

优先级队列
优先级队列(完全二叉树)
- 体会优先级的概念,优先级的作用。比如getMax() delMax() insert() 的高效需求。
- 思考:为什么不用向量实现优先级队列?查询效率,摘除的效率低。O(n)。
- 思考:为什么不用有序向量实现优先级队列?插入效率低。O(n)。
- 可以用AVL,伸展树,红黑树实现优先级队列吗?答案是:可以。不过 ----“杀鸡焉用牛刀”
优先级队列在逻辑上等同于完全二叉树,在物理上可以用向量实现。我们只需要get_max 和 delete_max 操作。
一,完全二叉树的插入和上滤:直接将插入的元素放入向量末尾,进行上滤。如若不满足堆序性,则交换该节点和父节点的位置,逐层调整。最坏O(logn),通常情况下上升的层数为常数。
常系数效率的改进:在上滤的过程中最多上升logn层,每上升一层都要进行一次swap 操作 需要3logn的赋值。--》可以减少赋值操作,发生上滤的时刻,我们只需将父节点下移,直到不再上滤,再将该节点赋值到该位置logn+2。
二,完全二叉树的删除和下滤:删除max节点后,将末尾元素移至堆顶,进行下滤。 如若不满足堆序性,则交换该节点和较大子节点的位置,逐层调整。最坏O(logn)。
常系数效率的改进:与上滤同。
三,批量建堆:
- 自上而下的上滤O(nlogn):一个一个的插入,但是代价比较大。
- 自下而上的下滤O(n):我们可以采用自下而上的建立,对每一个节点进行下滤,即可快速建堆。
- 两种算法的差异,自上而下正比于其深度,自下而上正比于其高度。--好似人类社会金字塔。sum(height(i)) = O(n), sum(depth(i)) = O(nlogn)
四,堆排序
选择排序 :O(n^2),选择排序分成已排序和未排序两部分,用向量存储未排序的部分,逐个从未排序部分选出最大值放入已排序部分。
堆排序:就是用更高级的数据结构去组织未排序部分,建立一个堆,从中一个一个的取出最大元。
堆排序的时间 建堆需要O(n),取最大元需要logn,取n次 总:O(nlogn)。
堆排序的空间 可以就地完成:只需要对向量的元素从后往前逐个进行和max节点交换和下滤操作。
五,左式堆
为什么引入新的变种左式堆? --更加高效的完成两个堆的合并。
合并两个堆可以采用自下而上的批量建堆的方法 ,时间复杂度位O(n)。--》不满意
我们没有利用好两个堆已有的特点。--》更高效的方法--》左式堆。
合并两个m 和 n的堆的时间复杂度O(logm + logn)
左式堆已经不是一棵完全二叉树了,但是又何妨?。
NPL(NULL path length):是该点到外部节点的最近距离,是以该点为根的极大满子树的高度。
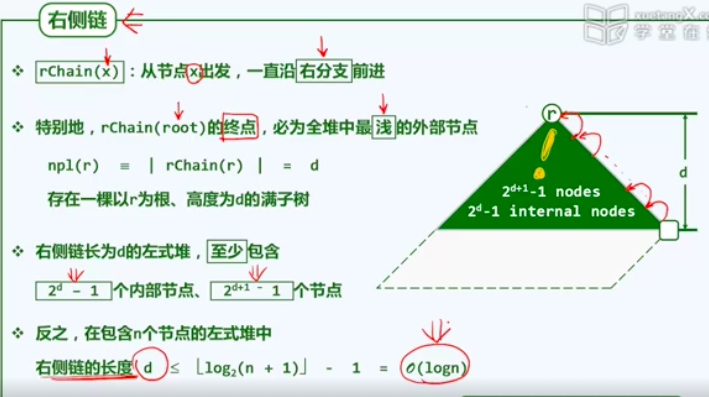
左式堆:保持堆序性质,附加新条件,使得在堆合并过程中,只要调整很少部分的节点 O(logn)。
新条件:单侧倾斜,节点倾向于左侧,合并操作只涉及右侧。
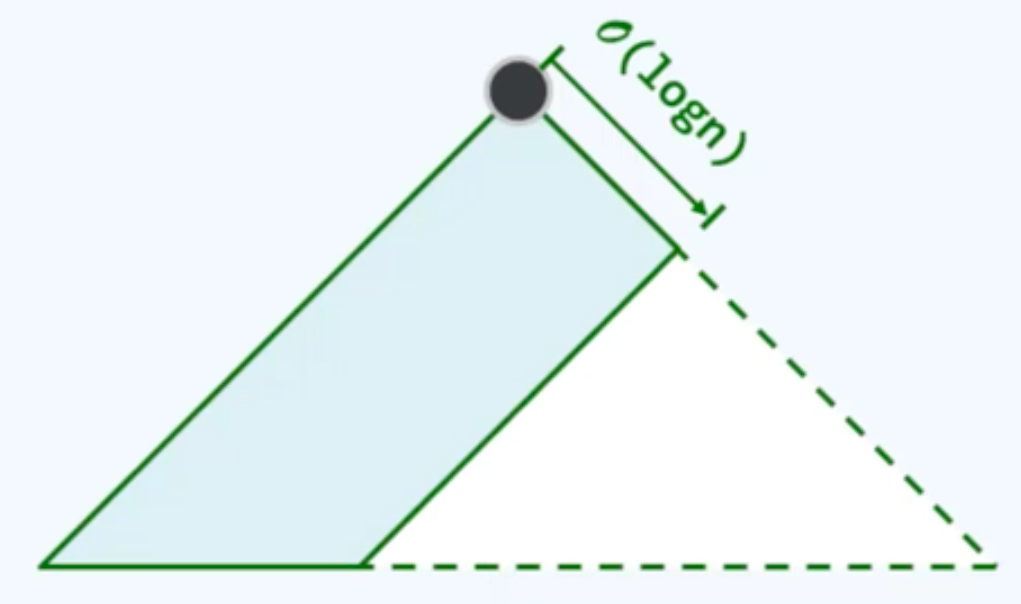
左倾性:对任何内部节点,都有npl ( lc( x ) ) >= npl ( rc( x ) ),npl ( x ) = 1 + npl( rc(x)) ,npl(x)= 1 + min(npl(l c(x)), npl ( rc (x) )。
左式堆的子堆必是左式堆,更多节点倾向于左侧。
合并时间复杂度:
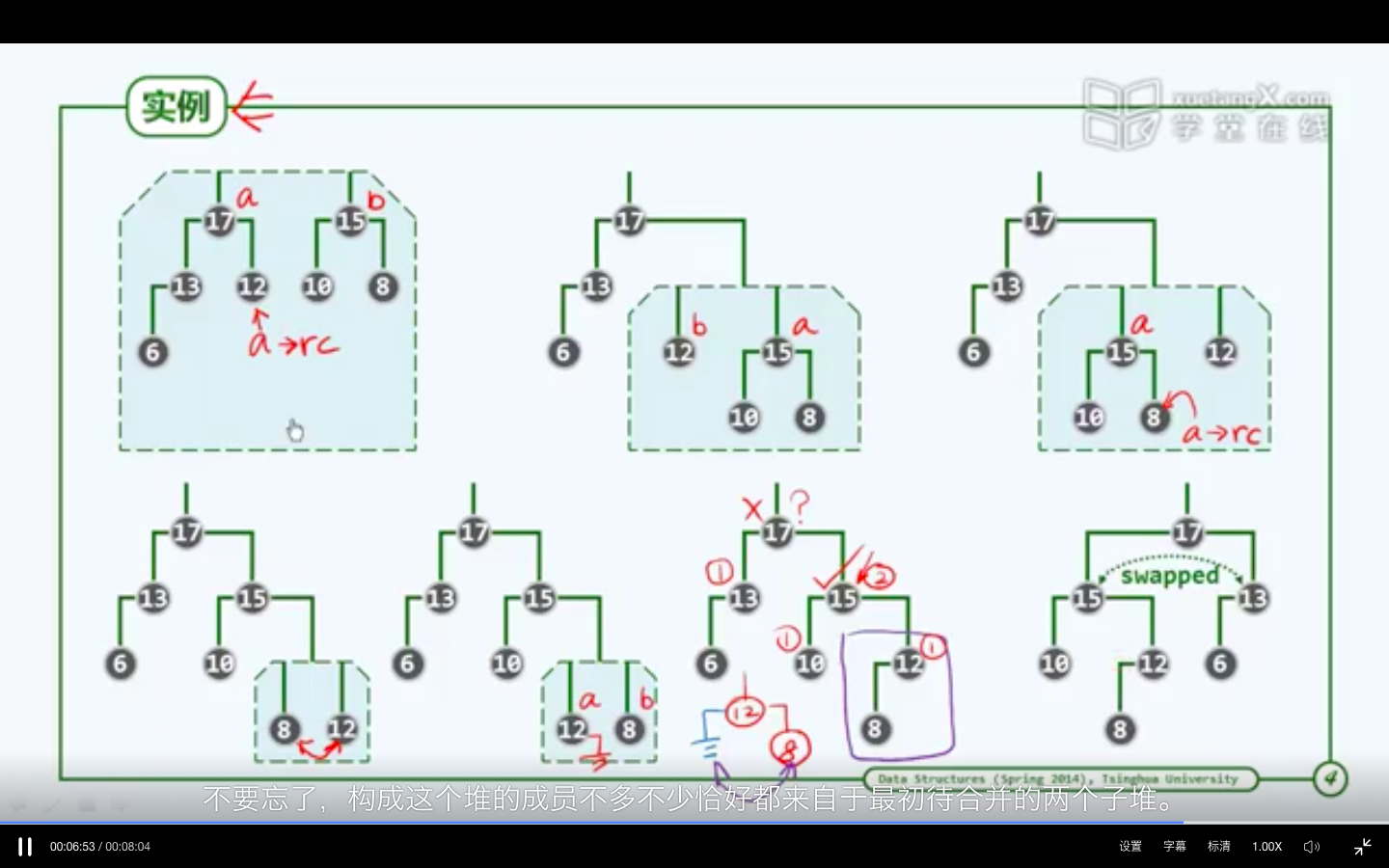
左式堆的合并算法:递归,有AB两个堆,将A的右子堆取出与B合并,合并的结果继续作为A的右子堆,在合并返回之后,比较npl值,调整位置。整个过程依据右侧链进行,O(logn)。
(插入删除皆是合并)。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix