Boosting 集成算法中Adaboost、GBDT与XGBoost的区别
所谓集成学习,是指构建多个分类器(弱分类器)对数据集进行预测,然后用某种策略将多个分类器预测的结果集成起来,作为最终预测结果。通俗比喻就是“三个臭皮匠赛过诸葛亮”,或一个公司董事会上的各董事投票决策,它要求每个弱分类器具备一定的“准确性”,分类器之间具备“差异性”。
Bagging和Boosting的区别
1)样本选择上:
Bagging:训练集是在原始集中有放回选取的,从原始集中选出的各轮训练集之间是独立的。
Boosting:每一轮的训练集不变,只是训练集中每个样例在分类器中的权重发生变化。而权值是根据上一轮的分类结果进行调整。
2)样例权重:
Bagging:使用均匀取样,每个样例的权重相等
Boosting:根据错误率不断调整样例的权值,错误率越大则权重越大。
3)预测函数:
Bagging:所有预测函数的权重相等。
Boosting:每个弱分类器都有相应的权重,对于分类误差小的分类器会有更大的权重。
4)并行计算:
Bagging:各个预测函数可以并行生成
Boosting:各个预测函数只能顺序生成,因为后一个模型参数需要前一轮模型的结果。
Adaboost
介绍
- 初始化训练数据的权值分布。如果有N个样本,则每一个训练样本最开始时都被赋予相同的权值:1/N。
- 训练弱分类器。具体训练过程中,如果某个样本点已经被准确地分类,那么在构造下一个训练集中,它的权值就被降低;相反,如果某个样本点没有被准确地分类,那么它的权值就得到提高。然后,权值更新过的样本集被用于训练下一个分类器,整个训练过程如此迭代地进行下去。
- 将各个训练得到的弱分类器组合成强分类器。各个弱分类器的训练过程结束后,加大分类误差率小的弱分类器的权重,使其在最终的分类函数中起着较大的决定作用,而降低分类误差率大的弱分类器的权重,使其在最终的分类函数中起着较小的决定作用。换言之,误差率低的弱分类器在最终分类器中占的权重较大,否则较小。
优点
1. Adaboost是一种有很高精度的分类器;
2. 可以使用各种方法构建子分类器,Adaboost算法提供的是框架;
3. 当使用简单分类器时,计算出的结果是可以理解的,并且弱分类器的构造极其简单;
4. 简单,不用做特征筛选;
5. 不易发生overfitting(过拟合)。
缺点
1. 对outlier(离群值)比较敏感。
2. AdaBoost迭代次数也就是弱分类器数目不太好设定,可以使用交叉验证来进行确定;
3. 训练比较耗时,每次重新选择当前分类器最好切分点。
应用领域:
模式识别、计算机视觉领域,用于二分类和多分类场景
GBDT(Gradient Boost Decision Tree)
介绍


优点:
- 预测精度高
- 适合低维数据
- 能处理非线性数据
- 可以灵活处理各种类型的数据,包括连续值和离散值。
- 在相对少的调参时间情况下,预测的准备率也可以比较高。这个是相对SVM来说的。
- 使用一些健壮的损失函数,对异常值的鲁棒性非常强。比如 Huber损失函数和Quantile损失函数。
缺点:
- 由于弱学习器之间存在依赖关系,难以并行训练数据。不过可以通过自采样的SGBT来达到部分并行。
- 如果数据维度较高时会加大算法的计算复杂度
XGBoost
XGBoost树的定义
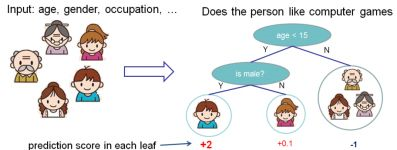
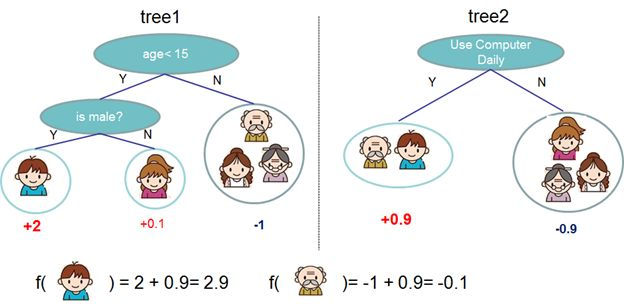
就这样,训练出了2棵树tree1和tree2,类似之前gbdt的原理,两棵树的结论累加起来便是最终的结论,所以小孩的预测分数就是两棵树中小孩所落到的结点的分数相加:2 + 0.9 = 2.9。爷爷的预测分数同理:-1 + (-0.9)= -1.9。具体如下图所示

XGBoost目标函数
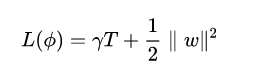
优点:
1)GBDT以传统CART作为基分类器,而xgBoosting支持线性分类器,相当于引入L1和L2正则化项的逻辑回归(分类问题)和线性回归(回归问题);
2)GBDT在优化时只用到一阶导数,xgBoosting对代价函数做了二阶Talor展开,引入了一阶导数和二阶导数;
3)当样本存在缺失值是,xgBoosting能自动学习分裂方向;
4)xgBoosting借鉴RF的做法,支持列抽样,这样不仅能防止过拟合,还能降低计算;
5)xgBoosting的代价函数引入正则化项,控制了模型的复杂度,正则化项包含全部叶子节点的个数,每个叶子节点输出的score的L2模的平方和。从贝叶斯方差角度考虑,正则项降低了模型的方差,防止模型过拟合;
6)xgBoosting在每次迭代之后,为叶子结点分配学习速率,降低每棵树的权重,减少每棵树的影响,为后面提供更好的学习空间;
缺点:
1)xgBoosting采用预排序,在迭代之前,对结点的特征做预排序,遍历选择最优分割点,数据量大时,贪心法耗时,LightGBM方法采用histogram算法,占用的内存低,数据分割的复杂度更低;
2)xgBoosting采用level-wise生成决策树,同时分裂同一层的叶子,从而进行多线程优化,不容易过拟合,但很多叶子节点的分裂增益较低,没必要进行跟进一步的分裂,这就带来了不必要的开销;
总结:
- Adaboost与GBDT两者boosting的不同策略是两者的本质区别。
- Adaboost强调Adaptive(自适应),通过不断修改样本权重(增大分错样本权重,降低分对样本权重),不断加入弱分类器进行boosting。
- 而GBDT则是旨在不断减少残差(回归),通过不断加入新的树旨在在残差减少(负梯度)的方向上建立一个新的模型。——即损失函数是旨在最快速度降低残差。
- 而XGBoost的boosting策略则与GBDT类似,区别在于GBDT旨在通过不断加入新的树最快速度降低残差,而XGBoost则可以人为定义损失函数(可以是最小平方差、logistic loss function、hinge loss function或者人为定义的loss function),只需要知道该loss function对参数的一阶、二阶导数便可以进行boosting,其进一步增大了模型的泛华能力,其贪婪法寻找添加树的结构以及loss function中的损失函数与正则项等一系列策略也使得XGBoost预测更准确。
- XGBoost的具体策略可参考本专栏的XGBoost详述。 GBDT每一次的计算是都为了减少上一次的残差,进而在残差减少(负梯度)的方向上建立一个新的模型。
- XGBoost则可以自定义一套损失函数,借助泰勒展开(只需知道损失函数的一阶、二阶导数即可求出损失函数)转换为一元二次函数,得到极值点与对应极值即为所求。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号