


kafka 的安装部署及整合springboot
Kafka 的简介:
Kafka 是一款分布式消息发布和订阅系统,具有高性能、高吞吐量的特点而被广泛应用与大数据传输场景。它是由 LinkedIn 公司开发,使用 Scala 语言编写,之后成为 Apache 基金会的一个顶级项目。kafka 提供了类似 JMS 的特性,但是在设计和实现上是完全不同的,而且他也不是 JMS 规范的实现。
kafka 产生的背景:
kafka 作为一个消息系统,早起设计的目的是用作 LinkedIn 的活动流(Activity Stream)和运营数据处理管道(Pipeline)。活动流数据是所有的网站对用户的使用情况做分析的时候要用到的最常规的部分,活动数据包括页面的访问量(PV)、被查看内容方面的信息以及搜索内容。这种数据通常的处理方式是先把各种活动以日志的形式写入某种文件,然后周期性的对这些文件进行统计分析。运营数据指的是服务器的性能数据(CPU、IO 使用率、请求时间、服务日志等)。
Kafka 的应用场景:
由于 kafka 具有更好的吞吐量、内置分区、冗余及容错性的优点(kafka 每秒可以处理几十万消息),让 kafka 成为了一个很好的大规模消息处理应用的解决方案。所以在企业级应用长,主要会应用于如下几个方面
Ø 行为跟踪:kafka 可以用于跟踪用户浏览页面、搜索及其他行为。通过发布-订阅模式实时记录到对应的 topic 中,通过后端大数据平台接入处理分析,并做更进一步的实时处理和监控
Ø 日志收集:日志收集方面,有很多比较优秀的产品,比如 Apache Flume,很多公司使用kafka 代理日志聚合。日志聚合表示从服务器上收集日志文件,然后放到一个集中的平台(文件服务器)进行处理。在实际应用开发中,我们应用程序的 log 都会输出到本地的磁盘上,排查问题的话通过 linux 命令来搞定,如果应用程序组成了负载均衡集群,并且集群的机器有几十台以上,那么想通过日志快速定位到问题,就是很麻烦的事情了。所以一般都会做一个日志统一收集平台管理 log 日志用来快速查询重要应用的问题。所以很多公司的套路都是把应用日志几种到 kafka 上,然后分别导入到 es 和 hdfs 上,用来做实时检索分析和离线统计数据备份等。而另一方面,kafka 本身又提供了很好的 api 来集成日志并且做日志收集。
Kafka 本身的架构:
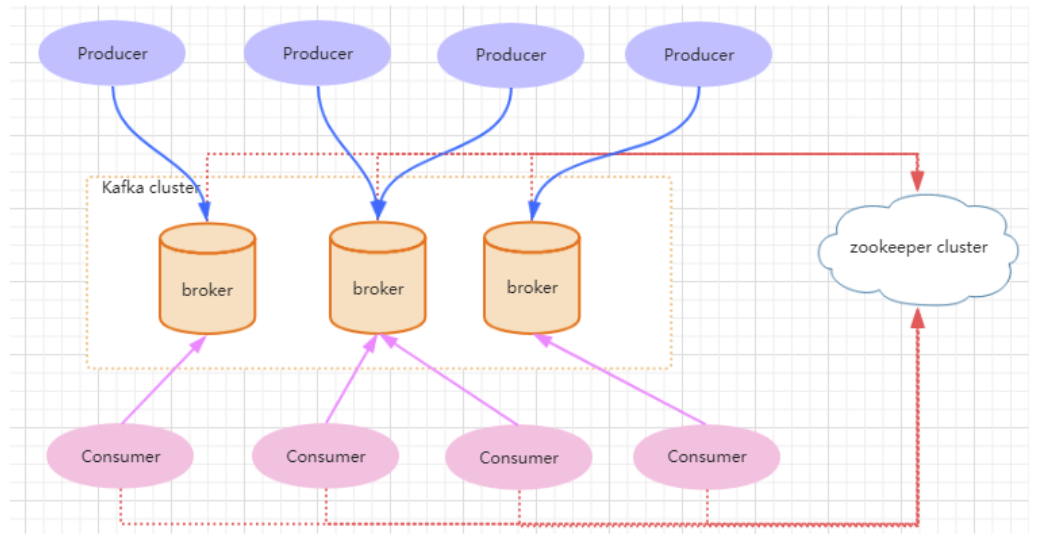
一个典型的 kafka 集群包含若干 Producer(可以是应用节点产生的消息,也可以是通过Flume 收集日志产生的事件),若干个 Broker(kafka 支持水平扩展)、若干个 Consumer Group,以及一个 zookeeper 集群。kafka 通过 zookeeper 管理集群配置及服务协同。Producer 使用 push 模式将消息发布到 broker,consumer 通过监听使用 pull 模式从broker 订阅并消费消息。多个 broker 协同工作,producer 和 consumer 部署在各个业务逻辑中。三者通过zookeeper 管理协调请求和转发。这样就组成了一个高性能的分布式消息发布和订阅系统。图上有一个细节是和其他 mq 中间件不同的点,producer 发送消息到 broker的过程是 push,而 consumer 从 broker 消费消息的过程是 pull,主动去拉数据。而不是 broker 把数据主动发送给 consumer。
kafka 的安装部署:
1.下载安装包 :http://kafka.apache.org/downloads。
解压 : tar -zxvf kafka_2.11-1.1.0.tgz 这样子就安装好了。
需要安装JDK。
2.启动/停止 kafka:
1. 需要先启动 zookeeper,如果没有搭建 zookeeper 环境,可以直接运行kafka 内嵌的 zookeeper
启动命令: bin/zookeeper-server-start.sh config/zookeeper.properties
如果连接外部zookeeper 需要修改 config/server.properties 配置文件来配置我们的zookeeper。修改如下信息。zk集群环境用逗号隔开。
zookeeper.connect=192.168.254.135:2181
这个时候可以通过 sh kafka-server-start.sh -daemon ../config/server.properties 命令来启动服务后台运行。
注意修改 listeners=PLAINTEXT://192.168.1.101:9092 。外部代理地址 advertised.listeners=PLAINTEXT://192.168.1.101:9092
3.创建 一个名为 test 的 topic(在bin目录下) :Replication-factor 表示该 topic 需要在不同的 broker 中保存几份,这里设置成 1,表示在 broker 中保存1份。Partitions 分区
sh kafka-topics.sh --create --zookeeper 192.168.254.135:2181 --replication-factor 1 --partitions 1 --topic test
查看 topic 列表:
sh kafka-topics.sh --list --zookeeper 192.168.254.135:2181
4.发送消息:发送两条消息
sh kafka-console-producer.sh --broker-list localhost:9092 --topic testTopic
> This is a message
> This is another message
5.启动消费者:
sh kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic testTopic --from-beginning
删除topic:执行完以后删除对应logs及zookeeper上的节点。
./kafka-topics.sh --delete --zookeeper 192.168.254.135:2181 --topic firstTopic
安装集群环境:
在 3台机器上都配置上 zookeeper.connect=192.168.254.135:2181 信息。zk要是也做了集群用逗号分开
修改 server.properties 文件中 broker.id=0 ,在集群中这个 id 要求是唯一的,我们分别改成 1 2 3.
放开 listeners=PLAINTEXT://:9092 配置,修改为listeners=PLAINTEXT://本机IP:9092,然后先后启动就可以,注意这里先启动的,也就是先到zk上面去注册的就是 leader。
Kafka JAVA API 的使用:
消息生产者:
public class ProducerDemo extends Thread{
private final KafkaProducer<Integer,String> producer;
private final String topic;
public ProducerDemo(String topic){
Properties properties=new Properties();
// 连接的 kafka 集群地址
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,
"192.168.254.135:9092,192.168.254.136:9092,192.168.254.137:9092");
// 客户端ID标识
properties.put(ProducerConfig.CLIENT_ID_CONFIG,"KafkaProducerDemo");
//确认记录,保证记录不丢失 总是设置成-1
properties.put(ProducerConfig.ACKS_CONFIG,"-1");
// 键序列化
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.IntegerSerializer");
//值序列化
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer");
producer=new KafkaProducer<Integer, String>(properties);
this.topic=topic;
}
@Override
public void run() {
int num=0;
while(num<50){
String message="message_"+num;
System.out.println("begin send message:"+message);
producer.send(new ProducerRecord<Integer, String>(topic, message));
num++;
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) {
new ProducerDemo("testTopic").start();
}
}
发送端的常用可选配置信息:
ACKS_CONFIG:
acks 配置表示 producer 发送消息到 broker 上以后的确认值。有三个可选项
Ø 0:表示 producer 不需要等待 broker 的消息确认。这个选项时延最小但同时风险最大(因为当 server 宕机时,数据将会丢失)。
Ø 1:表示 producer 只需要获得 kafka 集群中的 leader 节点确认即可,这个选择时延较小同时确保了 leader 节点确认接收成功。
Ø all(-1):需要 ISR 中所有的 Replica 给予接收确认,速度最慢,安全性最高,但是由于 ISR 可能会缩小到仅包含一个 Replica,所以设置参数为 all 并不能一定避免数据丢失,
BATCH_SIZE_CONFIG :
生产者发送多个消息到 broker 上的同一个分区时,为了减少网络请求带来的性能开销,通过批量的方式来提交消息,可以通过这个参数来控制批量提交的字节数大小,默认大小是 16384byte,也就是 16kb,意味着当一批消息大小达到指定的 batch.size 的时候会统一发送
LINGER_MS_CONFIG
Producer 默认会把两次发送时间间隔内收集到的所有 Requests 进行一次聚合然后再发送,以此提高吞吐量,而 linger.ms 就是为每次发送到 broker 的请求增加一些 delay,以此来聚合更多的 Message 请求。 这个有点想 TCP 里面的Nagle 算法,在 TCP 协议的传输中,为了减少大量小数据包的发送,采用了Nagle 算法,也就是基于小包的等-停协议。
Ø BATCH_SIZE_CONFIG 和 LINGER_MS_CONFIG这两个参数是 kafka 性能优化的关键参数,如果两个都配置了,那么怎么工作的呢?实际上,当二者都配置的时候,只要满足其中一个要求,就会发送请求到 broker 上
MAX_REQUEST_SIZE_CONFIG
设置请求的数据的最大字节数,为了防止发生较大的数据包影响到吞吐量,默认值为 1MB。
消息发送的可靠性:
// 方法 1: 使用 callback
producer.send(new ProducerRecord<String, String>("topic0", "message 2"), new Callback() {
public void onCompletion(RecordMetadata metadata, Exception exception) {
if(exception != null) {
System.out.println("send message2 failed with " + exception.getMessage());
} else {
// offset 是消息在 partition 中的编号,可以根据 offset 检索消息
System.out.println("message2 sent to " + metadata.topic() + ", partition " + metadata.partition() + ", offset " + metadata.offset());
}
}
});
String msg="kafka practice msg:"+num;
//get 会拿到发送的结果
//同步 get() -> Future()
//回调通知
Future<RecordMetadata> futrue = producer.send(new ProducerRecord<>(topic, msg), (metadata, exception) -> {
System.out.println(metadata.offset() + "->" + metadata.partition() + "->" + metadata.topic());
});
futrue.get();
消息消费者:
public class ConsumerDemo extends Thread{
private final KafkaConsumer kafkaConsumer;
public ConsumerDemo(String topic) {
Properties properties=new Properties();
// 连接的 kafka 集群地址
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,
"192.168.254.135:9092,192.168.254.136:9092,192.168.254.137:9092");
// 消费者分组
properties.put(ConsumerConfig.GROUP_ID_CONFIG,"KafkaConsumerDemo1");
//确认自动提交
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,"true");
// 自动提交间隔
properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG,"1000");
// 序列化
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.IntegerDeserializer");
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringDeserializer");
//对于不同的groupid保证能消费到之前的消息,重置offset
properties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"earliest");
kafkaConsumer=new KafkaConsumer(properties);
//订阅
kafkaConsumer.subscribe(Collections.singletonList(topic));
}
@Override
public void run() {
while(true){
ConsumerRecords<Integer,String> consumerRecord=kafkaConsumer.poll(1000);
for(ConsumerRecord record:consumerRecord){
System.out.println("message receive:"+record.value());
}
}
}
public static void main(String[] args) {
new ConsumerDemo("testTopic").start();
}
}
消费端的常用可选配置:
GROUP_ID_CONFIG:
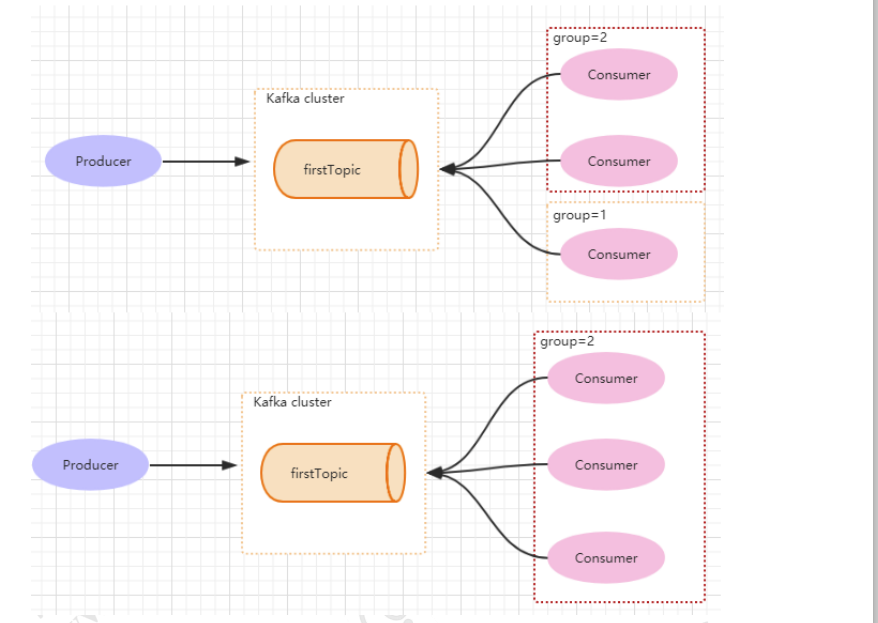
consumer group 是 kafka 提供的可扩展且具有容错性的消费者机制。既然是一个组,那么组内必然可以有多个消费者或消费者实例(consumer instance),它们共享一个公共的 ID,即 group ID。组内的所有消费者协调在一起来消费订阅主题(subscribed topics)的所有分区(partition)。当然,每个分区只能由同一个消费组内的一个 consumer 来消费.如下图所示,分别有三个消费者,属于两个不同的 group,那么对于 firstTopic 这个 topic 来说,这两个组的消费者都能同时消费这个 topic 中的消息,对于此事的架构来说,这个 firstTopic 就类似于 ActiveMQ 中的 topic 概念。如下图所示,如果 3 个消费者都属于同一个group,那么此事 firstTopic 就是一个 Queue 的概念
ENABLE_AUTO_COMMIT_CONFIG:
消费者消费消息以后自动提交,只有当消息提交以后,该消息才不会被再次接收到,还可以配合 auto.commit.interval.ms 控制自动提交的频率。当然,我们也可以通过 consumer.commitSync()的方式实现手动提交
AUTO_OFFSET_RESET_CONFIG:
这个参数是针对新的 groupid 中的消费者而言的,当有新 groupid 的消费者来消费指定的 topic 时,对于该参数的配置,会有不同的语义auto.offset.reset=latest 情况下,新的消费者将会从其他消费者最后消费的offset 处开始消费 Topic 下的消息auto.offset.reset= earliest 情况下,新的消费者会从该 topic 最早的消息开始消费auto.offset.reset=none 情况下,新的消费者加入以后,由于之前不存在offset,则会直接抛出异常。
MAX_POLL_RECORDS_CONFIG:
此设置限制每次调用 poll 返回的消息数,这样可以更容易的预测每次 poll 间隔要处理的最大值。通过调整此值,可以减少 poll 间隔。
Springboot整合Kafka(事务型消息、批量消费消息):
1.pom.xml
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<exclusions><!-- 去掉springboot默认配置 -->
<exclusion>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-logging</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency> <!-- 引入log4j2依赖 -->
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-log4j2</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.0.0</version>
</dependency>
<!--不需要设置依赖包的版本,spring-boot-starter-parent已经帮我们添加了版本的管理。-->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
</dependency>
</dependencies>
2.application.yml
#kafka配置信息 kafka: producer: bootstrap-servers: 192.168.1.101:9092 batch-size: 16785 #一次最多发送数据量 retries: 1 #发送失败后的重复发送次数 buffer-memory: 33554432 #32M批处理缓冲区 linger: 1 consumer: bootstrap-servers: 192.168.1.101:9092 auto-offset-reset: latest #最早未被消费的offset earliest max-poll-records: 3100 #批量消费一次最大拉取的数据量 enable-auto-commit: false #是否开启自动提交 auto-commit-interval: 1000 #自动提交的间隔时间 session-timeout: 20000 #连接超时时间 max-poll-interval: 15000 #手动提交设置与poll的心跳数,如果消息队列中没有消息,等待毫秒后,调用poll()方法。如果队列中有消息,立即消费消息,每次消费的消息的多少可以通过max.poll.records配置。 max-partition-fetch-bytes: 15728640 #设置拉取数据的大小,15M listener: batch-listener: true #是否开启批量消费,true表示批量消费 concurrencys: 3,6 #设置消费的线程数 poll-timeout: 1500 #只限自动提交,
3.消息实体类:
public class Message {
private Long id; //id
private String msg; //消息
private Date sendTime; //时间戳
//省略 get set
}
4.消息生产者配置:
@Configuration @EnableKafka public class KafkaProducerConfig { @Value("${kafka.producer.bootstrap-servers}") private String bootstrapServers; @Value("${kafka.producer.retries}") private Integer retries; @Value("${kafka.producer.batch-size}") private Integer batchSize; @Value("${kafka.producer.buffer-memory}") private Integer bufferMemory; @Value("${kafka.producer.linger}") private Integer linger; private Map<String, Object> producerConfigs() { Map<String, Object> props = new HashMap<>(7); props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers); props.put(ProducerConfig.RETRIES_CONFIG, retries); props.put(ProducerConfig.BATCH_SIZE_CONFIG, batchSize); props.put(ProducerConfig.LINGER_MS_CONFIG, linger); props.put(ProducerConfig.BUFFER_MEMORY_CONFIG, bufferMemory); props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class); props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class); return props; } private ProducerFactory<String, String> producerFactory() { DefaultKafkaProducerFactory<String, String> producerFactory = new DefaultKafkaProducerFactory<>(producerConfigs()); // // 开启事务 // producerFactory.transactionCapable(); // // 用来生成Transactional.id的前缀 // producerFactory.setTransactionIdPrefix("hous-"); return producerFactory; } // @Bean // public KafkaTransactionManager transactionManager() { // KafkaTransactionManager manager = new KafkaTransactionManager(producerFactory()); // return manager; // } @Bean public KafkaTemplate<String, String> kafkaTemplate() { return new KafkaTemplate<>(producerFactory()); } }
5.消息消费者配置:
@Configuration @EnableKafka public class KafkaConsumerConfig { @Value("${kafka.consumer.bootstrap-servers}") private String bootstrapServers; @Value("${kafka.consumer.enable-auto-commit}") private Boolean autoCommit; @Value("${kafka.consumer.auto-commit-interval}") private Integer autoCommitInterval; @Value("${kafka.consumer.max-poll-records}") private Integer maxPollRecords; @Value("${kafka.consumer.auto-offset-reset}") private String autoOffsetReset; @Value("#{'${kafka.listener.concurrencys}'.split(',')[0]}") private Integer concurrency3; @Value("#{'${kafka.listener.concurrencys}'.split(',')[1]}") private Integer concurrency6; @Value("${kafka.listener.poll-timeout}") private Long pollTimeout; @Value("${kafka.consumer.session-timeout}") private String sessionTimeout; @Value("${kafka.listener.batch-listener}") private Boolean batchListener; @Value("${kafka.consumer.max-poll-interval}") private Integer maxPollInterval; @Value("${kafka.consumer.max-partition-fetch-bytes}") private Integer maxPartitionFetchBytes; /** * 并发数6 * * @return */ @Bean @ConditionalOnMissingBean(name = "kafkaBatchListener6") public KafkaListenerContainerFactory<ConcurrentMessageListenerContainer<String, String>> kafkaBatchListener6() { ConcurrentKafkaListenerContainerFactory<String, String> factory = kafkaListenerContainerFactory(); // factory.setConcurrency(concurrency6); factory.setConcurrency(1); return factory; } /** * 并发数3 * * @return */ @Bean @ConditionalOnMissingBean(name = "kafkaBatchListener3") public KafkaListenerContainerFactory<ConcurrentMessageListenerContainer<String, String>> kafkaBatchListener3() { ConcurrentKafkaListenerContainerFactory<String, String> factory = kafkaListenerContainerFactory(); // factory.setConcurrency(concurrency3); factory.setConcurrency(1); return factory; } private ConcurrentKafkaListenerContainerFactory<String, String> kafkaListenerContainerFactory() { ConcurrentKafkaListenerContainerFactory<String, String> factory = new ConcurrentKafkaListenerContainerFactory<>(); factory.setConsumerFactory(consumerFactory()); //从版本1.1开始,@KafkaListener可以被配置为批量接收从Kafka话题队列中的Message。 // 要配置监听器容器工厂以创建批处理侦听器,需要设置batchListener属性为true factory.setBatchListener(batchListener); //如果消息队列中没有消息,等待timeout毫秒后,调用poll()方法。 // 如果队列中有消息,立即消费消息,每次消费的消息的多少可以通过max.poll.records配置。 //手动提交无需配置 factory.getContainerProperties().setPollTimeout(pollTimeout); //设置提交偏移量的方式, MANUAL_IMMEDIATE 表示消费一条提交一次;MANUAL表示批量提交一次 factory.getContainerProperties().setAckMode(AbstractMessageListenerContainer.AckMode.MANUAL_IMMEDIATE); return factory; } private ConsumerFactory<String, String> consumerFactory() { return new DefaultKafkaConsumerFactory<>(consumerConfigs()); } private Map<String, Object> consumerConfigs() { Map<String, Object> props = new HashMap<>(10); props.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, autoCommitInterval); props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers); props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, autoCommit); props.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, maxPollRecords); props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, autoOffsetReset); props.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, sessionTimeout); props.put(ConsumerConfig.MAX_POLL_INTERVAL_MS_CONFIG, maxPollInterval); props.put(ConsumerConfig.MAX_PARTITION_FETCH_BYTES_CONFIG, maxPartitionFetchBytes); props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); return props; } }
6.消息接收 KafkaReceiver:
@Component public class KafkaReceiver { private static Logger logger = LoggerFactory.getLogger(KafkaReceiver.class); // @KafkaListener(containerFactory = "kafkaBatchListener6", topics = {"testCopyTopic"},groupId = "testGroup") // public void listen(ConsumerRecord<?, ?> record) { // Optional<?> kafkaMessage = Optional.ofNullable(record.value()); // if (kafkaMessage.isPresent()) { // // Object message = kafkaMessage.get(); // System.out.println("----------------- record =" + record); // System.out.println("------------------ message =" + message); // } // // } @KafkaListener(containerFactory = "kafkaBatchListener6", topics = {"testCopyTopic"},groupId = "testGroup") public void batchListener(List<ConsumerRecord<?, ?>> records, Acknowledgment ack) { List<User> userList = new ArrayList<>(); try { records.forEach(record -> { System.out.println("----------------- record =" + record); System.out.println("------------------ message =" + record); }); } catch (Exception e) { log.error("Kafka监听异常" + e.getMessage(), e); } finally { ack.acknowledge();//手动提交偏移量 } } }
7.消息发送KafkaSender:
@Component
public class KafkaSender {
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
private Gson gson = new GsonBuilder().create();
//发送消息方法
public void send() {
Message message = new Message();
message.setId(System.currentTimeMillis());
message.setMsg(UUID.randomUUID().toString());
message.setSendTime(new Date());
System.out.println("+++++++++++++++++++++ message = {}"+gson.toJson(message));
kafkaTemplate.send("wuzzTopic", gson.toJson(message));
}
}
8.测试类:
@RestController
public class TestController {
@Autowired
private KafkaSender kafkaSender;
@RequestMapping(value = "/testSend.json", method = {RequestMethod.GET})
public void testSend() {
kafkaSender.send();
}
}
9.启动测试,访问对应接口。

