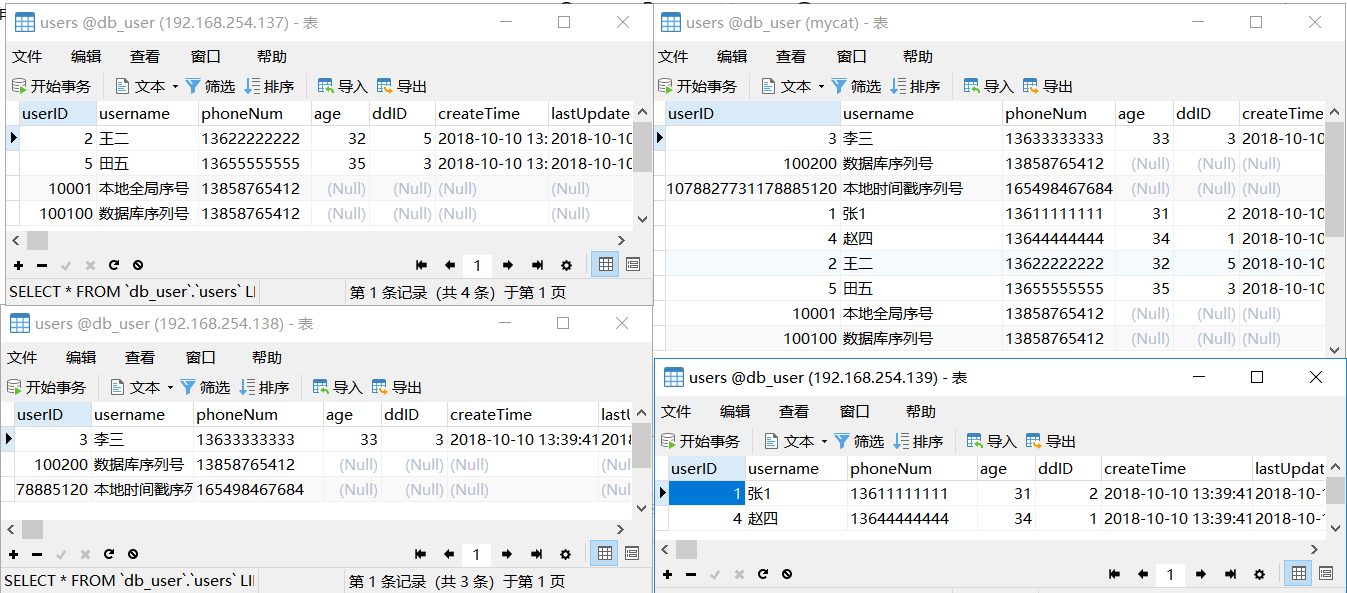
以下就是我迁移过后的数据信息。符合我们的预期:
注意事项:
1) 保证拆分表迁移数据前后路由规则一致。
2) 保证拆分表迁移数据前后拆分字段一致。
3) 全局表将被忽略。
4) 不要将非拆分表配置到 migrateTables.properties 文件中。
5) 暂时只支持拆分表使用 mysql 作为数据源的扩容缩容。
优化 :
dataMigrate.sh 脚本中影响数据迁移速度的有 4 个参数,正式迁移数据前可以先进行一次测 试,通过调整以下参数进行优化获得一个最快的参数组合。
threadCount 脚本执行所在主机的并行线程数(涉及生成中间文件和导入导出数据)默认为迁移程序所在主机环境的 cpu 核数*2 。
delThreadCount 每个数据库主机上清理冗余数据的并发线程数,默认为当前脚本程序所在主机 cpu 核数/2,同一主机上并发删 除数据操作线程数过多可能会导致性能严重下降,可以逐步提高并发数,获取执行最快的线程个数。
queryPageSize 读取迁移节点全部数据时一次加载的数据量 默认 10w 条 。
cmdLength mysqldump 命令行长度限制 默认 110k 110*1024。尽量让这个值跟操作系统命令长度最大值一致,可以通过以下过程 确定操作系统命令行最大长度限制:
逐步减少 100000,直到不再报错 /bin/sh -c "/bin/true $(seq 1 100000)" 获取不报错的值,通过 wc –c 统计字节数,结果即操作系统命令行最大长度限制(可能稍微小一些)。
Mycat 里的数据库事务:
Mycat 目前没有出来跨分片的事务强一致性支持,目前单库内部可以保证事务的完整性,如果跨库事务, 在执行的时候任何分片出错,可以保证所有分片回滚,但是一旦应用发起 commit 指令,无法保证所有分片都成 功,考虑到某个分片挂的可能性不大所以称为弱 xa。
Mycat之mysqldump方式进行快速移植:
如果将现有的数据快速整合到 mycat 中?将老库备份成 sql 文件,再到mycat 中一执行就完事。前提要保证mycat分片规则等都运行正常。
mysqldump -uroot -p123456 -h192.168.8.137 -c db_user_old users > users.sql
2.ER子表:
mysqldump -uroot -p123456 -h192.168.8.137 -c --skip-extended-insert db_user_old user_address > userAddress.sql
3.导入:
mysql -h192.168.8.151 -uroot -p123456 -P8066 -f db_user < users.sql
mysql -h192.168.8.151 -uroot -p123456 -P8066 -f db_user < userAddress.sql
Mycat 高可用方案:
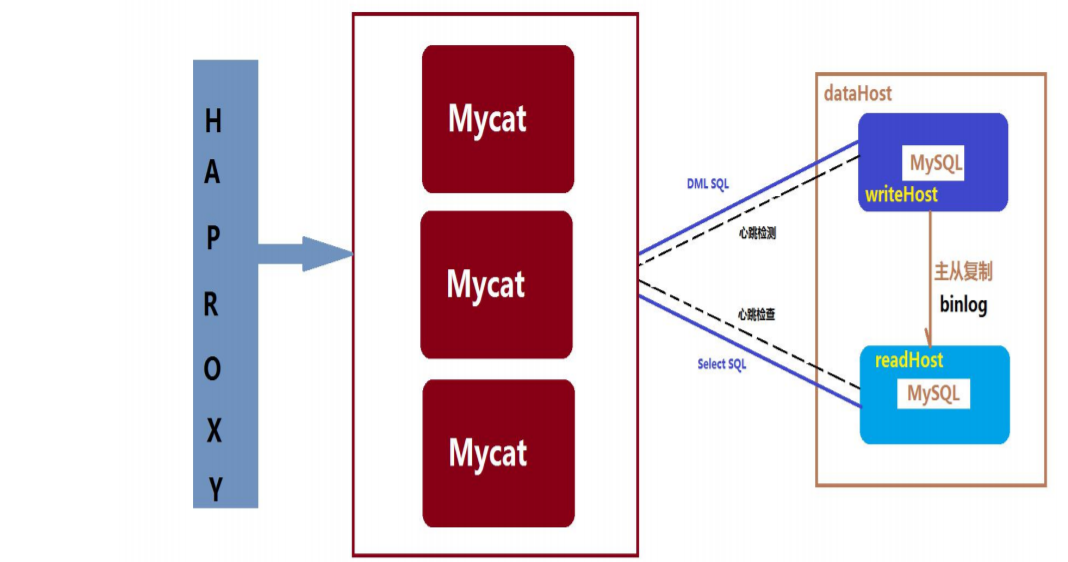
单节点 mycat 的部署指的是只部署一台 mycat 服务器,它与 mycat 集群部署是相对的,如果这台 mycat 服 务器宕机了,mycat 就不可用了。高可用通常也叫 HA(High Available)。指的是,一台服务器宕机了,照样能对外提供服务。常用的高可用 软件方案有:LVS、keepalived、Heartbeat、roseHA(roseHA 为收费软件)等。 Mycat 本身是无状态的,可以用 HAProxy 或四层交换机等设备组成 Mycat 的高可用集群,后端 MySQL 则 配置为主从同步,此时整个系统就是高可用的,下图是一个典型的 Mycat 系统高可用的方案:
haproxy + keepalived + mycat 高可用与负载均衡集群配置:
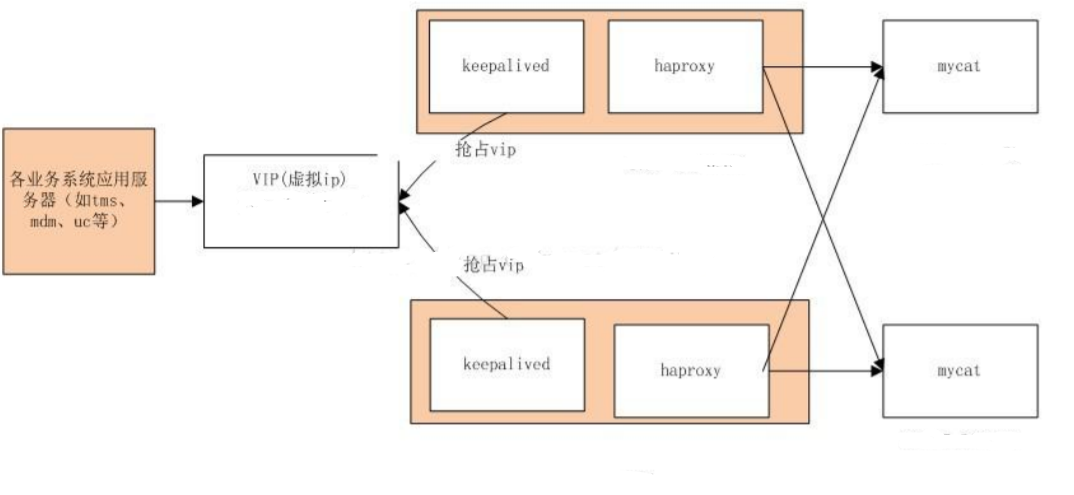
集群部署图的理解:
1、keepalived 和 haproxy 必须装在同一台机器上(如 192.168.254.138 机器上,keepalived 和 haproxy 都要安装),keepalived 负责为该服务器抢占 vip(虚拟 ip),抢占到 vip 后,对该主机的访问可以通 过原来的 ip(192.168.254.138)访问,也可以直接通过 设置好的 vip(例如:192.168.254.233)访问。
2、192.168.254.139 上的 keepalived 也会去抢占 vip,抢占 vip 时有优先级,配置 keepalived.conf 中的 (priority 150 #数值愈大,优先级越高,192.168.254.139 上改为 120,master 和 slave 上该值配置不同)决 定。 但是一般哪台主机上的 keepalived 服务先启动就会抢占到 vip,即使是 slave,只要先启动也能抢到。
3、haproxy 负责将对 vip 的请求分发到 mycat 上。起到负载均衡的作用,同时 haproxy 也能检测到 mycat 是否存活,haproxy 只会将请求转发到存活的 mycat 上。
4、如果一台服务器(keepalived+haproxy 服务器)宕机,另外一台上的 keepalived 会立刻抢占 vip 并接 管服务。 如果一台 mycat 服务器宕机,haporxy 转发时不会转发到宕机的 mycat 上,所以 mycat 依然可用。
haproxy 安装:
1.下载tar.gz包 http://www.haproxy.org/download/1.8/src/haproxy-1.8.12.tar.gz 。
2.解压并安装haproxy
解压
tar -zxvf haproxy-1.8.12.tar.gz
安装
cd haproxy-1.8.12
将haproxy应用程序安装在/usr/local/haproxy 下
make TARGET=linux26 PREFIX=/usr/local/haproxy ARCH=x86_64 (TARGET=linux26 内核版本使用uname -r查看内核,如:2.6.18-371.el5,此时该参数就为linux26;kernel 大于2.6.28的用:TARGET=linux2628,ARCH=x86_64#系统位数)
make install PREFIX=/usr/local/haproxy
3.编辑配置文件 vim /usr/local/haproxy/haproxy.cfg 并赋予执行权限chmod +x /usr/local/haproxy/haproxy.cfg
global
log 127.0.0.1 local2
pidfile /var/run/haproxy.pid
maxconn 4000
daemon
defaults
log global
option dontlognull
retries 3
option redispatch
maxconn 2000
timeout connect 5000
timeout client 50000
timeout server 50000
listen admin_status
bind 0.0.0.0:1080
stats uri /admin ##haproxy自带的管理页面通过http://ip:port/admin访问
stats auth admin:admin ##管理页面的用户名和密码
mode http
option httplog
listen allmycat_service
bind 0.0.0.0:8096 ##转发到 mycat 的 8066 端口,即 mycat 的服务端口
mode tcp
option tcplog
option httpchk OPTIONS * HTTP/1.1\r\nHost:\ www
balance roundrobin #负载均衡算法规则
server mycat_138 192.168.254.138:8066 check port 48700 inter 5s rise 2 fall 3
server mycat_139 192.168.254.139:8066 check port 48700 inter 5s rise 2 fall 3
timeout server 20000
listen allmycat_admin
bind 0.0.0.0:8097 ##转发到 mycat 的 9066 端口,即 mycat 的管理控制台端口
mode tcp
option tcplog
option httpchk OPTIONS * HTTP/1.1\r\nHost:\ www
balance roundrobin
server mycat_138 192.168.254.138:9066 check port 48700 inter 5s rise 2 fall 3
server mycat_139 192.168.254.139:9066 check port 48700 inter 5s rise 2 fall 3
timeout server 20000
4.haproxy 记录日志:
默认 haproxy 是不记录日志的,为了记录日志还需要配置 syslog 模块,在 linux 下是 rsyslogd 服务,可通过rpm -qa|grep rsyslog 命令判断有没有安装,没有安装自行安装(yum 方式简单明了)先安装 rsyslog。
yum –y install rsyslog
find / -name 'rsyslog.conf' 找到rsyslog的配置文件
vi rsyslog.conf
将#$ModLoad imudp
#$UDPServerRun 514 注释解开
找到 Save boot messages also to boot.log 在这一行下面加入
local2.* /var/log/haproxy.log 保存退出
重启rsyslog service rsyslog restart
5.启动haproxy /usr/local/haproxy/sbin/haproxy -f /usr/local/haproxy/haproxy.cfg
此时出现:
proxy allmycat_service has no server available!
proxy allmycat_admin has no server available!
因为他的check方案没有通过
option httpchk OPTIONS * HTTP/1.1\r\nHost:\ www
check port 48700 inter 5s rise 2 fall 3
上面的配置的意思是,通过http检测的方式进行服务的检测,5s检测一次。2次通过证明存活,3次失败则死亡。为此需要用到 xinetd,xinetd 为 linux 系统的基础服务。
通过Xinetd 提供48700端口的http服务来让haproxy进行服务的检测。在mycat的服务器上安装xinetd,查看是否安装:rpm -q xinetd。安装命令:yum install xinetd
找到xinetd的配置文件 cat /etc/xinetd.conf 找到 includedir /etc/xinetd.d 进入该目录cd /etc/xinetd.d 并新建 mycat_status shell脚本,vim mycat_status内容如下:
service mycat_status { #代表被托管服务的名称
flags = REUSE
socket_type = stream # socket连接方式
port = 48700 # 服务监听的端口
wait = no # 是否并发
user = root # 以什么用户进行启动
server =/usr/local/bin/mycat_status # 被托管服务的启动脚本
log_on_failure += USERID # 设置失败时,UID添加到系统登记表
disable = no #是否禁用托管服务,no表示开启托管服务
} #最好手打,复制会出问题。我就遇到了这个问题
service mycat_status
{
flags = REUSE
socket_type = stream
port = 48700
wait = no
user = root
server =/usr/local/bin/mycat_status
log_on_failure += USERID
disable = no
}
保存退出。并赋予执行权限chmod +x mycat_status
创建托管服务启动脚本/usr/local/bin/mycat_status 。编辑 :vim /usr/local/bin/mycat_status 内容如下:
#!/bin/bash
mycat=`/root/mycat/bin/mycat status |grep 'not running'| wc -l`
if [ "$mycat" = "0" ];
then
/bin/echo -e "HTTP/1.1 200 OK\r\n"
else
/bin/echo -e "HTTP/1.1 503 Service Unavailable\r\n"
fi
保存退出 并赋予执行权限chmod +x /usr/local/bin/mycat_status。验证脚本的正确性 sh mycat_status 如果返回 200OK字样说明成功:
加入mycat_status服务 vi /etc/services。在末尾加入以下内容:
mycat_status 48700/tcp # mycat_status 。保存退出,重启xinetd服务, service xinetd restart 。验证服务是否启动成功 :netstat -antup|grep 48700,如果出现 tcp6 请先关闭 ivp6

再调用 telnet 192.168.254.13 48700 出现下图说明一切OK了
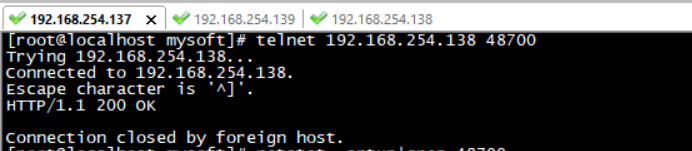
此时重启haproxy服务即正常。
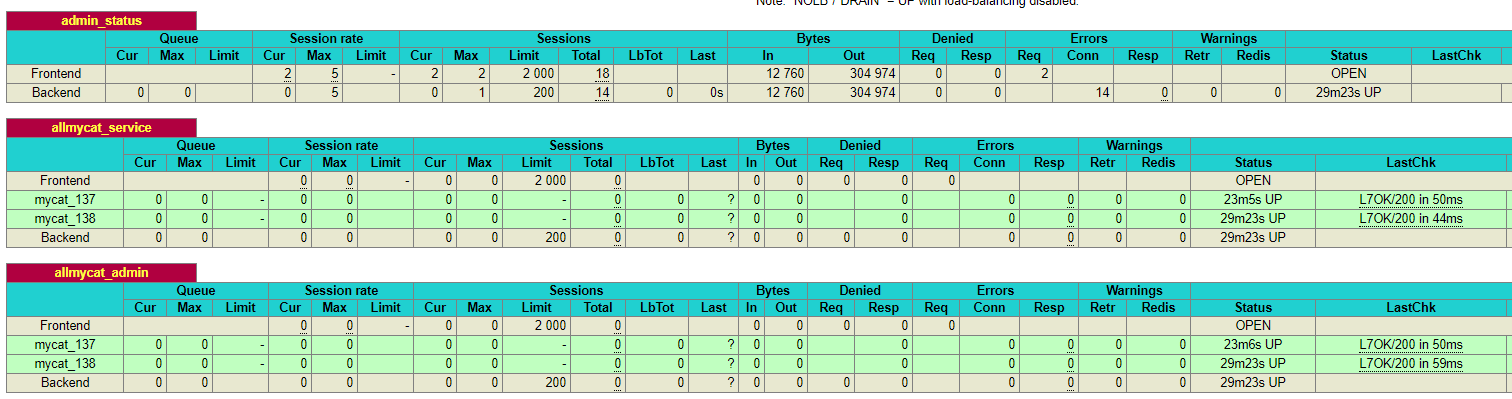
然后测试连接数据库:
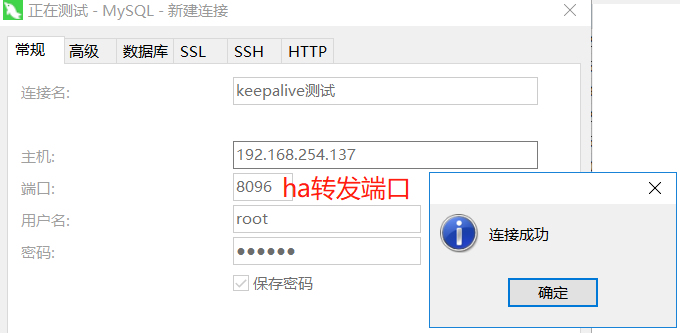
由于根据 haproxy 做了mycat 的请求分发,也就是mycat的高可用,但是对于整个架构来说,此刻 haproxy是单节点状态。再根据前文说的高可用与负载均衡集群配置,这里需要引入keepalive(官方推荐)。这样子的话,我们需要在 192.168.254.138与139 上面都配置上 haproxy 跟keepalive。
keepalive:
keepalive安装 (192.168.254.138 -> MASTER 192.168.254.139 -> BACKUP )
安装:yum install keepalived
find / -name 'keepalived.conf'。修改配置文件:vi /etc/keepalived/keepalived.conf 内容如下:
! Configuration File for keepalived
vrrp_instance VI_1 {
state MASTER #192.168.254.139 上改为 BACKUP
interface ens33 #对外提供服务的网络接口
virtual_router_id 100 #VRRP 组名,两个节点的设置必须一样,以指明各个节点属于同一 VRRP 组
priority 150 #数值愈大,优先级越高,192.168.254.139 上改为比150小的正整数
advert_int 1 #同步通知间隔
authentication { #包含验证类型和验证密码。类型主要有 PASS、AH 两种,通常使用的类型为 PASS,据说AH 使用时有问题
auth_type PASS
auth_pass 1111
}
virtual_ipaddress { #vip 地址 ens33 通过ifconfig获取
192.168.254.233 dev ens33 scope global
}
}
编辑保存。启动keepalived,执行命令 service keepalived start
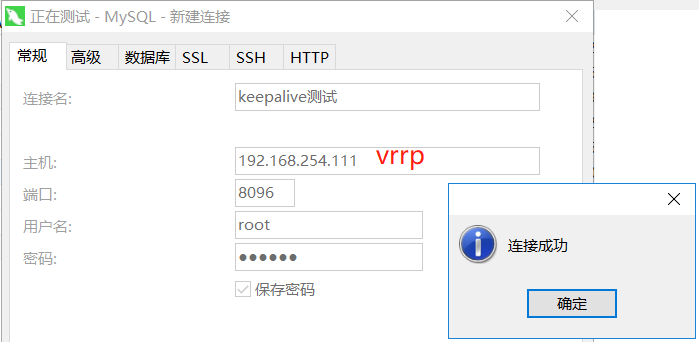
我通过 Navicat 访问192.168.254.233, 端口8096,账号 root,密码 123456.即访问抢占了vip(192.168.254.233)的物理机(192.168.254.138)。
通过上面的配置,我们可以将前端的请求转到抢占了vip(192.168.8.233)的物理机(192.168.254.138)。但是没有通过监听haproxy的服务,或者说我们没有根据haproxy服务来进行vip的降级。keepalived提供了很多的配置来做服务的检测和降级,但是我们今天不学keepalived的方式我们采用一种定时任务(linux自带的crontab)的方式来做。在nginx学习的时候会采用keepalive脚本方式。
1.创建check_haproxy.sh 并编辑内容 vi /root/script/check_haproxy.sh 内容如下:
#!/bin/bash
LOGFILE='/root/log/checkHaproxy.log'
date >> $LOGFILE
count=`ps aux | grep -v grep | grep /usr/local/haproxy/sbin/haproxy | wc -l`
if [ $count = 0 ];
then
echo 'first check fail , restart haproxy !' >> $LOGFILE
/usr/local/haproxy/sbin/haproxy -f /usr/local/haproxy/haproxy.cfg
else
exit 0
fi
sleep 3
count=`ps aux | grep -v grep | grep /usr/local/haproxy/sbin/haproxy | wc -l`
if [ $count = 0 ];
then
echo 'second check fail , stop keepalive service !' >> $LOGFILE
service keepalived stop
else
echo 'second check success , start keepalive service !' >> $LOGFILE
keepalived=` ps aux | grep -v grep | grep /usr/sbin/keepalived | wc -l`
if [ $count = 0 ];
then
service keepalived start
fi
exit 0
fi
2.执行 crontab -e 编辑定时任务 每一分钟检测haproxy服务存活,如果服务启动不了,停掉keepalived服务, vip即转发至backup的192.168.254.139 的机器 .* * * * * sh /root/script/check_haproxy.sh。保存即执行,如果想实10分钟检测,那么久写6个 * * * * * sleep 1;sh /root/script/check_haproxy.sh。后面分别是11,21.。实现秒写60个。以此类推。高可用方案完毕。
总结:
* 单表数据达到多少的时候会影响数据库的查询性能?为什么?
由于查询性能关乎多方因素,sql语句,硬件资源等,只能大概的根据工作经验评估。在单表数量不是特别大,字段不是特别多的情况下,基本撑个8000万-1亿的数据量。查询维度比较单一,索引建立得当。单表数据达为什么会影响数据库性能呢? 是因为索引命中问题,索引如果命中不了,就会导致全表扫描。一旦全表扫描势必导致性能问题,而数据库 B树的索引原理不是内存级别的索引,而是基于硬盘级别的。他需要通过IO去加载索引,查找索引要从根节点去找到叶节点,当这棵树越来越大的时候就会导致IO读写的频繁。而加载索引也是一部分一部分去加载处理的,当数据体量达到一定数值,则IO读写性能会成倍往下降。
* 主从复制机制的原理概述是怎样的?常见的存在形式有哪些?
- master将操作记录到二进制日志(binary log)中(这些记录叫做二进制日志事件,binary logevents)
- Slave通过I/O Thread异步将master的binary logevents拷贝到它的中继日志(relay log);
- Slave执行relay日志中的事件,匹配自己的配置将需要执行的数据,在slave服务上执行一遍从而达到复制数据的目的。
基于 SQL 语句的复制(statement-based replication, SBR);
基于行的复制(row-based replication, RBR(binlog));
混合模式复制(mixed-based replication, MBR);
基于 SQL 语句的方式最古老的方式,也是目前默认的复制方式,后来的两种是 MySQL 5 以后才出现的复制方式。
* 分库分表中解释一下垂直和水平2种不同的拆分?
垂直拆分是根据业务的角度去进行拆分,根据不同的业务领域的粘合度去拆分成新的小库,比如用户,订单,库存,类似如此的。
水平拆分主要是解决一张表的大数据量拆分成多个小表。
* 分库分表中垂直分库方案会带来哪些问题?
分布式事务以及系统的复杂度等相关问题。
* 分布式数据存储中间件如mycat的核心流程是什么?
解析sql--数据源管理--数据源分配--请求响应---结果整合
* 概述一下mycat?
- 一个彻底开源的,基于Cobar的,面向企业应用开发的大数据库集群
- 支持事务、ACID、可以替代MySQL的加强版数据库
- 一个可以视为MySQL集群的企业级数据库,用来替代昂贵的Oracle集群
- 一个融合内存缓存技术、NoSQL技术、HDFS大数据的新型SQL Server
- 结合传统数据库和新型分布式数据仓库的新一代企业级数据库产品
- 一个新颖的数据库中间件产品
* 解释一下全局表,ER表,分片表?
分片表 :
是指那些原有的很大数据的表,需要切分到多个数据库的表,这样,每个分片都有一部分数据,所 有分片构成了完整的数据。 例如在 mycat 配置中的 t_node 就属于分片表,数据按照规则被分到 dn1,dn2 两个分片节点(dataNode) 上。
ER 表 :
关系型数据库是基于实体关系模型(Entity-Relationship Model)之上,通过其描述了真实世界中事物与关 系,Mycat 中的 ER 表即是来源于此。根据这一思路,提出了基于 E-R 关系的数据分片策略,子表的记录与所关 联的父表记录存放在同一个数据分片上,即子表依赖于父表,通过表分组(Table Group)保证数据 Join 不会跨 库操作。 表分组(Table Group)是解决跨分片数据 join 的一种很好的思路,也是数据切分规划的重要一条规则。 如用户的地址表,用户表对应的用户可能有多个地址,在进行分片后所对应的地址表也应该放入相同分区。
全局表 :
一个真实的业务系统中,往往存在大量的类似字典表的表,这些表基本上很少变动,字典表具有以下几个特 性: • 变动不频繁; • 数据量总体变化不大; • 数据规模不大,很少有超过数十万条记录。 对于这类的表,在分片的情况下,当业务表因为规模而进行分片以后,业务表与这些附属的字典表之间的关 联,就成了比较棘手的问题,所以 Mycat 中通过数据冗余来解决这类表的 join,即所有的分片都有一份数据的拷 贝,所有将字典表或者符合字典表特性的一些表定义为全局表。 数据冗余是解决跨分片数据 join 的一种很好的思路,也是数据切分规划的另外一条重要规则。
* Mycat的在分库分表之后,它是怎么支持联表查询的?
全局表与er表从存在就是为了解决联表查询问题的。mycat注解 /*!mycat:catlet=io.mycat.catlets.ShareJoin */
* 进行库表拆分时,拆分规则怎么取舍?
数据特点:活跃的数据热度较高规模可以预期,增长量比较稳定,首选 固定数量的离散分片规
数据特点:活跃的数据为历史数据,热度要求不高。规模可以预期,增长量比较稳定. 优势可定时清理或者迁移,连续分规则优先。
* Mycat中全局ID方案有哪些?程序自定义全局ID的方案有哪些?
- sequnceHandlerType =0 为本地文件方式,服务不能重启,一重启就会回到初始值。
- 1 为数据库方式,模拟oracle的方式,采用函数方式。
- 2 为时间戳序列方式,采用64位二进制的方式
- 3 为分布式 ZK ID 生成器,
- 4 为 zk 递增 id 生成。
- 程序方式:snowflake,UUID,redis 等方案。
* 简述一下一致性hash的原理?这样设计的好处是什么?
一致性hash,把整个数据及节点看成一个环。0-2^32 的一个环,每一个节点先落到的这个环上的一个点,移植性高
* 4层负载和7层负载谁性能更高?为什么?这2者区别是什么?
所谓四层负载均衡,也就是主要通过报文中的目标地址和端口,再加上负载均衡设备设置的服务器选择方式,决定最终选择的内部服务器。他不会与前端产生连接。
所谓七层负载均衡,也称为“内容交换”,也就是主要通过报文中的真正有意义的应用层内容,再加上负载均衡设备设置的服务器选择方式,决定最终选择的内部服务器。
两者可以看成是传达室大爷和公司前台,一个只会告诉你找的人在哪你自己去,而一个会与你建立通讯并由他去传达你需要传送的信息,

