
Elasticsearch 入门实战(1)--简介
Elasticsearch 是一个分布式、RESTful 风格的搜索和数据分析引擎;本文主要介绍其基本概念。
1、概述
1.1、Elasticsearch 是什么
Elasticsearch 是一个分布式、高扩展、高实时的搜索与数据分析引擎。它能很方便的使大量数据具有搜索、分析和探索的能力。充分利用 Elasticsearch 的水平伸缩性,能使数据在生产环境变得更有价值。Elasticsearch 的实现原理主要分为以下几个步骤,首先用户将数据提交到 Elasticsearch 数据库中,再通过分词控制器去将对应的语句分词,将其权重和分词结果一并存入数据,当用户搜索数据时候,再根据权重将结果排名,打分,再将返回结果呈现给用户。
Elasticsearch 可以用于搜索各种文档。它提供可扩展的搜索,具有接近实时的搜索,并支持多租户。Elasticsearch 是分布式的,这意味着索引可以被分成分片,每个分片可以有 0 个或多个副本。每个节点托管一个或多个分片,并充当协调器将操作委托给正确的分片。再平衡和路由是自动完成的。相关数据通常存储在同一个索引中,该索引由一个或多个主分片和零个或多个复制分片组成。一旦创建了索引,就不能更改主分片的数量。
1.2、Elasticsearch 索引是什么
Elasticsearch 索引指相互关联的文档集合。Elasticsearch 会以 JSON 文档的形式存储数据。每个文档都会在一组键(字段或属性的名称)和它们对应的值(字符串、数字、布尔值、日期、数值组、地理位置或其他类型的数据)之间建立联系。
Elasticsearch 使用的是一种名为倒排索引的数据结构,这一结构的设计可以允许十分快速地进行全文本搜索。倒排索引会列出在所有文档中出现的每个特有词汇,并且可以找到包含每个词汇的全部文档。
在索引过程中,Elasticsearch 会存储文档并构建倒排索引,这样用户便可以近实时地对文档数据进行搜索。索引过程是在索引 API 中启动的,通过此 API 您既可向特定索引中添加 JSON 文档,也可更改特定索引中的 JSON 文档。
1.3、Elasticsearch 用途
Elasticsearch 在速度和可扩展性方面都表现出色,而且还能够索引多种类型的内容,这意味着其可用于多种用例:
- 应用程序搜索
- 网站搜索
- 企业搜索
- 日志处理和分析
- 基础设施指标和容器监测
- 应用程序性能监测
- 地理空间数据分析和可视化
- 安全分析
- 业务分析
2、Elasticsearch 相关概念
2.1、Index(索引)
索引是具有相似结构的文档的集合, 等同于 Solr 中的集合;每个索引有唯一的名称, 名称小写。索引类似 MySQL 中 database 概念。
2.2、Document(文档)
文档是存储在 ES 中的 JSON 格式的字符串, 由 field(字段) 构成。
2.3、Field(字段)
字段可以是一个简单的值(如字符串、数字、日期), 也可以是一个数组, 还可以嵌套一个对象或多个对象。字段类似于关系数据库中表数据的列, 每个字段都对应一个类型. 可以指定如何分析某一字段的值, 即对 field 指定分词器。
2.4、Type(类型)
type 是 index 的逻辑分类, 在 ES 6.x 版本之前, 每个索引中可以定义一个或多个 type, 而在 6.X 版本之后, 一个 index 中只能定义一个 type。通常,会为具有一组共同字段的文档定义一个 type。
2.5、Mapping(映射)
mapping 是对字段的定义说明,如某个字段的数据类型、默认值、分析器、是否被索引等等;类似于 Solr 中 schema.xml 约束文件的作用。
2.6、Node(节点)
2.7、Cluster(集群)
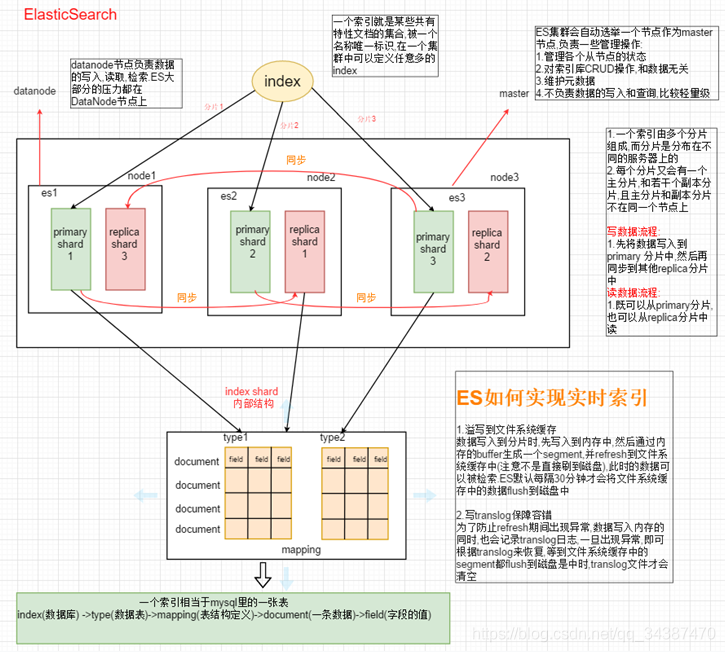
cluster 是一个或多个 node 的集合,cluster 为整个数据提供跨所有节点的集合索引和搜索功能。2.8、Shard(分片)
单个 node 无法存储大量的索引数据, ES 可以把一个索引分成多个分片, 分布到不同的 node 上, 从而构成分布式索引。每个分片都是一个 Lucene 实例, 也就是说每个分片底层都有一个单独的 Lucene 提供独立的索引和检索服务, 它们可以托管在集群的任一 node 上。
2.9、Replica(副本)
可以为 shard 创建副本,提高数据的安全性。建立索引时, 系统会先将索引存储在主分片(Primary Shard)中, 然后再将主分片中的索引复制到副本分片(Replica Shard)中。副本提高了系统的可用性、容错性和吞吐量。
2.10、Elasticsearch 和 RDBMS 的对比
| Elasticsearch | RDBMS |
| Index(索引) | DataBase(数据库) |
| Type(类型) | Table(表) |
| Document(文档) | Row(行) |
| Field(字段) | Column(列) |
| Mapping(映射) | Schema(约束) |
| Query DSL(ES 的查询语言) | SQL(结构化查询语言) |
3、Elasticsearch 字段类型
3.1、Common types
| 字段类型 | 说明 | |
| binary | 二进制类型,存储 Base64 编码后的数据 | |
| boolean | 布尔类型,False values: false, "false", "" (empty string);True values: true, "true" | |
| Keywords | keyword | 关键字类型,不就行分词处理 |
| constant_keyword | 当所有文档的某个 keyword 字段具有相同值时,可以使用该字段 | |
| wildcard | 用于 wildcard 查询,具有更高的效率 | |
| Numbers | long | -2^63~2^63-1 |
| integer | -2^31~2^31-1 | |
| short | -32768~32767 | |
| byte | -128~127 | |
| double | 双精度 64 位 IEEE 754 浮点数 | |
| float | 单精度 32 位 IEEE 754 浮点数 | |
| half_float | 半精度 16 位 IEEE 754 浮点数 | |
| scaled_float | 带缩放因子的缩放类型浮点数,需配合缩放因子 scaling_factor 一起使用。 | |
| unsigned_long | 无符号 64 位整数,0~2^64-1 | |
| Dates | date |
日期类型,可以存储以下格式(通过format指定格式,可指定多个格式): |
| date_nanos |
date 类型以毫秒为粒度存储日期,date_nanos 以纳秒为粒度存储日期 |
|
| alias |
设置字段别名 |
3.2、Objects and relational types
| 字段类型 | 说明 | |
| object | JSON 对象类型 |
3.3、Structured data types
| 字段类型 | 说明 | |
| Range | 范围字段类型表示上限和下限之间的连续值范围,使用 gt 或 gte 来定义下限,使用 lt 或 lte 来定义上限。 | |
| integer_range | -2^31~2^31-1 | |
| float_range | 单精度 32 位 IEEE 754 浮点数值范围 | |
| long_range | -2^63~2^63-1 | |
| double_range | 双精度 64 位 IEEE 754 浮点数值范围 | |
| date_range | 日期值范围 | |
| ip_range | ip 范围,支持 IPv4 和 IPv6 | |
| ip | ip 类型,支持 IPv4 和 IPv6 |
3.4、Text search types
| 字段类型 | 说明 | |
| text fields | text | 文本类型,会就行分词处理 |
| match_only_text | 一种空间优化的 text 变体,它禁用评分,并且位置查询较慢。它最适合用于索引日志消息。 |
3.5、Spatial data types
| 字段类型 | 说明 | |
| geo_point | 经纬度类型 | |
4、Elasticsearch 分词器
| 分词器 | 说明 |
| standard | 默认分词器,按词切分,小写处理 |
| simple | 按照非字母切分(符号被过滤),小写处理 |
| stop | 小写处理,停用词过滤(the ,a,is) |
| whitespace | 按照空格切分,不转小写 |
| keyword | 不分词,直接将输入当做输出 |
| pattern | 正则表达式,默认 \W+ |
| ik_smart | ik 分词器,只分一次,句子里面的每个字只会出现一次 |
| ik_max_word | ik 分词器,句子的字可以反复出现。 |
5、Elasticsearch 逻辑架构图

RESTful Style API:RESTful 风格接口。
Java(Netty):Java 客户端。
Transport:集群与客户端交互方式。
Disvcovery:节点发现及 master 选举。Zen 属于 ES 的特殊发现机制,也是 ES 的内置发现机制,它提供了两种发现方式:单播和多播。EC2 是另外一种插件形式的发现机制。
Scripting:脚本功能,支持 mvel、js、python等。
3rd plugins:第三方插件。
Index Moudle:索引模块。
Search Moudle:查询模块。
Mapping:映射信息。
River:用于其他数据源中获取数据,该项功能以插件的形式存在,目前支持的数据源:RabbitMQ、ActiveMQ、CSV、FileSystem、JDBC、GitHub、Kafka 等;针对关系型数据库提供了统一的 jdbc-river 来进行数据操作。
DistributedLucene Directory:Lucene 数据目录。
Gateway:ElasticSearch 索引的持久化存储方式。Gateway支持多种类型:本地文件系统(默认)、分布式文件系统 Hadoop 以及 AMZ 的 S3 云存储服务。
6、Elasticsearch 组件关系图


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律