
spark之依赖关系
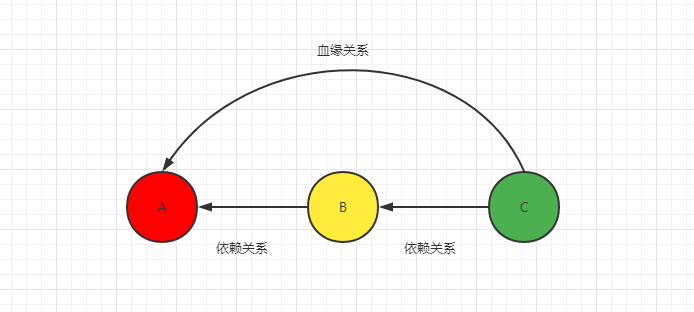
spark的每个RDD都会记录从创建到当前算子的依赖(血缘关系),当该RDD的部分分区数据丢失时,它可以根据这些信息来重新运算和恢复丢失的数据分区 --- toDebugString 方法查看
OneToOneDependency窄依赖,上游的RDD的一个分区被下游的RDD的一个分区所独享(独生子女)
ShuffleDependency宽依赖,上游的RDD的一个分区被下游RDD的多个分区所共享(多生子女)

spark的每个RDD都会记录从创建到当前算子的依赖(血缘关系),当该RDD的部分分区数据丢失时,它可以根据这些信息来重新运算和恢复丢失的数据分区 --- toDebugString 方法查看
OneToOneDependency窄依赖,上游的RDD的一个分区被下游的RDD的一个分区所独享(独生子女)
ShuffleDependency宽依赖,上游的RDD的一个分区被下游RDD的多个分区所共享(多生子女)

