hadoop实战–搭建eclipse开发环境及编写Hello World
原创文章,转载请注明: 转载自工学1号馆
欢迎关注我的个人博客:www.wuyudong.com, 更多云计算与大数据的精彩文章
1、在eclise中安装hadoop的插件并配置
在上篇文章《编译hadoop eclipse的插件(hadoop1.0)》,已经介绍过怎样编译基于hadoop1.0的eclipse插件
将jar包放在eclipse安装目录下的plugins文件夹下。然后启动eclipse
进入后,在菜单window->Rreferences下打开设置:
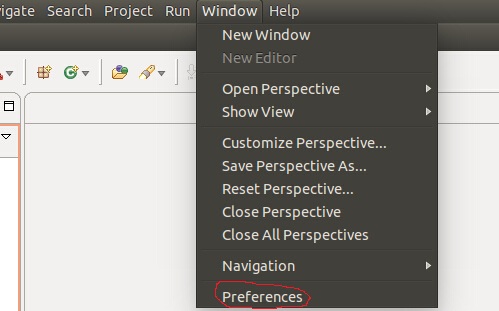
点击“Ant” 出现:

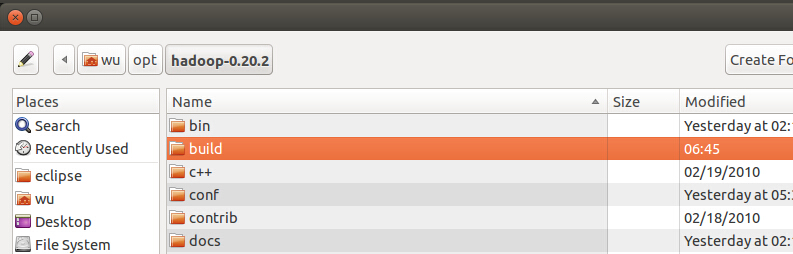
点击browse选择hadoop的源码下的build目录,然后点OK
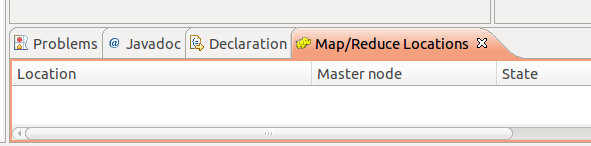
打开Window->Show View->Other 选择Map/Reduce Tools,单击Map/Reduce Locations,会打开一个View:

添加Hadoop Loacation,其中Host和Port的内容这里的host和port对应mapred-site.xml中mapred.job.tracker的值,UserName 是用户名,我配置的是localhost和9001
但是出现如下问题,eclipse的左侧看不到project explorer,更看不到其中的dfs
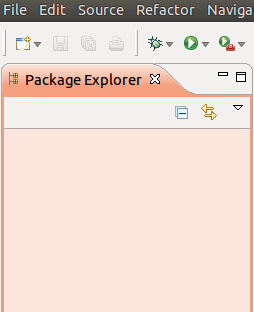
解决办法:
应该在菜单栏
选择:Window->Open pespective-><Map/Reduce>。然后就能看到HDFS文件系统已经所创建得一些项目。
添加Hadoop Loacation,其中Host和Port的内容跟据conf/hadoop-site.xml的配置填写,UserName 是用户名,如下图
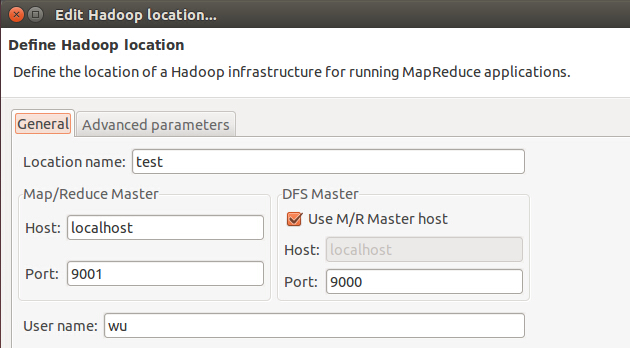
成功添加Hadoop Loacation后还可能出现如下错误:
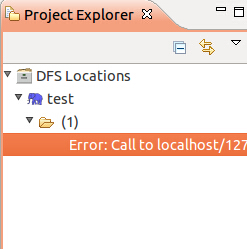
解决办法:
这时候,需要对namenode进行格式化:bin/hadoop namenode -format
执行命令:bin/start-all.sh
如果test下面的文件夹显示(1)而不是(2)也是正常的,如果要显示(2),运行《安装并运行hadoop》一文中最后的那几个命令。
在配置完后,在Project Explorer中就可以浏览到DFS中的文件,一级级展开,可以看到之前我们上传的in文件夹,以及当是存放的2个txt文件,同时看到一个在计算完后的out文件夹。
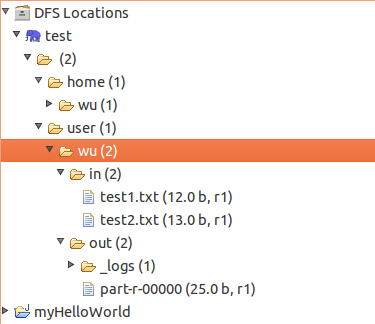
现在我们要准备自己写个Hadoop 程序了,所以我们要把这个out文件夹删除,有两种方式,一是可以在这树上,执行右健删除。 二是可以用命令行:
$ bin/hadoop fs -rmr out
用$bin/hadoop fs -ls 查看
2、编写HelloWorld
环境搭建好了,之前运行Hadoop时,直接用了examples中的示例程序跑了下,现在可以自己来写这个HelloWorld了。在eclipse菜单下 new Project 可以看到,里面增加了Map/Reduce选项:

选中,点下一步:
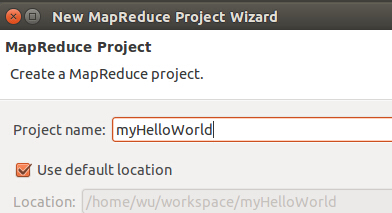
输入项目名称后,继续(next), 再点Finish
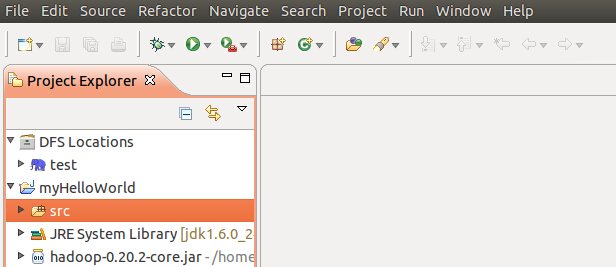
然后在Project Explorer中就可以看到该项目了,展开,src发现里面啥也没有,于是右健菜单,新建类(new->new class):
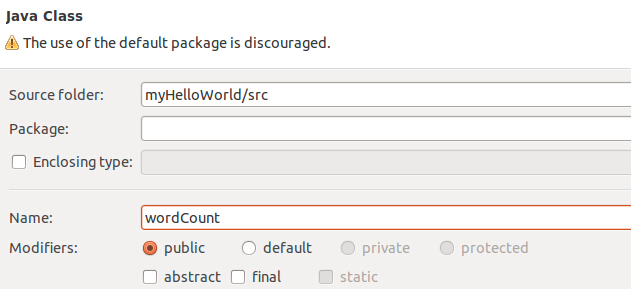
然后点击Finish,就可以看到创建了一个java类了:
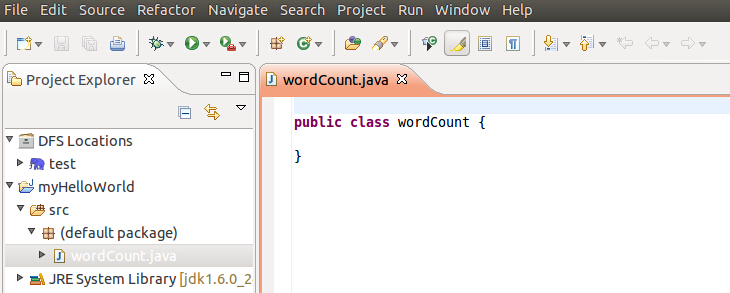
然后在这个类中填入下面代码:
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setJarByClass(wordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
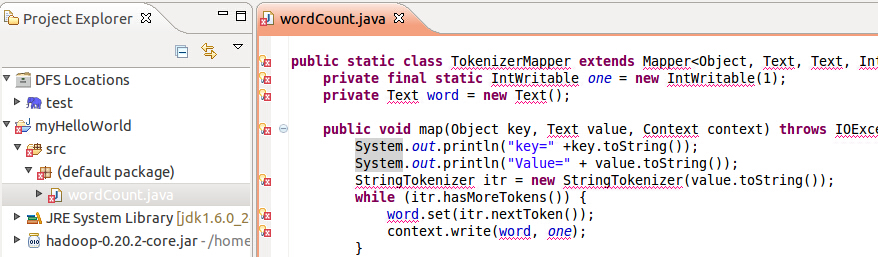
填入代码后,会看到一些错误,没关系,点击边上的红叉,然后选择里面的import即可:
import java.io.IOException; import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.GenericOptionsParser;
这里,如果直接用源码来操作,可能会GenericOptionsParser这个类找不到定义,还是红叉,添加commons-cli-1.2.jar这个jar包,在build/ivy/lib/Hadoop/Common下,右健Project Explorer中的MyHelloWorld工程,选择Build Path->Config Build Path
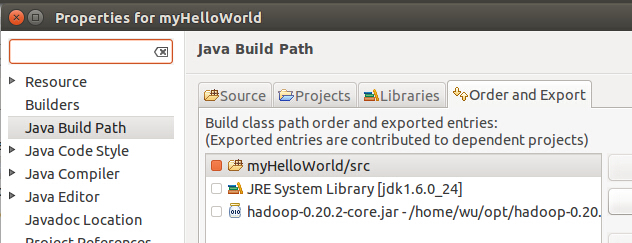
在Liberaries Tab页下,点击Add External JARs 在弹出窗口中,跟据前面说的目录,找到这个jar包,点确定后,回到工程,可以看到红叉消失,说明编译都通过了。
在确保整个工程没有错误后,点击上面的小绿箭头,然后在弹出的小窗口上,选择Run On Hadoop:
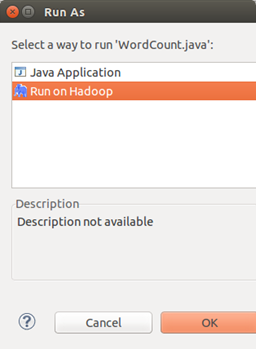
点OK后,会弹出小窗口:
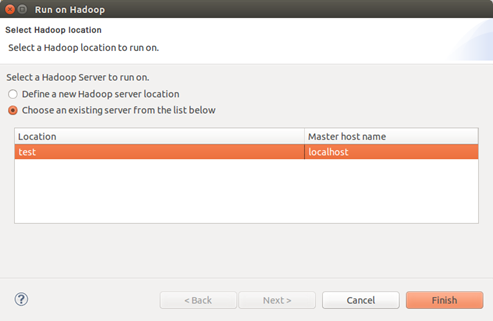
然手中选择Choose an existing server from the list below。然后找到之前配置的地址项,选中后,点Finish,然后系统不会Run起来,在控制台(双击可最大化)中可以看到运行结果:

运行完后,可以看到多了一个out文件夹,双击打开out文件可以看到单词的统计结果来
3、可能出现的问题:
问题1:
运行后,如果Console里只输出Usage :wordcount<in> <out>,

则需要修改下参数,在运行菜单边上小箭头,下拉,点击Run Configuration,:
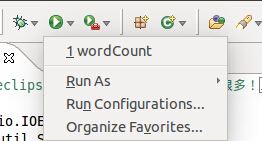
左边选中 JavaApplication中的 WordCount,右边,在Arguments中输入 in out。然后再点Run 就可以看到结果了。

左边选中 JavaApplication中的 WordCount,右边,在Arguments中输入 in out。然后再点Run 就可以看到结果了。
问题2:
第二次运行会报错,仔细看提示,可以看到报错的是out目录已经存在,所以需要手动来删除一下。
更进一步
上面我们写了一个MapReduce的HelloWorld程序,现在,我们就也学一学HDFS程序的编写。HDFS是什么,它是一个分布式文件存储系统。一般常用操作有哪些? 当然我们可以从编程角度来:创建、读、写一个文件,列出文件夹中的文件及文件夹列表,删除文件夹,删除目录,移动文件或文件夹,重命名文件或文件夹。
启动eclipse,新建Hadoop项目,名称MyHDFSTest,新建类HDFSTest,点击确定,然后同样工程属性Configure BuildPath中把 build/ivy/lib/Hadoop下的所有jar包都引用进来(不详细说明了,可参考上面的步骤)
在类中,添加main函数:
public static void main(String[] args) {
}
或者也可以在添加类时,勾选上创建main,则会自动添加上。
在mian函数中添加以下内容:
try {
Configuration conf = new Configuration();
conf.set("fs.default.name", "hdfs://localhost:9000");
FileSystem hdfs = FileSystem.get(conf);
Path path = new Path("in/test3.txt");
FSDataOutputStream outputStream = hdfs.create(path);
byte[] buffer = "Hello".getBytes();
outputStream.write(buffer, 0, buffer.length);
outputStream.flush();
outputStream.close();
System.out.println("Create OK");
} catch (IOException e) {
e.printStackTrace();
}
直接添加进来会报错,然后需要添加一些引用才行:
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FSDataOutputStream; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path;
在没有错误后,点击工具条上的运行, 但这次跟前次不一样,选择Run as Java Application。然后,就可以在输出框中看到Create OK的字样了,表明程序运行成功。
这段代码的意思是在in文件夹下,创建test3.txt,里面的内容是”Hello”。 在运行完后,我们可以到eclipse的Project Explorer中查看是否有这文件以及内容。同样也可以用命令行查看$bin/hadoop fs -ls in。
ok,第一个操作HDFS的程序跑起来了,那其它功能只要套上相应的处理类就可以了。为了方便查找操作,我们列举了张表:
| 操作说明 | 操作本地文件 | 操作DFS文件 |
| 主要命名空间 | java.io.File
java.io.FileInputStream java.io.FileOutputStream |
org.apache.hadoop.conf.Configuration
org.apache.hadoop.fs.FileSystem org.apache.hadoop.fs.Path org.apache.hadoop.fs.FSDataInputStream; org.apache.hadoop.fs.FSDataOutputStream |
| 初使化对象 | new File(路径); | Configuration
FileSystem hdfs |
| 创建文件 | File.createNewFile(); | FSDataOutputStream = hdfs.create(path)
FSDataOutputStream.write( buffer, 0, buffer.length); |
| 创建文件夹 | File.mkdir() | hdfs.mkdirs(Path); |
| 读文件 | new FileInputStream();
FileInputStream.read(buffer) |
FSDataInputStream = hdfs.open(path);
FSDataInputStream.read(buffer); |
| 写文件 | FileOutputStream.write(
buffer, 0, buffer.length); |
FSDataOutputStream = hdfs.append(path)
FSDataOutputStream.write( buffer, 0, buffer.length); |
| 删除文件(夹) | File.delete() | FileSystem.delete(Path) |
| 列出文件夹内容 | File.list(); | FileSystem.listStatus() |
| 重命令文件(夹) | File.renameTo(File) | FileSystem.rename(Path, Path) |
有了这张表,以后在需要的时候就可以方便查询了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号