

Unity 如何高效的解析数据
2018-10-01 00:15 wuzhang 阅读(2545) 评论(1) 编辑 收藏 举报昨天和朋友聊天时,他遇到这么一个问题:现在有按照一定格式的数据,例如:
#code==text 此处是注释
100==确定
101==取消
key==value 这么个格式的,说白了就是怎样解析这些固定格式字符串的Key和Value而已。他们项目已经做过了数据的解析,现在他在做项目优化,发现这一块数据解析部分GC偏高,何谓GC,就是Garbage Collection,在.Net中GC是由系统自动调用的,对内存的释放和回收。程序员是特别害怕遇上GC的,数据结构设计不合理,导致系统频繁调用GC,从而导致GC的代数增加,最终结果就是你的程序就会越来越卡,直到无响应!
他就问我:“要是我,我会选择什么样的方式去解析这些数据?"
我当时不假思索:“格式固定,那就按这个固定的格式去解析,不就可以了!"
方法一:我们可以按照”==“进行分割,分割后刚好得到我们想要的Key和Value!刚好系统提供了N多分割的方法,在这里刚好用字符串的分割
string[] keyPair = Regex.Split(data,@"==",RegexOptions.IgnoreCase);
/// <summary> /// 正则表达式分割字符串 /// </summary> /// <param name="filePath">文件路径</param> /// <param name="infoDic">解析后的kv</param> public static void ParseDataTable(string filePath,ref Dictionary<string, string> infoDic) { infoDic.Clear(); if (File.Exists(filePath)) { using (FileStream fs = new FileStream(filePath,FileMode.Open,FileAccess.Read)) { StreamReader sr = new StreamReader(fs); string data = sr.ReadLine(); while (data != null) { if (data.StartsWith("#"))//忽略注释行 { data = sr.ReadLine(); continue; } else { //分割key和value string[] keyPair = Regex.Split(data,@"==",RegexOptions.IgnoreCase); if (keyPair.Length > 0) { if (!infoDic.ContainsKey(keyPair[0])) { infoDic.Add(keyPair[0], keyPair[1]); } else { Debug.LogError(string.Format("[ERROR]:Has same key:{0},value:{1}",keyPair[0],keyPair[1])); } } } data = sr.ReadLine(); } sr.Close(); fs.Close(); } } }
运行结果:
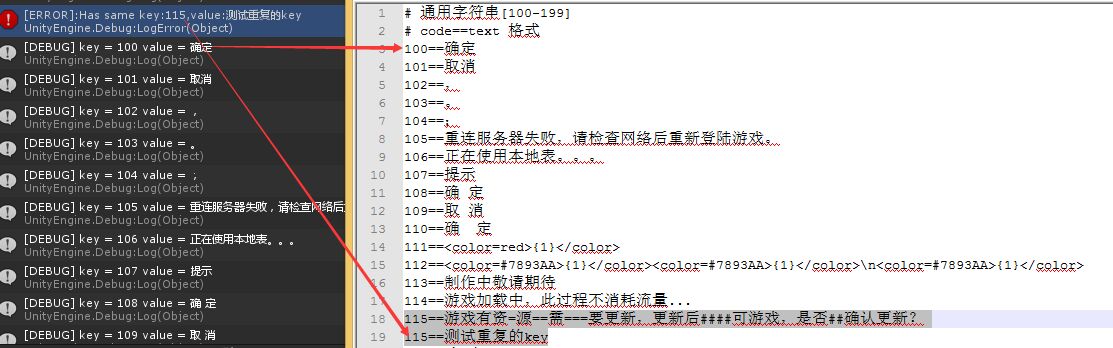
好了,方法一到此完美分割出key和value!But......
朋友说这就是他们正在使用的解析方式,正因为正则表达式使用及其的方便不需要关心它是怎么实现的所有产生大量的GC,导致我们束手无策,因为字符串匹配解析的同时会生成许多字符串临时变量,这些都要在内存堆上申请空间,在profiler中看到解析时有大概10M的GC。所以我想到的这个解析方式被否了!朋友让我继续想想有没有什么好的办法,过了一会他给我说了他的想法,为何我们不自己去写一种解析方式呢,正则耗内存,我们可以不用它,string临时变量占用内存我们也可以不用它改用StringBuilder来替代它。这么说是可行的啊!无论是我们自己解析还是使用正则去解析,这个读取还是肯定要做的,读取后针对这个string我们逐字节去解析,特殊字符就去特殊处理,添加特殊的标记,例如:
‘#’:表示该行是注释行,解析时可以忽略;
‘\n’:表示要换行了,也意味着接下来key要出现了;
‘\r’:回车键的标识符号;
‘=’:这是一个很重要的符号,这个要特殊照顾,对它采取计数,奇数个出现时刚好是key的结束位置,偶数个出现时刚好是value的起始位置,这里是不是信息量很大,你会很快的 想到计数个数对2取余做判断处理;
也就这几个关键字符,那么接下来看如何处理,取出我们想要的key和value呢!
/// <summary> /// 数据解析 /// </summary> /// <param name="msg">内容</param> /// <returns>数据字典kv</returns> public static Dictionary<string, string> ParseDatatable(string msg) { bool isKey = false; //key开始 bool isValue = false; //value开始 bool isValueStart = false; //是否value首次检测 int equalIndex = 0; // = 出现次数的计数 int valueStartIndex = 0; //Value的起始索引 StringBuilder sbKey = new StringBuilder(); StringBuilder sbvalue = new StringBuilder(); for (int i = 0; i < msg.Length; i++) { switch (msg[i]) { case '#': isKey = false; if (isValue) //收集颜色码中的# sbvalue.Append(msg[i]); break; case '\r': continue; case '\n': isKey = true; isValue = false; if (!string.IsNullOrEmpty(sbKey.ToString()) && !string.IsNullOrEmpty(sbvalue.ToString())) { if (infoDic.ContainsKey(sbKey.ToString())) Debug.LogError(string.Format("[ERROR]:has the same key:{0}, value:{1}", sbKey.ToString(), sbvalue.ToString().Replace("\\n", "\n"))); else infoDic.Add(sbKey.ToString(), sbvalue.ToString().Replace("\\n","\n")); } sbKey.Remove(0, sbKey.Length); sbvalue.Remove(0, sbvalue.Length); break; case '=': if (!isValue) //忽略value里的 = 计数 equalIndex++; if (equalIndex % 2 == 0 && equalIndex > 1)//key end { isKey = false; isValue = true; if (valueStartIndex != equalIndex) { isValueStart = true; valueStartIndex = equalIndex; } } if (isValue) { if (isValueStart && msg[i - 1] == '=')//忽略==value前最开始的那个= { isValueStart = false; continue; } sbvalue.Append(msg[i]); } break; default: if (isKey) sbKey.Append(msg[i]); else if (isValue) { if (msg[i - 1] == '\\' && msg[i + 1] == 'n')//忽略转义字符'\' continue; sbvalue.Append(msg[i]); DealEndLine((i == msg.Length - 1), ref infoDic, sbKey, sbvalue); } break; } } return infoDic; } /// <summary> /// 行尾特殊处理 /// </summary> /// <param name="lastLine">是否最后一行</param> /// <param name="dictionary">infoDic</param> /// <param name="key">key</param> /// <param name="value">value</param> public static void DealEndLine(bool lastLine, ref Dictionary<string, string> dictionary, StringBuilder key, StringBuilder value) { if (lastLine) { if (infoDic.ContainsKey(key.ToString())) Debug.Log(string.Format("[ERROR]:has the same key:{0}, value:{1}", key.ToString(), value.ToString().Replace("\\n", "\n"))); else infoDic.Add(key.ToString(), value.ToString().Replace("\\n", "\n")); } }
这是后期比较完善的代码了,这里做了以下错误兼容:
1,兼容了策划在value里配置==或者===,均不影响解析。
2,兼容了颜色码<color=#7893AA>{1}</color>的’#‘和’=‘,此处不再是特殊转义字符处理。
3,兼容了系统默认会添加"\\n"多个转义字符’\‘导致在Text上无法换行的问题。
4,兼容了策划最后一行无回车换行导致无法解析的bug。
目前就发现以上问题,对以上发现问题进行了解决!
不早了,写这么点东西花了近三个多小时,如果有幸被您读到请留下你的脚印,得洗洗睡了,明天回家了,祝大家十一玩的愉快!!!
PS:“纸上得来终觉浅 绝知此事要躬行”只有在实践中才能发现问题,交流是很好的灵感碰撞,遇到问题了多和小伙伴交流可能会有不一样的解决方案!
