系统性能监控
一、Linux系统性能监控
- uptime
[root@iZwz963wlhi02sxk6nk1j5Z ~]# uptime
10:31:09 up 41 days, 22:42, 1 user, load average: 3.37, 2.76, 2.70
这几个参数分别表示:
①. 10:31:09 up 41 days(当前时间,系统开机41天)
②. 22:42(系统的启动时间)
③. 1 user(系统的连接数,这个是一个终端增加一个,而不是一个用户一个)
④. load average: 3.37, 2.76, 2.70(系统一分钟平均负载,5分钟平均负载,十五分钟平均负载,它表示运行系统队列中的平均进程数,数值越大表示负载越重)
- top
top - 10:55:15 up 41 days, 23:06, 1 user, load average: 3.72, 2.63, 2.56 Tasks: 68 total, 1 running, 67 sleeping, 0 stopped, 0 zombie %Cpu(s):100.0 us, 0.0 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st KiB Mem : 1883724 total, 87576 free, 433912 used, 1362236 buff/cache KiB Swap: 0 total, 0 free, 0 used. 1196012 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 18850 root 20 0 44752 2424 196 S 99.0 0.1 1586:36 qW3xT.2 1289 root 20 0 2074504 71516 8808 S 0.7 3.8 265:34.21 java 18725 root 20 0 371584 94888 4500 S 0.7 5.0 3:27.05 ddgs.3013 11971 root 20 0 131004 11500 9128 S 0.3 0.6 138:30.16 AliYunDun
这几个参数分别表示:
①. 第一行表示的为uptime命令执行的结果。
②. Tasks:68 total,1 running,67 sleeping,0 stopped,0 zombie(进程情况:总进程为68个,运行的进程为1个,67个进程为休眠状态,僵死的进程为0个,终止的进程为0个)
③. %Cpu(s):100.0 us,0.0 sy,0.0 ni,0.0 id,0.0 wa,0.0 hi,0.0 si,0.0 st(CPU状态,us用户占用为100%,sy系统占用为0,ni优先占用为0,id闲置占用为0,wa等待输入输出占用为0如果此项过高表示系统磁盘io过高,hi硬中断(Hardware IRQ)占用CPU的百分比为0,si软中断(Software Interrupts)占用CPU的百分比为0,st用于有虚拟cpu的情况,用来指示被虚拟机偷掉的cpu时间)
④. KiB Mem: 1883724 total,87576 free,433912 used,1362236 buff/cache(内存,total总的物理内存,used使用物理内存大小,free空闲物理内存,buff/cache用于内核缓存的内存大小)
⑤. KiB Swap:0 total,0 free,0 used. 1196012 avail Mem (total总的交换空间大小,used已经使用交换空间大小,free空间交换空间大小,cached缓冲的交换空间大小。buff和cached区别:buffers指的是块设备的读写缓冲区,cached指的是文件系统本身的页面缓存。他们都是Linux系统底层的机制,为了加速对磁盘的访问。)
⑥. PID(进程号),USER(运行用户),PR(优先级,它其实就是进程调度器分配给进程的时间片长度,单位是时钟个数,那么一个时钟需要多长时间呢?这
跟CPU的主频以及操作系统平台有关,比如linux上一般为10ms,那么PR值为15则表示这个进程的时间片为150ms),NI(任务nice值),VIRT(进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES),RES(物理内存用量),SHR(共享内存用量),S(该进程的状态。其中S代表休眠状态;D代表不可中断的休眠状态;R代表运行状态;Z代表僵死状态;T代表停止或跟踪状态), %CPU(该进程自最近一次刷新以来所占用的CPU时间和总时间的百分比),%MEM(该进程占用的物理内存占总内存的百分比),TIME+(累计cpu占用时间),COMMAND(该进程的命令名称)
- vmstat 统计cpu,内存,swap,io等情况(可以在后面加2个int的参数 vmstat 1 3 表示 1秒统计一次,一个统计3次)
[root@iZwz963wlhi02sxk6nk1j5Z ~]# vmstat 1 3
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
4 0 0 86592 143772 1219112 0 0 0 4 10 7 3 0 96 0 0
3 0 0 86576 143772 1219112 0 0 0 0 1273 446 99 1 0 0 0
1 0 0 86436 143772 1219112 0 0 0 0 1290 523 100 0 0 0 0
这几个参数分别表示:
①. procs
r:置于运行队列中的内核线程数目(就是说多少个进程真的分配到CPU),我测试的服务器为阿里云的轻量级服务器目前CPU比较忙,值已经大于cpu数量,当这个值超过了CPU数目,就会出现CPU瓶颈了。这个也和top的负载有关系,一般负载超过了3就比较高,超过了5就高,超过了10就不正常了,服务器的状态很危险。top的负载类似每秒的运行队列。如果运行队列过大,表示你的CPU很繁忙,一般会造成CPU使用率很高。
b:置于等待队列(等待资源、等待输入/输出)的内核线程数目,也就是阻塞的进程。
②. memory
swpd:虚拟内存已使用的大小,如果大于0,表示你的机器物理内存不足了,如果不是程序内存泄露的原因,那么你该升级内存了或者把耗内存的任务迁移到其他机器。
free:空闲的物理内存的大小,此时我的剩余内存为85M左右,因为我的机器内存总共为2G,所以剩余内存比较少。
buff: Linux/Unix系统是用来存储,目录里面有什么内容,权限等的缓存,我本机大概占用140多M
cache:用来记忆我们打开的文件,给文件做缓冲,我本机大概占用差不多1G(这里是Linux/Unix的聪明之处,把空闲的物理内存的一部分拿来做文件和目录的缓存,是为了提高 程序执行的性能,当程序使用内存时,buffer/cached会很快地被使用。)
③. swap
si:每秒从磁盘读入虚拟内存的大小,如果这个值大于0,表示物理内存不够用或者内存泄露了,要查找耗内存进程解决掉。
so:每秒虚拟内存写入磁盘的大小,如果这个值大于0,表示物理内存不够用或者内存泄露了,要查找耗内存进程解决掉。
④. io
bi:块设备每秒接收的块数量,这里的块设备是指系统上所有的磁盘和其他块设备,默认块大小是1024byte.
bo:块设备每秒发送的块数量,例如我们读取文件,bo就要大于0。bi和bo一般都要接近0,不然就是IO过于频繁,需要调整。
⑤. system
in:每秒CPU的中断次数,包括时间中断
cs:每秒上下文切换次数,例如我们调用系统函数,就要进行上下文切换,线程的切换,也要进程上下文切换,这个值要越小越好,太大了,要考虑调低线程或者进程的数目,例如在apache和nginx这种web服务器中,我们一般做性能测试时会进行几千并发甚至几万并发的测试,选择web服务器的进程可以由进程或者线程的峰值一直下调,压测,直到cs到一个比较小的值,这个进程和线程数就是比较合适的值了。系统调用也是,每次调用系统函数,我们的代码就会进入内核空间,导致上下文切换,这个是很耗资源,也要尽量避免频繁调用系统函数。上下文切换次数过多表示你的CPU大部分浪费在上下文切换,导致CPU干正经事的时间少了,CPU没有充分利用,是不可取的。
⑥. cpu
us: 用户CPU时间.
sy: 系统CPU时间,如果太高,表示系统调用时间长,例如是IO操作频繁。
id: 空闲 CPU时间,一般来说,id + us + sy = 100,一般我认为id是空闲CPU使用率,us是用户CPU使用率,sy是系统CPU使用率。
wa:CPU 空闲时间,在此期间系统有未完成的磁盘/NFS I/O 请求。
st:从虚拟机中偷走的百分比(如果正在使用虚拟机话,有此列,虚拟机想运行但是系统管理程序转而运行其的对象的时间,如果虚拟机不希望运行任何对象,但是系统管理员运行了其他对象,这不算被偷走的cpu时间)
- pidstat [选项] [<时间间隔>] [<次数>](细致观察进程,非自带需要安装 sudo apt-get install sysstat)
[root@iZwz963wlhi02sxk6nk1j5Z ~]# pidstat -help Usage: pidstat [ options ] [ <interval> [ <count> ] ] Options are: [ -d ] [ -h ] [ -I ] [ -l ] [ -r ] [ -s ] [ -t ] [ -U [ <username> ] ] [ -u ] [ -V ] [ -w ] [ -C <command> ] [ -p { <pid> [,...] | SELF | ALL } ] [ -T { TASK | CHILD | ALL } ]
下面是pidstat的用法:
-d:显示各个进程的IO使用情况.
-h:在一行上显示了所有活动,这样其他程序可以容易解析。
-I:在SMP环境,表示任务的CPU使用率/内核数量。
-l:显示命令名和所有参数。
-r:显示各个进程的内存使用统计
-s:堆栈的使用
-t:显示选择任务的线程的统计信息外的额外信息
-U [ ]:可按照用户名,显示各个进程的cpu使用统计
-u:默认的参数,显示各个进程的cpu使用统计
-V:版本号
-w:显示每个进程的上下文切换情况
-C :只显示那些包含字符串(可是正则表达式)comm的命令的名字
-p { [,…] | SELF | ALL }:指定进程号
-T { TASK | CHILD | ALL }:这个选项指定了pidstat监控的。TASK表示报告独立的task,CHILD关键字表示报告进程下所有线程统计信息。ALL表示报告独立的task和task下面的所有线程。注意:task和子线程的全局的统计信息和pidstat选项无关。这些统计信息不会对应到当前的统计间隔,这些统计信息只有在子线程kill或者完成的时候才会被收集。
- pidstat -u -p ALL(与pidstat效果一样,默认查询所有进程的使用情况)
[root@iZwz963wlhi02sxk6nk1j5Z ~]# pidstat Linux 3.10.0-514.26.2.el7.x86_64 (iZwz963wlhi02sxk6nk1j5Z) 10/15/2018 _x86_64_ (1 CPU) 05:45:12 PM UID PID %usr %system %guest %CPU CPU Command 05:45:12 PM 0 1 0.00 0.00 0.00 0.00 0 systemd 05:45:12 PM 0 3 0.00 0.00 0.00 0.00 0 ksoftirqd/0 05:45:12 PM 0 9 0.00 0.01 0.00 0.01 0 rcu_sched 05:45:12 PM 0 10 0.00 0.00 0.00 0.00 0 watchdog/0
各个参数的含义:
①. Linux 3.10.0-514.26.2.el7.x86_64 (iZwz963wlhi02sxk6nk1j5Z) 10/15/2018 x86_64(1 CPU):系统版本 日期 位数 cpu个数
②. 05:45:12 PM 时间
③. UID 用户ID
④. PID 进程ID
⑤. %usr 进程在用户空间占用cpu的百分比
⑥. %system 进程在内核空间占用cpu的百分比
⑦. %guest 进程在虚拟机占用cpu的百分比
⑧. %CPU 进程占用cpu的百分比
⑨. CPU 处理进程的cpu编号
⑩. Command 当前进程对应的命令
- pidstat -r (显示各个进程的内存使用统计)
Linux 3.10.0-514.26.2.el7.x86_64 (iZwz963wlhi02sxk6nk1j5Z) 10/15/2018 _x86_64_ (1 CPU) 06:03:16 PM UID PID minflt/s majflt/s VSZ RSS %MEM Command 06:03:16 PM 0 1 0.06 0.00 125132 3656 0.19 systemd 06:03:16 PM 0 325 0.08 0.00 36816 2440 0.13 systemd-journal 06:03:16 PM 0 344 0.00 0.00 43768 2040 0.11 systemd-udevd 06:03:16 PM 998 429 0.00 0.00 527616 13048 0.69 polkitd
各个参数含义:
①. 06:03:16 PM 时间
②. UID 用户ID
③. PID 进程ID
④. minflt/s 任务每秒发生的次要错误,不需要从磁盘中加载页
⑤. majflt/s 任务每秒发生的主要错误,需要从磁盘中加载页
⑥. VSZ 虚拟地址大小,虚拟内存的使用KB
⑦. RSS 常驻集合大小,非交换区物理内存使用KB
⑧. %MEM 该进程使用内存的百分比
⑨. Command 当前进程对应的命令
- pidstat -d(显示各个进程的IO使用情况)
[root@iZwz963wlhi02sxk6nk1j5Z ~]# pidstat -d Linux 3.10.0-514.26.2.el7.x86_64 (iZwz963wlhi02sxk6nk1j5Z) 10/15/2018 _x86_64_ (1 CPU) 06:17:46 PM UID PID kB_rd/s kB_wr/s kB_ccwr/s Command 06:17:46 PM 0 1 0.10 0.76 0.03 systemd 06:17:46 PM 0 27 0.00 0.00 0.00 khugepaged 06:17:46 PM 0 257 0.00 0.57 0.00 jbd2/vda1-8 06:17:46 PM 0 325 0.00 0.00 0.00 systemd-journal 06:17:46 PM 0 344 0.00 0.00 0.00 systemd-udevd
各个参数含义:
①. 06:03:16 PM 时间
②. UID 用户ID
③. PID 进程ID
④. kB_rd/s 每秒从磁盘读取的KB
⑤. kB_wr/s 每秒写入磁盘KB
⑥. kB_ccwr/s 任务取消的写入磁盘的KB。当任务截断脏的pagecache的时候会发生。
⑦. Command 当前进程对应的命令
- pidstat -w -p ALL
[root@iZwz963wlhi02sxk6nk1j5Z soundCodeRead]# pidstat -w -p ALL Linux 3.10.0-514.26.2.el7.x86_64 (iZwz963wlhi02sxk6nk1j5Z) 10/16/2018 _x86_64_ (1 CPU) 09:48:35 AM UID PID cswch/s nvcswch/s Command 09:48:35 AM 0 1 0.04 0.00 systemd 09:48:35 AM 0 2 0.00 0.00 kthreadd 09:48:35 AM 0 3 1.44 0.00 ksoftirqd/0 09:48:35 AM 0 5 0.00 0.00 kworker/0:0H
各个参数含义:
①. 06:03:16 PM 时间
②. UID 用户ID
③. PID 进程ID
④. cswch/s 每秒主动任务上下文切换数量
⑤. nvcswch/s 每秒被动任务上下文切换数量
⑥. Command 当前进程对应的命令
- pidstat -T ALL
[root@iZwz963wlhi02sxk6nk1j5Z ~]# pidstat -T ALL Linux 3.10.0-514.26.2.el7.x86_64 (iZwz963wlhi02sxk6nk1j5Z) 10/16/2018 _x86_64_ (1 CPU) 05:26:26 PM UID PID %usr %system %guest %CPU CPU Command 05:26:26 PM 0 1 0.00 0.00 0.00 0.00 0 systemd 05:26:26 PM 0 3 0.00 0.00 0.00 0.00 0 ksoftirqd/0 05:26:26 PM 0 9 0.00 0.01 0.00 0.01 0 rcu_sched 05:26:26 PM 0 10 0.00 0.00 0.00 0.00 0 watchdog/0 05:26:26 PM UID PID usr-ms system-ms guest-ms Command 05:26:26 PM 0 1 176587710 189400 0 systemd 05:26:26 PM 0 3 0 23740 0 ksoftirqd/0 05:26:26 PM 0 9 0 535150 0 rcu_sched 05:26:26 PM 0 10 0 15000 0 watchdog/0
各个参数的含义:
①. 上面第一个表格中的数据为进程的数据与直接输入pidstat的一致。
②. usr-ms:任务和子线程在用户级别使用的毫秒数。
③. system-ms:任务和子线程在系统级别使用的毫秒数。
④. guest-ms:任务和子线程在虚拟机(running a virtual processor)使用的毫秒数。
二、windows 性能监控
- 任务管理器
绝大多数人都知道任务管理器可以杀死进程,杀死应用,但是很多人也只是会这些,对于系统性能监控就不懂了,任务管理器是windows自带的性能监控工具,他可以全局监控计算机整体的性能,也可以单体监控某个进程的性能。
①. 计算机整体性能
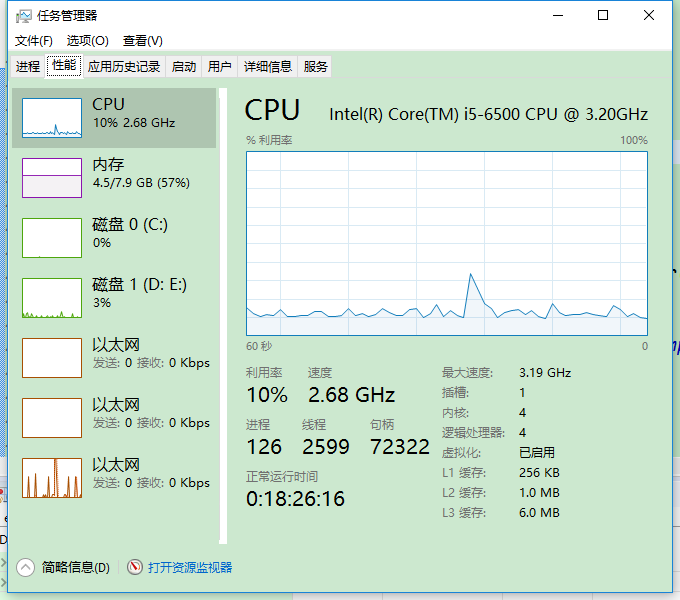
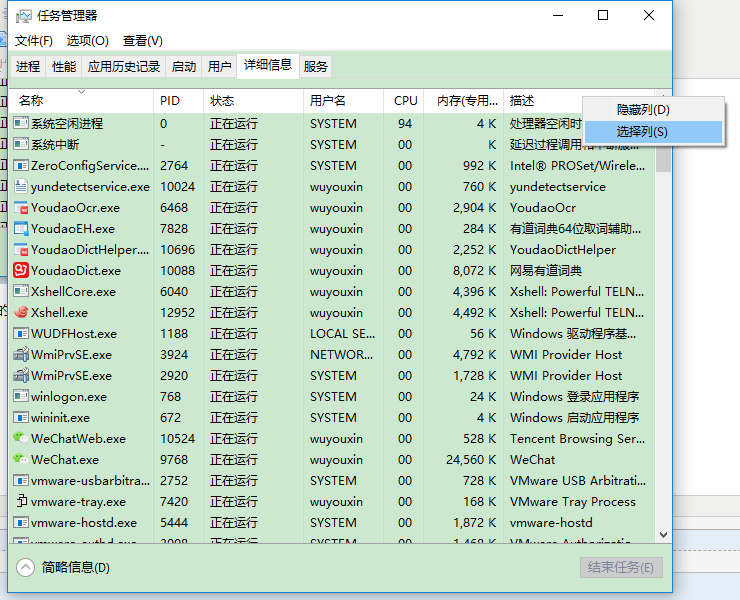
②. 进程详细信息

这里还可以右键列选择要监控的项。
- Perfmon
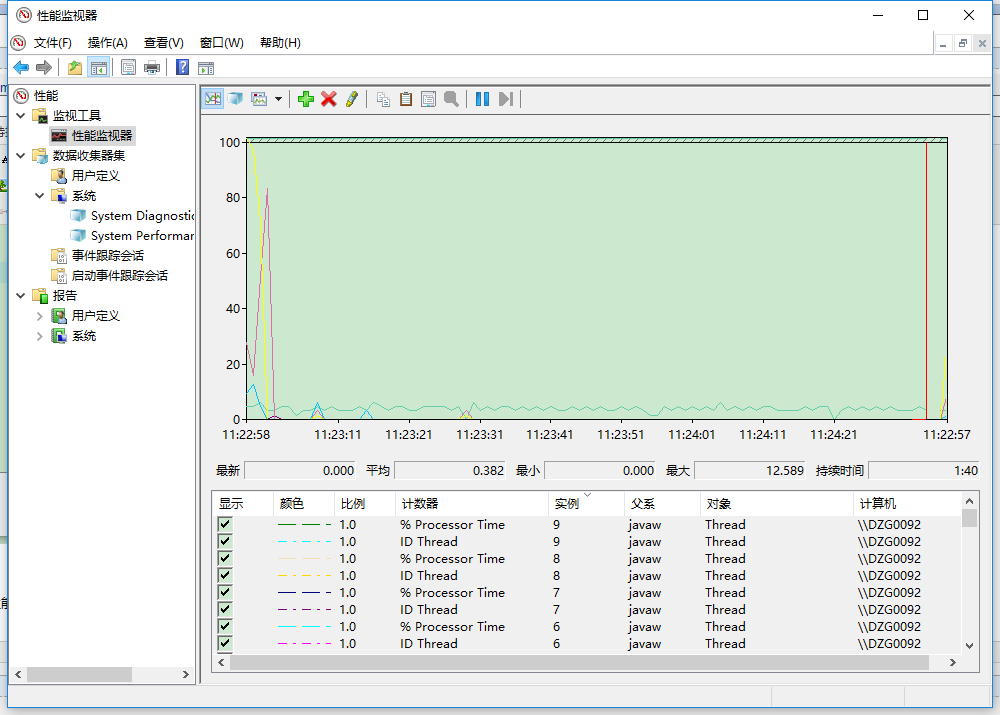
windows自带的性能监控工具,在命令行中直接输入Perfmon就可以打开。
我们在windows中启动一个java项目,我们在其中怎么找到这些线程呢?
右键添加计数器

找到后将之添加进去,我们查效果,起初是相对稳定的。
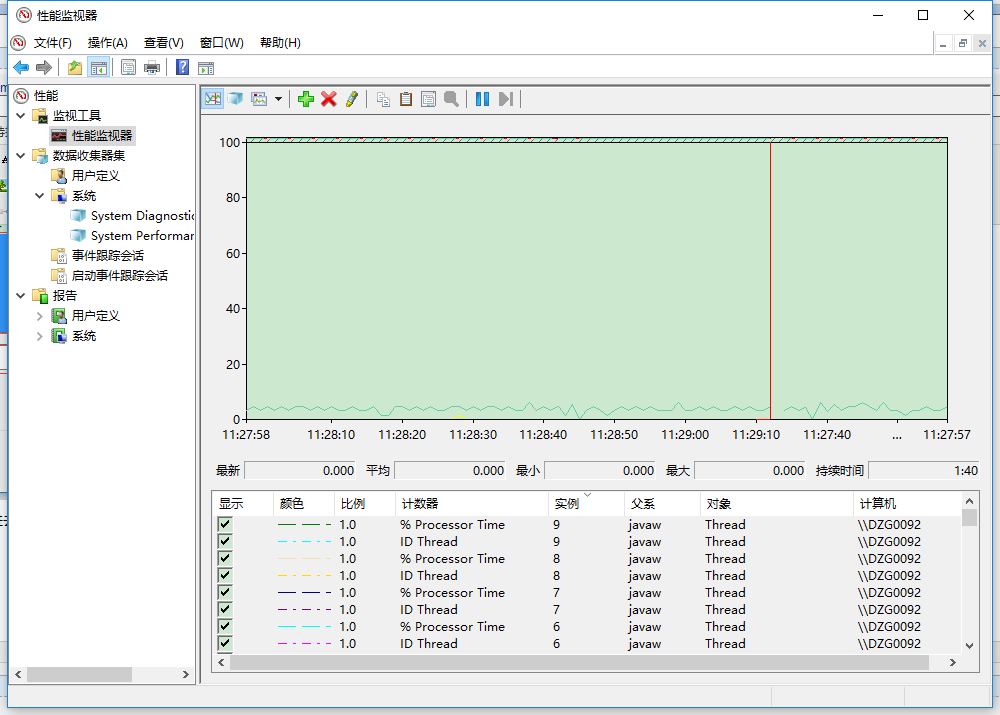
在本地发起一些请求,就会发生一些变化。

而且我们也可以直接查看报告。
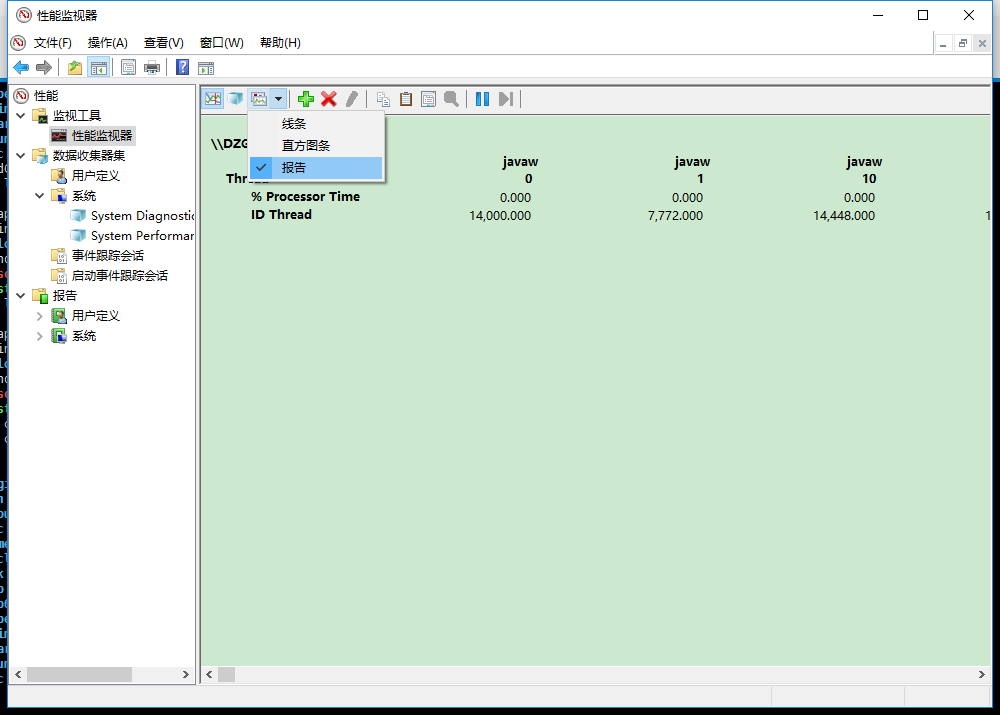
从这里我们可以找到一些占用cpu过高的线程,从而通过线程id去找是具体程序中的哪个线程。上图中的 % Processor Time 是所有进程线程使用处理器执行指令所花的时间百分比。而ID Thread 则是线程号。我在这里值列举了两个参数,如果大家感兴趣可以参考 (Perfmon - Windows 自带系统监控工具)。
- Process Explorer
Process Explorer也是一个性能监控的工具,但是不是windows自带的工具,需要自己下载。(下载地址)

Process Explorer 有个优点就是可以将一个进程按照树形结构进行展示,上图为我自己的eclipse中运行的java项目的进程。双击进程也可以查看进程中线程的信息。
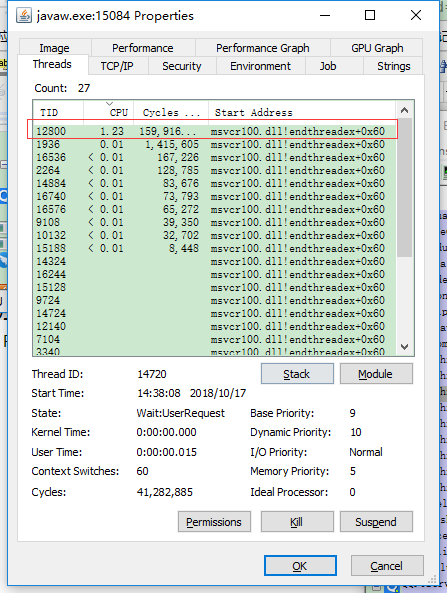
我们从上图可以看出线程 12800 对cpu占用最高。
上述为 Process Explorer 的简单应用,如果有兴趣可以查看( Process Explorer常用操作介绍).
参考文章:
-------------------- END ---------------------
最后附上作者的微信公众号地址和博客地址
公众号:wuyouxin_gzh

Herrt灬凌夜:https://www.cnblogs.com/wuyx/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号