
BookKeeper 介绍(1)--简介
BookKeeper 是一个可扩展、可容错和低延迟的存储服务;本文主要介绍其基本概念及特性。
1、基本概念
在 BookKeeper 中:
- 日志的单元是 entry (又名 record)
- 日志 entries 流称为 ledgers
- 存储 ledgers 的独立服务器称为 bookies
BookKeeper 被设计为可靠且能够抵御各种故障。bookies 可能会崩溃、损坏数据或丢弃数据,但只要在整个集合中有足够数量的 bookies 正常工作,服务将能够正常运行。
1.1、Entries
Entries 包含写入 ledgers 的数据数据,以及一些重要的元数据。Entries 是写入 ledgers 的字节序列,每个 entry 有如下字段:
| 字段 | Java 类型 | 说明 |
| Ledger number | long | Ledger ID |
| Entry number | long | Entry ID |
| Last confirmed (LC) | long | 最后提交的 Entry ID |
| Data | byte[] | entry 的数据 |
| Authentication code | byte[] | 消息认证码,包含 entry 中的所有其他字段 |
1.2、Leaders
Ledgers 是 BookKeeper 中的基本存储单元。Ledgers 是一系列 entries 的序列,每个 entry 是一系列字节。entries 按以下方式写入 ledges:
- 顺序写入
- 最多写入一次
这意味着 ledger 具有仅追加的语义。一旦条目被写入ledger,就不能修改。确定正确的写入顺序是客户端应用程序的责任。
1.3、Bookies
Bookies 是处理 ledger(更具体地说是 ledger 的片段)的单个 BookKeeper 服务器。Bookies 作为集合的一部分运行。一个 bookie 是一个独立的 BookKeeper 存储服务器。独立的 bookies 存储 ledger 的片段,而不是整个ledger(出于性能考虑)。对于给定的 ledger L,一个集合是存储 L 中 entries 的 bookies 组。每当 entries 被写入 ledger 时,这些 entries 会被分布式地存储在集群中的 bookies 的子组中,而不是存储在所有的 bookies 上。
1.4、元数据存储
BookKeeper 元数据维护着 BookKeeper 集群的所有元数据,包括 ledger 元数据、可用的 bookie 等等。目前,BookKeeper 使用 ZooKeeper 进行元数据存储。
1.5、bookies 中的数据管理
Bookies 以一种日志结构的方式管理数据,通过三种类型的文件来实现:journals、entry logs、index files。
1.5.1、Journals
一个 journal 文件包含了 BookKeeper 的事务日志。在对 ledger 进行任何更新之前,bookie 确保将描述该更新的事务写入到非易失性存储中。一旦 bookie 启动或者旧的 journal 文件达到文件大小阈值,就会创建一个新的 journal 文件。
1.5.2、Entry logs
一个 entry 日志文件管理来自 BookKeeper 客户端的已写入条目。来自不同 ledgers 的 entries 被聚合并按顺序写入,而它们的偏移量被保存在 ledger 缓存中作为指针,以便进行快速查找。
一旦 bookie 启动或者旧的 entry 日志文件达到文件大小阈值,就会创建一个新的 entry 日志文件。一旦旧的 entry 日志文件与任何活跃的 ledger 都没有关联,垃圾收集线程就会删除它们。
1.5.3、Index files
为每个 ledger 创建一个索引文件,它包括一个头部和若干固定长度的索引页,记录了存储在 entry 日志文件中的数据的偏移量。
由于更新索引文件会引入随机磁盘 I/O,索引文件通过后台运行的同步线程进行延迟更新。这确保了更新的快速性能。在索引页被持久化到磁盘之前,它们会被放到 ledger 缓存以便查找。
1.5.4、Ledger cache
Ledger 索引页被缓存在内存池中,这使得磁盘头调度的管理更加高效。
1.5.5、Adding entries
当客户端需要将一个 entry 写入 ledger 时,entry 需经过如下几个步骤才能持久化到磁盘上:
- entry 被追加到 entry 日志中
- entry 的索引在 ledger 缓存中被更新
- 与此 entry 更新对应的事务被追加到 journal 中
- 响应被发送给 BookKeeper 客户端
出于性能考虑,entry 日志在内存中缓冲 entry 并批量提交它们,而 ledger 缓存则在内存中保存索引页并延迟刷新它们。
1.5.6、Data flush
Ledger 索引页在以下两种情况下会刷新到索引文件中:
- 当达到 ledger 缓存的内存限制时。没有更多空间可用来保存新的索引页。脏索引页将被从 ledger 缓存中驱逐,并持久化到索引文件中。
- 后台线程负责定期从 ledger 缓存中将索引页刷新到索引文件中。
除了刷新索引页之外,同步线程还负责在 journal 文件使用过多磁盘空间的情况下滚动 journal 文件。同步线程中的数据刷新流程如下:
- 1、在内存中记录 LastLogMark。LastLogMark 表示其之前的所有 entries 都已被持久化(包括索引和 entry 日志文件),包含两个部分:
txnLogId(journal 文件ID)
txnLogPos(journal 文件中的偏移量)
- 2、从 ledger 缓存中刷新脏索引页到索引文件,并刷新 entry 日志文件以确保所有缓存的 entries 都已持久化到磁盘。
理想情况下,一个 bookie 只需要刷新包含在 LastLogMark 之前的索引页和 entry 日志文件。但是,在与 journal 文件对应的 ledger 和 entry 日志中没有这样的信息。因此,线程在这里完全刷新了 ledger 缓存和 entry 日志,可能会刷新 LastLogMark 之后的 entry。尽管刷新更多 entry 不是问题,但是多余的。
- 3、LastLogMark 被持久化到磁盘,这意味着在 LastLogMark 之前添加的 entry 数据和索引页也已被持久化到磁盘。现在是安全地删除早于 txnLogId 的 journal 文件的时候了。
如果在将 LastLogMark 持久化到磁盘之前,bookie 崩溃了,journal 文件仍然包含可能尚未持久的 entries。因此,当 bookie 重新启动时,它会检查 journal 文件以恢复这些 entries,数据不会丢失。
使用上述数据刷新机制,当 bookie 关闭时,同步线程跳过数据刷新是安全的。然而,在 entry 记录器中,它使用一个缓存通道来批量写入 entries,而在关闭时缓存通道中可能有数据。bookie 需要确保在关闭时刷新缓存通道中的 entry 数据。否则,entry 日志文件将因缺少部分 entries 而损坏。
1.5.7、Data compaction
在 bookies 中,不同 ledgers 的 entries 被交错存储在 entry 日志文件中。每个 bookie 运行一个垃圾收集器线程来删除未关联的 entry 日志文件,以回收磁盘空间。如果某个 entry 日志文件包含尚未删除的 ledger 的 entries,则该 entry 日志文件将永远不会被移除,占用的磁盘空间也永远无法回收。为了避免这种情况,bookie 服务器在垃圾收集器线程中压缩 entry 日志文件,以回收磁盘空间。
有两种不同频率运行的压缩:次要压缩和主要压缩。次要压缩和主要压缩之间的区别在于它们的阈值和压缩间隔。
- 垃圾收集阈值是未删除的 ledgers 占据的 entry 日志文件大小的百分比。默认的次要压缩阈值为 0.2,而主要压缩阈值为 0.8。
- 垃圾收集间隔是运行压缩的频率。默认的次要压缩间隔为 1 小时,而主要压缩间隔为 1 天。
如果阈值或间隔设置为小于或等于零,压缩将被禁用。
垃圾收集器线程中的数据压缩流程如下:
- 该线程扫描 entry 日志文件以获取 entry 元数据,其中记录了包含 entry 数据的 ledgers 列表。
- 在正常的垃圾收集流程中,一旦 bookie 确定某个 ledger 被删除,该 ledger 将从 entry 元数据中删除,同时 entry 日志的大小将减少。
- 如果 entry 日志文件的剩余大小达到指定的阈值,entry 日志文件中活跃的 ledgers 的 entries 将被复制到一个新的 entry 日志文件中。
- 一旦所有有效 entries 都已复制,旧的 entry 日志文件将被删除。
1.5.8、ZooKeeper metadata
BookKeeper 需要安装 ZooKeeper 来存储 ledger 元数据。构建 BookKeeper 客户端对象时,需要将 ZooKeeper 服务器列表作为参数传递给构造函数,如下所示:
String zkConnectionString = "127.0.0.1:2181"; BookKeeper bkClient = new BookKeeper(zkConnectionString);
1.5.9、Ledger manager
ledger 管理器处理 ledger 的元数据(存储在 ZooKeeper 中)。BookKeeper 提供了两种类型的 ledger 管理器:flat ledger manager 和 hierarchical ledger manager。这两种 ledger 管理器都扩展了 AbstractZkLedgerManager 抽象类。
A、Hierarchical ledger manager
默认的 ledger 管理器。Hierarchical ledger manager 能够管理大量的 BookKeeper 账本(> 50,000)。
在 HierarchicalLedgerManager 类中实现了 hierarchical ledger manager,首先使用 EPHEMERAL_SEQUENTIAL znode 从 ZooKeeper 获取全局唯一标识符。由于 ZooKeeper 的序列计数器采用 %10d(10位数字,用 0 填充,例如 <path>0000000001)的格式,hierarchical ledger manager 将生成的 ID 分为 3 部分:
{level1 (2 digits)}{level2 (4 digits)}{level3 (4 digits)}
这三个部分被用来构成实际的 ledger 节点路径,以存储 ledger 元数据:
{ledgers_root_path}/{level1}/{level2}/L{level3}
例如,ledger 0000000001 被分为三个部分,分别是 00、0000 和 00001,然后存储在 znode "/{ledgers_root_path}/00/0000/L0001" 中。每个 znode 可以包含多达 10,000 个 ledger,这避免了子列表大于最大 ZooKeeper 数据包大小的问题(正是这个限制促使创建 Hierarchical ledger manager)。
B、Flat ledger manager
自 4.7.0 版本起已被弃用,现在不建议使用。
在 FlatLedgerManager 类中实现了 Flat ledger manager,它将所有 ledger 的元数据存储在单个 ZooKeeper 路径的子节点中。Flat ledger manager 创建顺序节点以确保 ledger ID 的唯一性,并将所有节点前缀设置为 L。Bookie 服务器在哈希映射中管理其自己的活动 ledgers,以便轻松查找已从 ZooKeeper 中删除的 ledgers,然后对其进行垃圾回收。
2、Bookkeeper 特性
2.1、节点对等架构
创建 ledger 时有 3 个控制数据写入方式的参数:ensSize 选择几个节点存储这个 ledger,writeQuorumSize 控制数据写几个副本(并发写,不同于 Kafka 或 HDFS,BookKeeper 数据节点之间没有主从关系,数据同步从服务端移到了客户端),ackQuorumSize 表示几个副本 ack 就表示写入成功。
以下图为例,createLedger(5,3,2),在保存 ledger 时,选择了 5 个节点,但是只写 3 个副本,2 个副本 ack 就表示写入成功。第一个参数一般可用于调整并发度,因为写 3 个副本是通过轮转的方式写入,例如第 1 个 entry 是写 1-3 节点,第 2 个 entry 写 2-4 节点,第 3 个 entry 写 3-5 节点,第 4 个 entry 写 4-5 和 1 节点这样轮转。这种方式即便 3 个副本,也可以把 5 个节点都用起来。
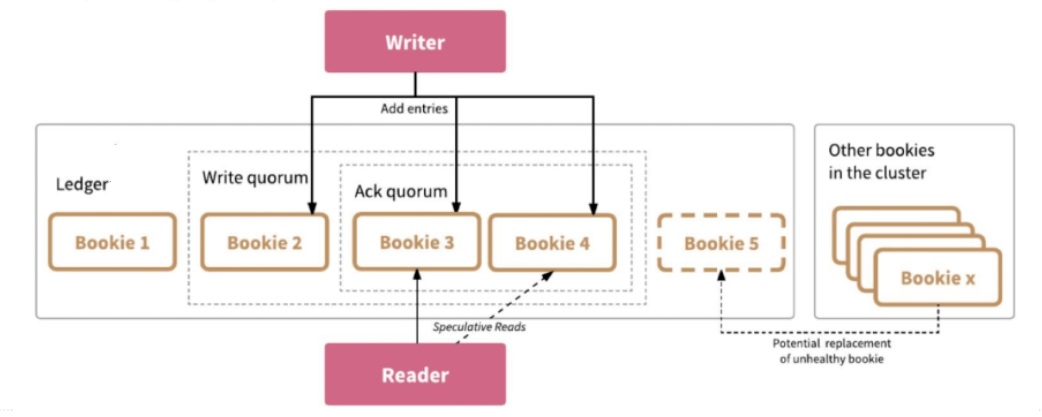
这几个参数可让用户通过机架感知、机房感知等各种方式进行灵活设置。当选好节点后节点之间的排序就已完成,每个 entry 会带个 index,index 和节点已有绑定关系,例如 index 为1 的,都放在 123上,为 2 的都放在 234 上。通过这种方式可以让我们知道每个节点存了哪些消息,当某个节点宕机,根据这个节点的位置信息,把对应 entry 还在哪些节点上有副本的信息找出来进行多对多的恢复。这么做的另一个好处是不用再维护元数据信息,只需要有每个节点 entry index 信息,在 createLedger 时记录好每个节点的顺序即可。
createLedger(5,3,2)数据存储结构是下图中右边的结构,如果选择 ensSize=3,writeQuorumSize=3,数据存储结构就是下图中左边的结构:
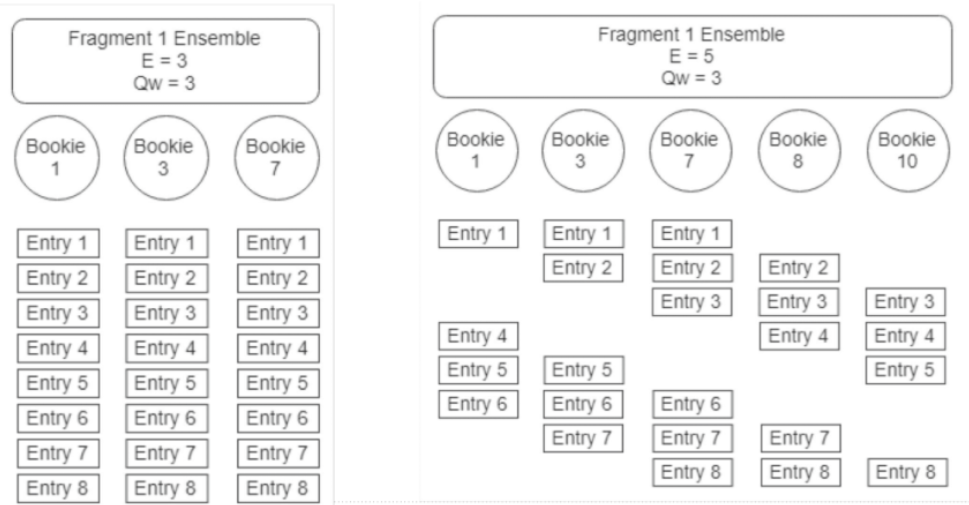
综上,可以通过 ensSize 来调整读写带宽,通过 writeQuorumSize 调整强一致性的控制,通过 ackQuorumSize 权衡在有较多副本时也可以有较低的时延(但一致性就可能有一定的损失)。
2.2、可用性
A、读可用性
读的访问是对等的,任意一个节点返回就算读成功。这个特性可以把延迟固定在一个阈值内,当遇到网络抖动或坏节点,通过延迟参数避障。例如读的延迟时间为 2ms,读节点 3 时超过 2ms,就会并发地读节点 4,任意一个节点返回就算读成功,如上面图 1 中 Reader 部分。
B、写可用性
在 createLedger 时会记录每个节点的顺序,假如写到 5 节点宕机,会做一次元数据的变更,从这个时间开始,先进行数据恢复,同时新的 index 中会把 5 节点变为 6 节点,如上面图 1 中 x 节点替换 5 节点。
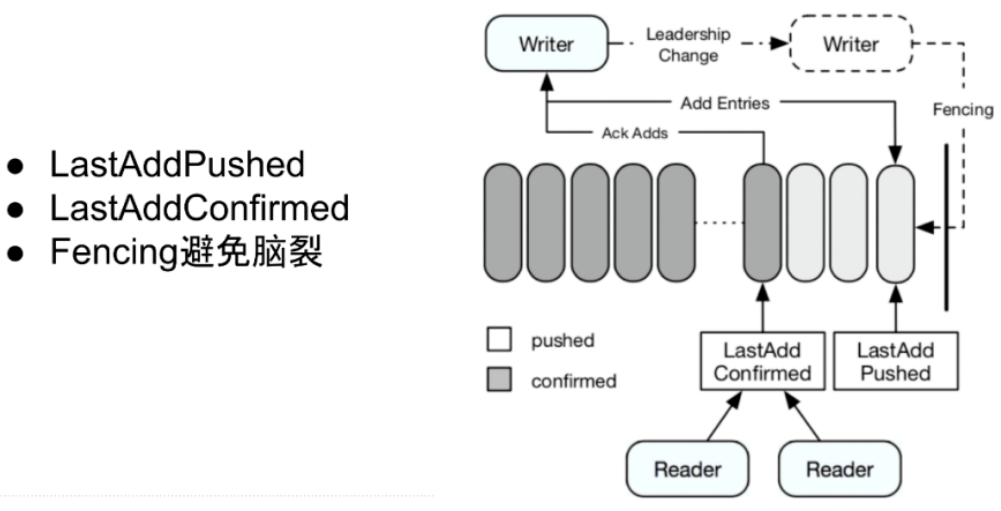
2.3、一致性
BookKeeper 底层节点对等设计让写入数据的 Writer 成为了协调者,Writer 来保存数据是否存储成功的状态,例如节点是否出现问题、副本够不够、在写入过程中出现宕机时通过 fencing 的方式防止脑裂等。所以,Writer 维护了 2 个 index:LastAddPushed 和 LastAddConfirmed。
LastAddPushed 记录最后写入的 entry;LastAddConfirmed 记录最后连续成功写入的 entry,需要确保 LastAddConfirmed 之前的 entry 都已写入成功,例如有 id 为 1、2 、3 的 entry,1 和 3 的 entry 先返回成功了,2 的 entry 还未返回,按连续的规则 LastAddConfirmed 是 1 而不是 3。
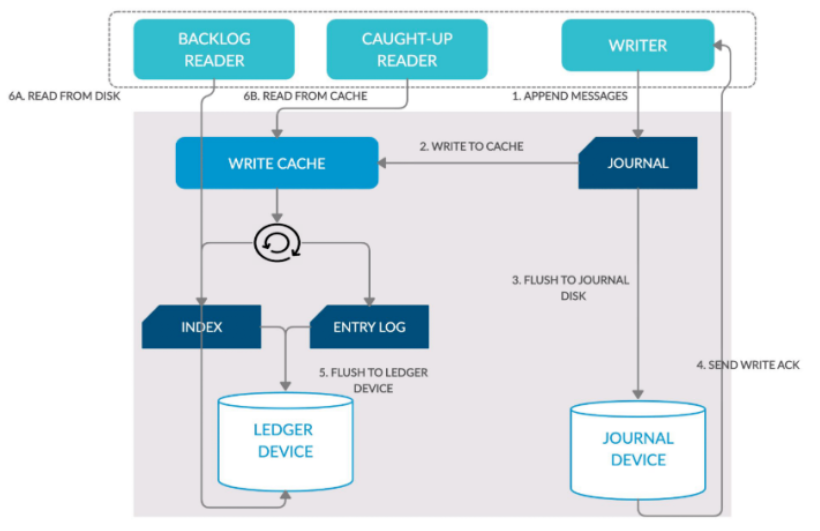
2.4、读写分离
下图是每个数据节点的数据流转过程,数据写入时,Writer 通过 append only 方式写入到 Journal,Journal 在把数据写到内存的同时会按一定频率(默认 1ms 或 500 byte)把数据持久化到 Journal Device 里,写完后会告诉 Writer 这个节点写入成功了(持久化到磁盘是默认配置)。
读的时候,如果读最新的数据,可以直接从内存中返回,如果读历史数据,也只去读数据盘,不会对 Journal Device 写入有影响。这样针对有读瓶颈或写瓶颈的用户,可以把 Journal Disk 或 Ledger Disk换成 SSD 盘,提升性能,并且防止读写的互相干扰。
参考:
https://bookkeeper.apache.org/docs/overview/
https://cloud.tencent.com/developer/article/2054521

