

 一万字梳理C++所有知识点
一万字梳理C++所有知识点
最简单的C++程序
#include <iostream>
using namespace std;
int main()
{
cout << "hello C++" << endl;
system("pause");
return 0;
}使用C语言第三方库
在C++中如何使用C语言打包好的库函数
extern "C"
{
#include <libjpeg.h>
}内存分配
空间分配原则是以“连续空闲”为核心的
-
运行某个程序后,一定会向内存申请空间
-
分配内存时,内存空间一定是连续的
-
分配出来的空间,是不确定位置的
注释
单行注释:
//一行的注释内容
多行注释:(模块化注释)
/*
多行的注释内容
多行的注释内容
*/
变量
作用:申请一段内存空间,给其取一个变量名,方便我们管理内存空间
数据类型 变量名 = 初始值
示例: int i
官方含义:在内存中申请连续的4个字节,由变量i去间接访问这块4字节的内存
全局变量/局部变量
-
全局变量是定义在函数之外,局部变量定义在函数之内;
-
全部变量在编译时分配空间,局部变量在运行时才分配空间;
常量
作用:指的是那些不可被更改的数据
两种表示方法:
1、#define 宏常量
#define 常量名 常量值
2、const修饰的变量
const 数据类型 常量名 = 常量值
关键字
作用:C++中被已经被用掉的标识符
注意事项:自定义标识符的时候,不要用到C++用到的关键字
标识符
标识符命名规则:
-
不能是关键字
-
只有由字母、数字、下划线组成
-
第一个字符不能是数字
-
区分大小写
扩展规则:(也就是按实际情况去取舍)
-
尽可能包含更多信息
-
尽可能让名字更有意义
-
尽可能不要太长
建议:命名标识符的时候,尽量做到见名知意,方便阅读
数据类型
在创建变量或者常量的时候,必须指明相应的数据类型,否则无法成功分配内存。
整型
作用:给数据分配相对应的内存空间。
四种整型类型:
|
数据类型 |
内存大小 |
取值范围 |
|---|---|---|
|
int(整型) |
4个字节 |
-2^31 ~ 2^31-1 |
|
short(短整型) |
2个字节 |
-2^15 ~ 2^15-1 |
|
long(长整型) |
4个字节(window环境下) |
-2^31 ~ 2^31-1 |
|
long long(长长整型) |
8个字节 |
-2^63 ~ 2^63-1 |
实型(浮点型)
作用:用来表示小数
两种分类:
|
数据类型 |
内存大小 |
取值范围 |
|---|---|---|
|
float(单精度) |
4个字节 |
小数点后7位有效数字 |
|
double(双精度) |
8个字节 |
小数点后16位有效数字 |
字符型
作用:用来显示单个字符
语法:char ch = ‘a’
内存空间:C/C++ 只占用1个字节
注意事项:字符型变量不是把字符本身放到内存空间中,放进去的是字符对应的ASCII编码
字符串型
作用:用于显示一串字符
两种语法表示方法:
1、C语言风格
char 变量名 [] = “一串字符串”;
2、C++风格字符串
string 变量名 = “一串字符串”;
sizeof
作用:统计数据类型内存大小。
语法:sizeof ( 数据类型 或者 变量 )
例子:
sizeof( short )
sizeof( int )
sizeof( long )
sizeof( long long )
布尔类型
作用:代表真或者假
内存空间:只占1个字节
bool只有两个数值:
-
true/.真 (实际上是1)
-
flase/假 (实际上是0)
注意事项:只要是非 0 的数值,都代表1
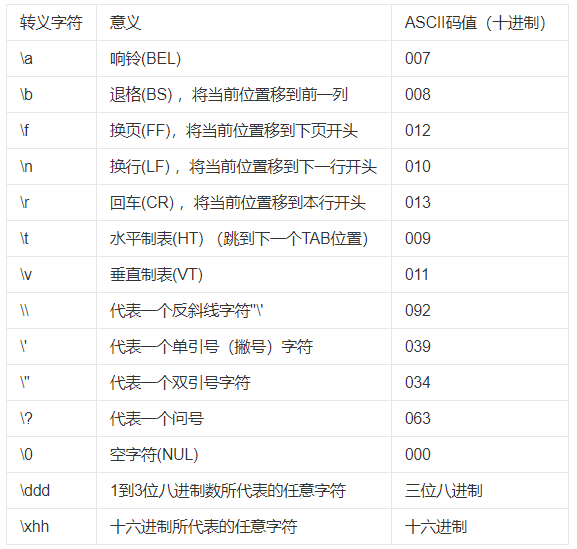
转义字符
作用:用于显示一些不能正常显示的字符
现阶段最常用的转义字符有:\n \\ \t
所有的转义字符和对应的意义:
数据的输入
作用:用于从键盘获取数据
关键字:cin
cin >> 变量
例子:
//1、整型
int a = 0;
cout << "请给整型变量a赋值:"<<endl;
cin >> a;
cout << "整型变量a = "<< a << endl;
//2、实型(浮点型)
float f = 3.14f;
cout << "请给浮点型变量f赋值:"<<endl;
cin >> f;
cout << "浮点型变量f = "<< f << endl;
//3、字符型
int ch = 'a';
cout << "请给字符型变量ch赋值:"<<endl;
cin >> ch;
cout << "字符型变量ch = "<< ch << endl;
//4、字符串型
#include<string> //记得加上字符串头文件
string str = "hello";
cout << "请给字符串str赋值:"<<endl;
cin >> str;
cout << "字符串str = "<< str << endl;
//5、布尔型
bool flag = flase;
cout << "请给布尔型flag赋值:"<<endl;
cin >> flag;
cout << "布尔型flag = "<< flag << endl;
运算符
算术运算符
作用:用于处理四则运算
算术运算符包括以下符号:
|
运算符 |
术语 |
示例 |
结果 |
|---|---|---|---|
|
+ |
加 |
10 + 5 |
15 |
|
- |
减 |
10 - 5 |
5 |
|
* |
乘 |
10 * 5 |
50 |
|
/ |
除 |
10 / 5 |
2 |
|
% |
取模(取余) |
10 % 3 |
1 |
|
++ |
前置递增(先加再用) |
a=2;b=++a; |
a=3;b=3; |
|
++ |
后置增值(先用再加) |
a=2;b=a++; |
a=3;b=2; |
|
-- |
前置递减(先减再用) |
a=2;b=--a; |
a=1;b=1; |
|
-- |
后置递减(先用再减) |
a=2;b=a--; |
a=1;b=2; |
赋值运算符
作用:用于表达式中给变量赋值
赋值运算符包括以下几个字符:
|
运算符 |
术语 |
示例 |
结果 |
|---|---|---|---|
|
= |
赋值 |
a=2;b=3; |
a=2;b=3; |
|
+= |
加等于 |
a=0;a+=2; |
a=2; |
|
-= |
减等于 |
a=5;a=3; |
a=2; |
|
*= |
乘等于 |
a=2;a*=2; |
a=4; |
|
/= |
除等于 |
a=4;a/=2; |
a=2; |
|
%= |
模等于 |
a=3;a%2; |
a=1; |
比较运算符
作用:用于表达式的比较,并返回一个真值或者假值。
比较运算符有以下符号:
|
运算符 |
术语 |
示例 |
结果(0:假,1:真) |
|---|---|---|---|
|
== |
相等于 |
4==3 |
0 |
|
!= |
不等于 |
4!=3 |
1 |
|
< |
小于 |
4<3 |
0 |
|
> |
大于 |
4>3 |
1 |
|
<= |
小于等于 |
4<=3 |
0 |
|
>= |
大于等于 |
4>=3 |
1 |
逻辑运算符
作用:用于根据表达式的值返回真值或者假值。
逻辑运算符有以下符号:
|
运算符 |
术语 |
示例 |
结果 |
|---|---|---|---|
|
&& |
与 |
a && b |
如果a和b都为真,则结果为真;否则为假 |
|
|| |
或 |
a || b |
如果a和b有一个为真,则结果为真;二者为假,结果为假。 |
|
! |
非 |
!a |
a为假,结果为真;a为真,结果为假; |
程序流程结构
C++支持的最基本的三种程序运行结构:
-
顺序结构:程序按顺序执行,不发生跳转;
-
选择结构:判断条件是否满足,有选择性的执行相应的程序;
-
循环结构:判断条件是否满足,循环多次执行某一段程序;
程序流程结构——顺序结构
这没啥好说的,程序从上往下顺序执行。
程序流程结构——选择结构
if语句
作用:执行满足条件的语句
if语句的三种形式:
-
单行格式if结构:if
-
多行格式if结构:if - else
-
多条件的if结构:if - else if - else
-
嵌套if结构:if { if { if } }
1、单行格式的if语句:if
语法:
if(关系表达式/条件)
{
满足条件后执行的语句体;
}2、多行格式的if语句:if - else
语法:
if(关系表达式/条件)
{
满足条件后执行的语句体;
}
else
{
不满足条件执行的语句体;
}3、多条件的if结构:if - else if - else
语法:
4、嵌套if语句:if { if { if } }
这是从前三种结构中延生出来的,在if语句中,可以嵌套其他的if语句
语法:
switch语句
作用:执行多条见分支语句;
语法1:判断结果是整型或者字符型
switch(关系表达式)
{
case 结果1:执行语句;
break;
case 结果2:执行语句;
break;
···
defaylt:执行语句;
break;
}语法2:判断结果是一个区间
switch(关系表达式)
{
case:结果1 ... 结果2: 执行语句;
break;
case:结果1 ... 结果2: 执行语句;
break;
default:执行语句;
break;
}使用规范:
-
使用时在两个数之间加“...”,且“...”两边必须有空格
-
判断的表达式的值必须是整型
-
判断时包含区间两端的数值;
-
此语句不一定在所有编译器下有效
程序流程结构——循环结构
作用:只要循环条件为真,就可以执行循环语句
while语句
特点:先判断,在循环;
语法:
while(循环条件)
{
循环语句
}do-while语句
特点:先循环一次,再判断;
语法:
do
{
循环语句;
}
while(循环条件);for语句
特点:结构清晰,代码简洁
语法:
for(起始表达式; 条件表达式; 末尾循环体)
{
循环语句;
}
break
作用:用于跳出选择结构或者循环结构
使用规范:
-
出现在switch中,终止case并且跳出switch
-
出现在循环语句中,跳出当前循环体
-
出现在嵌套语句中,跳出最近的内层循环体
continue语句
作用:在循环语句中,跳过本次循环,接着下一次循环
goto语句
作用:无条件跳转语句。标记符存在的话,执行到goto语句会跳转到标记的位置;
语法:
goto 标记符;
标记符;使用规范:
-
goto语句只能在同一个函数内跳转
-
不能从一段复杂的执行状态中跳转到外面,比如不能从多重嵌套中跳转出去
为什么不建议使用goto语句:
-
goto可以被其他程序结构比如选择结构替代
-
goto降低可读性,goto太多,哪儿哪儿都是标记,跳来跳去,让人读程序容易混乱
数组
数组,就是一个集合,里面存放了很多相同类型的数据元素
特点:
-
数组是由连续的内存位置组成的
-
数组中每个元素都是相同类型的
示例: int a[100]
官方含义:在内存中连续申请400个字节,并且使用变量a间接访问这片内存
一维数组
三种定义方式:
-
数据类型 数组名[ 数组长度 ];
-
数据类型 数组名[ 数组长度 ] = { 值1,值2,值3 ····};
-
数据类型 数组名 [ ] = { 值1,值2,···· };
数组名的用途:
-
获取数组在内存中的首地址
-
可以统计整个数组所占内存空间
int arr[10] = {1,2,3,4,5,6,7,8,9,0};
1、获取数组在内存中的首地址
cout << "元素首地址:" << (int)arr << endl;
cout << "数组中第一个元素的地址:" << (int)&arr[0] << endl;
cout << "数组中第一个元素的地址:" << (int)&arr[1] << endl;
//2、可以统计整个数组在内存空间长度
cout << "获取数组内存空间长度:" << sizeof(arr) << endl;
cout << "每个元素所占的内存空间:" << sizeof(arr[n]) << endl;
cout << "数组的元素个数:" << sizeof(arr)/sizeof(arr[0]) << endl;二维数组
二维数组就是在一维数组的基础上多加了一个维度
四种定义方式:
-
数据类型 数组名[ 行数 ][ 列数 ];
-
数据类型 数组名[ 行数 ][ 列数 ] = { 值1,值2,值3,值4 };
-
数据类型 数组名[ 行数 ][ 列数 ] = { (值1,值2),(值3,值4) };
-
数据类型 数组名[ ][ 列数 ] = { 值1,值2,值3,值4 };
数组名的用途:
-
获取二维数组在内存中的首地址
-
获取整个二维数组所占内存空间
int arr[2][3] = {
(1,2,3),
(3,4,5)
};
// 1、获取二维数组在内存中的首地址
cout << "二维数组首地址" << arr << endl;
cout << "二维数组第一行地址" << arr[0] << endl;
cout << "二维数组第二行地址" << arr[1] << endl;
cout << "二维数组第一个元素地址" << &arr[0][0] << endl;
cout << "二维数组第二个元素地址" << &arr[0][1] << endl;
// 2、获取整个二维数组所占内存空间
cout << "二维数组大小:" << sizeof(arr) << endl;
cout << "二维数组一行大小:" << sizeof(arr[0]) << endl;
cout << "二维数组元素大小:" << sizeof(arr[0][0]) << endl;
cout << "二维数组行数:" << sizeof(arr)/sizeof(arr[0]) << endl;
cout << "二维数组列数:" << sizeof(arr[0])/sizeof(arr[0][0]) << endl;函数
函数,又叫接口或者API
作用:讲一段常用的代码封装起来,减少代码重复量
使用场景:通常是将一段复杂冗长的代码,封装成一个一个模块
函数的定义
定义:有5个步骤:
-
返回值类型
-
函数名
-
参数列表
-
函数体语句
-
return表达式
语法:
返回值类型 函数名 (参数列表)
{
函数体语句;
return;
}注意事项:函数的定义只能出现一次,不然会出现重复定义的错误。
函数名命名规则:(跟变量命名规则一样)
-
不能是关键字
-
只有由字母、数字、下划线组成
-
第一个字符不能是数字
-
区分大小写
函数的调用
作用:将定义好的函数拿出来使用
语法:
函数名 (参数);
值传递
-
所谓值传递,就是再函数调用的时候,将实参传入到形参
-
值传递的时候,形参不会影响实参
函数的常见样式
常见的样式有4种:
-
有参有返
-
有参无返
-
无参有返
-
无参无返
语法:
//1、有参有返
数据类型 函数名 (数据类型 变量)
{
函数体;
return x;
}
//2、有参无返
void 函数名(数据类型 变量)
{
函数体;
}
//3、无参有返
数据类型 函数名()
{
函数体;
return x;
}
//4、无参无返
void 函数名()
{
函数体;
}函数的声明
作用:告诉编译器有这个函数的名称,可以拿去调用
函数的声明可以多次,但是函数的定义只有一次。
函数的分文件编写
作用:如果所有的代码都写在一个文件种,会非常麻烦,分文件编写可以让代码结构更加清晰
分文件编写的4个步骤:
-
创建.h头文件
-
创建.cpp的源文件
-
在头文件种写函数声明
-
在源文件种写函数定义和主函数
指针
作用:通过指针间接访问内存
-
可以用指针变量保存地址信息
-
内存编号是从0开始记录的,一般用十六进制数字表示
指针的定义
语法:
数据类型 * 变量名
引用与解引用
引用:用指针记录地址信息
int a = 10;
int *p;
p = &a;
//用指针p保存变量a的地址信息解引用:找到指针指向的内存地址
指针前面加“ * ”代表解引用,代表找到指针指向的内存中的数据
*p = 1000; //找到了指针p指向的内存数据,并将其数据修改成1000
指针所占内存空间
在32位操作系统下,占用4个字节,与数据类型无关
在64位操作系统下,占用8个字节,与数据类型无关
空指针
定义:指针变量指向内存中编号位0的空间
作用:用来初始化指针变量
注意事项:
-
空指针指向的内存是不允许访问的
-
内存编号0~255之间的内存都是系统占用的,不允许访问
示例:
//这就是空指针,指向了NULL,用来给指针变量初始化用的,但是不允许访问
int *p = NULL;
*p = 1000; //错误,空指针不允许访问野指针
定义:指针变量指向非法的内存空间
一般都是访问那些还没有申请的地址,就是野指针
示例:
int *p = NULL; //这是空指针,是合法的
int *p = (int *)0x1100; //这是野指针,因为地址空间0x1100还没有申请。直接拿来用是非法的const修饰指针
const修饰的指针,一般有3种情况:
-
const修饰指针 —— 常量指针
-
const修饰常量 —— 指针常量
-
const既修饰指针,又修饰常量
1、const修饰指针 —— 常量指针
修饰的是指针,所以指针指向的地址中的数据不可变,指向的地址可以变
const int *p1 = &a;
p1 = &b; //正确,地址可变
*p1 = 100; //错误,数据不可变2、const修饰常量 —— 指针常量
修饰的是常量,所以指针指向的地址不可变,指向的地址中的数据可以变
int * const p2 = &a;
p2 = &b; //错误,地址不可变
*p2 = 100;//正确,数据可变3、const既修饰指针,又修饰常量
既修饰指针,又修饰地址,所以指针指向的地址不可变,地址中的数据也不可变
const int * const p3 = &a;
p3 = &b; //错误,地址不可变
*p3 = 100; //错误,数据不可变指针与数组
作用:用指针来访问数组中的元素
注意事项:指针的数据类型要与数组数据类型相同
示例:
int arr[] = {0,1,2,3,4,5,6,7,8,9};
int *p = arr; //指针指向数组首地址
P++; //指针向前移动4个字节,指向数组第二个元素指针与函数(值传递和地址传递)
作用:用指针做函数的参数,修改实参的值
-
值传递:值传递不会改变实参;
-
地址传递:地址传递会改变实参;
使用规范:尽量使用地址传递,可以减少代码量,因为:
值传递的原理就是将实参赋值一份给实参,如果实参内存很大,拿拷贝一份需要的内存也很大;
而地址传递,再怎么样指针也只是需要4个字节而已。
看示例吧,一看就懂了
1、值传递
void swap(int a,int b)
{
int temp = a;;
a = b;
b = temp;
}
int main()
{
int a = 10;
int b = 20;
swap(a,b);
}2、地址传递
void swap(int *p1,int *p2)
{
int temp = *p1;
*P1 = *p2;
*p2 = temp;
}
int main()
{
int a = 10;
int b = 20;
swap(&a,&b);
}结构体
作用:结构体是用户自定义的数据类型,允许用户存储不同的数据类型;
语法:
struct 结构体名 { 结构体成员列表 };
占用内存:结构体占用空间需要考虑到其中成员的字节对齐
创建结构体的三种方式:
-
struct 结构体名 变量名
-
struct 结构体名 变量名 = { 成员1,成员2 ··· };
-
定义结构体时顺便创建变量
示例:
//定义学生这个结构体
struct Student
{
//成员列表
string name;
int age;
int score;
}
int main()
{
//创建1、struct 结构体名 变量名
struct Student s1;
s1.name = "张三";
s1.age = 18;
s1.scoer = 100;
//创建2、struct 结构体名 变量名 = { 成员1,成员2 ··· };
struct Student s2 = {"张三",18,100};
}创建3、定义结构体时顺便创建变量
struct Student
{
//成员列表
string name;
int age;
int score;
}s3; //s3就是我们顺便创建的机构体变量
int main()
{
s3.name = "张三";
s3.age = 18;
s3.score = 100;
}结构体数组
作用:将自定义的数组放到结构体当中,方便维护
使用规范:通过“.”访问结构体中成员
语法:
struct 结构体名 数组名[元素个数] = { {},{},····{} }
示例:
struct stduent
{
string name;
int age;
int score;
}
int main()
{
struct student arr[3] =
{
{"张三",18,100},
{"李四",19,80},
{"王五",20,60}
};
}结构体指针
作用:可以用指针来访问结构体中的成员
使用规范:通过“->”访问结构体中成员
示例:
struct stduent
{
string name;
int age;
int score;
}
int main()
{
struct student s = {"张三",18,100};
struct student *p = &s;
p->name = "李四";
p->age = 20;
p->score = 80;
}结构体嵌套结构体
作用:结构体中可以包含有另一个结构体
比如老师辅导写的每一个学员,老师是一个结构体,其成员中学生也是一个结构体
struct student
{
string name; //学生名字
int age; //学生年龄
int score; //学生分数
}
struct teacher
{
int id; //老师教工编号
string name; //老师名字
struct student stu; //子结构体 学生
}
int main()
{
struct teacher t;
t.id = 1000;
t.name = "老王";
t.stu.name = "张三";
t.stu.score = 100;
}结构体做函数参数
作用:将结构体作为函数的参数传递
参数传递方式有两种:
-
值传递
-
地址传递
使用规范:尽量使用地址传递,可以减少代码量,因为:
值传递的原理就是将实参赋值一份给实参,如果实参内存很大,拿拷贝一份需要的内存也很大;
而地址传递,再怎么样指针也只是需要4个字节而已。
struct student
{
string name; //学生名字
int age; //学生年龄
int score; //学生分数
}
void temp1(struct student s) //值传递
{
//访问结构体用“.”
//形参不会改变实参
}
void temp2(struct student *p) //地址传递
{
//访问结构体用“->”
//形参可以改变实参
}
int main()
{
struct sutdent s;
s.name = "张三";
s.age = 18;
s.score = 100;
temp1(s); //值传递调用
temp2(&s); //地址传递调用
}const修饰结构体
作用:用来防止误操作
加了之后,结构体参数就只能读,一旦对结构体有了任何操作,就会产生错误。
示例:
void temp( const student *s) { }
联合体
语法:
union 联合体名{ 联合体成员 }
占用:联合体占用空间就是其中最大变量的占用空间;
特点:
-
同时只能使用一个成员
-
所有成员起始地址是一致的
-
可以作为函数参数
枚举类型
作用:就是一堆int类型数据的集合,它使得某一些值变量更加有意义,不是一个新的数据类型
特点:
-
它只是一个数据的集合,不是一个新的数据类型
-
如果没有赋值,数值默认从0开始,后续数值就是上一个数+1;
-
可以自定义赋值,后续数值就是上一个数+1;
语法:
enum 命名{ int型数据成员 }
示例1:
enum state
{
ok; // 没有赋值,默认为0
failed; // 没有赋值,默认上一个数+1,为1
error; // 没有赋值,默认上一个数+1,为2
}示例2:
enum state
{
ok = 10; // 主动赋值为10
failed = 20; // 主动赋值为20
error; // 没有赋值,默认为+1,即21
} 学习C++这一篇就够了(进阶篇)![]() https://mp.csdn.net/mp_blog/creation/editor/131565205
https://mp.csdn.net/mp_blog/creation/editor/131565205
学习C++这一篇就够了(提升篇)![]() https://mp.csdn.net/mp_blog/creation/editor/131566689
https://mp.csdn.net/mp_blog/creation/editor/131566689
就先写到这儿吧。
希望以上内容可以帮助到你们。
祝各位生活愉快。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号