SpringCloud 入门实战(12)--Zipkin(2)--安装使用
Zipkin 的介绍参见上一篇文章:SpringCloud 入门实战(11)--Zipkin 使用一(Zipkin 简介)。本文主要介绍 Zipkin 的基本使用,文中所使用到的软件版本:Zipkin 2.23.2、Spring Boot 2.3.11.RELEASE、Spring Cloud Hoxton.SR8、jdk1.8.0_181。
1、Zipkin 安装
1.1、下载应用包
在能连外网的机器上执行:
curl -sSL https://zipkin.io/quickstart.sh | bash -s
执行命令完成后,就会下载 Zipkin 的应用包:zipkin.jar。
1.2、存储方式
Zipkin 可以把数据保存在内存、MySQL、Cassandra、Elasticsearch 中,详细的配置说明可参考官方说明:https://github.com/openzipkin/zipkin/tree/master/zipkin-server。
1.2.1、数据保存在内存中
参数:
MEM_MAX_SPANS:保存的最大 span 的数量,超过了会把最早的 span 删除
启动命令例子:
MEM_MAX_SPANS=1000000 java -Xmx1G -jar zipkin.jar
1.2.2、数据保存在 MySQL 中
该种存储方式已不推荐使用,在数据量大的时候,查询较慢。
数据库初始化脚本:https://github.com/openzipkin/zipkin/blob/master/zipkin-storage/mysql-v1/src/main/resources/mysql.sql


-- -- Copyright 2015-2019 The OpenZipkin Authors -- -- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except -- in compliance with the License. You may obtain a copy of the License at -- -- http://www.apache.org/licenses/LICENSE-2.0 -- -- Unless required by applicable law or agreed to in writing, software distributed under the License -- is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express -- or implied. See the License for the specific language governing permissions and limitations under -- the License. -- CREATE TABLE IF NOT EXISTS zipkin_spans ( `trace_id_high` BIGINT NOT NULL DEFAULT 0 COMMENT 'If non zero, this means the trace uses 128 bit traceIds instead of 64 bit', `trace_id` BIGINT NOT NULL, `id` BIGINT NOT NULL, `name` VARCHAR(255) NOT NULL, `remote_service_name` VARCHAR(255), `parent_id` BIGINT, `debug` BIT(1), `start_ts` BIGINT COMMENT 'Span.timestamp(): epoch micros used for endTs query and to implement TTL', `duration` BIGINT COMMENT 'Span.duration(): micros used for minDuration and maxDuration query', PRIMARY KEY (`trace_id_high`, `trace_id`, `id`) ) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci; ALTER TABLE zipkin_spans ADD INDEX(`trace_id_high`, `trace_id`) COMMENT 'for getTracesByIds'; ALTER TABLE zipkin_spans ADD INDEX(`name`) COMMENT 'for getTraces and getSpanNames'; ALTER TABLE zipkin_spans ADD INDEX(`remote_service_name`) COMMENT 'for getTraces and getRemoteServiceNames'; ALTER TABLE zipkin_spans ADD INDEX(`start_ts`) COMMENT 'for getTraces ordering and range'; CREATE TABLE IF NOT EXISTS zipkin_annotations ( `trace_id_high` BIGINT NOT NULL DEFAULT 0 COMMENT 'If non zero, this means the trace uses 128 bit traceIds instead of 64 bit', `trace_id` BIGINT NOT NULL COMMENT 'coincides with zipkin_spans.trace_id', `span_id` BIGINT NOT NULL COMMENT 'coincides with zipkin_spans.id', `a_key` VARCHAR(255) NOT NULL COMMENT 'BinaryAnnotation.key or Annotation.value if type == -1', `a_value` BLOB COMMENT 'BinaryAnnotation.value(), which must be smaller than 64KB', `a_type` INT NOT NULL COMMENT 'BinaryAnnotation.type() or -1 if Annotation', `a_timestamp` BIGINT COMMENT 'Used to implement TTL; Annotation.timestamp or zipkin_spans.timestamp', `endpoint_ipv4` INT COMMENT 'Null when Binary/Annotation.endpoint is null', `endpoint_ipv6` BINARY(16) COMMENT 'Null when Binary/Annotation.endpoint is null, or no IPv6 address', `endpoint_port` SMALLINT COMMENT 'Null when Binary/Annotation.endpoint is null', `endpoint_service_name` VARCHAR(255) COMMENT 'Null when Binary/Annotation.endpoint is null' ) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci; ALTER TABLE zipkin_annotations ADD UNIQUE KEY(`trace_id_high`, `trace_id`, `span_id`, `a_key`, `a_timestamp`) COMMENT 'Ignore insert on duplicate'; ALTER TABLE zipkin_annotations ADD INDEX(`trace_id_high`, `trace_id`, `span_id`) COMMENT 'for joining with zipkin_spans'; ALTER TABLE zipkin_annotations ADD INDEX(`trace_id_high`, `trace_id`) COMMENT 'for getTraces/ByIds'; ALTER TABLE zipkin_annotations ADD INDEX(`endpoint_service_name`) COMMENT 'for getTraces and getServiceNames'; ALTER TABLE zipkin_annotations ADD INDEX(`a_type`) COMMENT 'for getTraces and autocomplete values'; ALTER TABLE zipkin_annotations ADD INDEX(`a_key`) COMMENT 'for getTraces and autocomplete values'; ALTER TABLE zipkin_annotations ADD INDEX(`trace_id`, `span_id`, `a_key`) COMMENT 'for dependencies job'; CREATE TABLE IF NOT EXISTS zipkin_dependencies ( `day` DATE NOT NULL, `parent` VARCHAR(255) NOT NULL, `child` VARCHAR(255) NOT NULL, `call_count` BIGINT, `error_count` BIGINT, PRIMARY KEY (`day`, `parent`, `child`) ) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci;
参数:
MYSQL_DB:MySQL 数据库名,默认为 zipkin
MYSQL_USER:用户名
MYSQL_HOST:主机地址
MYSQL_TCP_PORT:端口
MYSQL_MAX_CONNECTIONS:最大连接数据,默认 10
MYSQL_USE_SSL:是否使用ssl,需要 javax.net.ssl.trustStore 和 javax.net.ssl.trustStorePassword, 默认 false
MYSQL_JDBC_URL:自己设置 JDBC 的 url
启动命令例子:
MYSQL_USER=root MYSQL_PASS=123456 MYSQL_HOST=10.49.196.10 MYSQL_TCP_PORT=3306 java -jar zipkin.jar
1.3、采集方式
1.3.1、HTTP Collector
HTTP 方式默认开启,通过 POST /api/v1/spans 和 POST /api/v2/spans 地址接受数据;相关配置如下:
| 环境变量 | 属性 | 描述 |
| COLLECTOR_HTTP_ENABLED | zipkin.collector.http.enabled | 是否启用 HTTP 方式采集数据,默认 true |
1.3.2、Kafka Collector
当 KAFKA_BOOTSTRAP_SERVERS 不为空时该方式生效;相关配置如下:
| 环境变量 | 对应 kafka 消费者配置 | 描述 |
| COLLECTOR_KAFKA_ENABLED | 是否启用 Kafka 方式采集数据,默认 true | |
| KAFKA_BOOTSTRAP_SERVERS | bootstrap.servers | Kafk 地址 |
| KAFKA_GROUP_ID | group.id | 消费者所属消费者组,默认 zipkin |
| KAFKA_TOPIC | 主题,多个以逗号分隔,默认 zipkin | |
| KAFKA_STREAMS | 消费者的线程数,默认 1 |
启动命令例子:
KAFKA_BOOTSTRAP_SERVERS=127.0.0.1:9092 java -jar zipkin.jar
2、Zipkin 使用
这里主要介绍在 Spring Cloud 中集成 Zipkin;使用起来还是很方便的,只需引入相关依赖并配置 Zipkin 的地址即可,然后就会把请求的监控数据发往 Zipkin。
2.1、Http 方式发送数据到 Zipkin
2.1.1、引入依赖
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-zipkin</artifactId> </dependency>
2.1.2、application.yml
配置 Zipkin 地址
spring: zipkin: base-url: http://10.49.196.10:9411/ enabled: true
2.2、Kafka 方式发送数据到 Zipkin
启动 Kafka 并创建 Topic:zipkin;配置 Zipkin 的服务端从 Kafka 接受数据;参见 1.3.2
2.2.1、引入依赖
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-zipkin</artifactId> </dependency> <dependency> <groupId>org.springframework.kafka</groupId> <artifactId>spring-kafka</artifactId> </dependency>
2.1.2、application.yml
spring: zipkin: enabled: true sender: type: kafka kafka: topic: zipkin kafka: bootstrap-servers: 10.49.196.10:9092
2.3、监控 MySQL 操作
这里假设在 2.1 Spring Cloud 项目的基础再进一步对 MySQL 的操作进行监控。
2.3.1、引入依赖
<dependency> <groupId>io.zipkin.brave</groupId> <artifactId>brave-instrumentation-mysql8</artifactId> <version>5.13.3</version> </dependency>
2.3.2、jdbc url 中增加参数
在 jdbc url 中添加拦截器和服务名:
queryInterceptors=brave.mysql8.TracingQueryInterceptor&exceptionInterceptors=brave.mysql8.TracingExceptionInterceptor&zipkinServiceName=myDatabaseService
例如,配置如下的数据源:
spring: datasource: druid: primary: driverClassName: com.mysql.cj.jdbc.Driver url: jdbc:mysql://10.49.196.10:3306/test?useUnicode=true&characterEncoding=UTF-8&queryInterceptors=brave.mysql8.TracingQueryInterceptor&exceptionInterceptors=brave.mysql8.TracingExceptionInterceptor&zipkinServiceName=myDB username: root password: 123456 initialSize: 2 minIdle: 2 maxActive: 5 validationQuery: SELECT 1 testWhileIdle: true testOnBorrow: true testOnReturn: false maxWait: 6000 filters: wall,slf4j
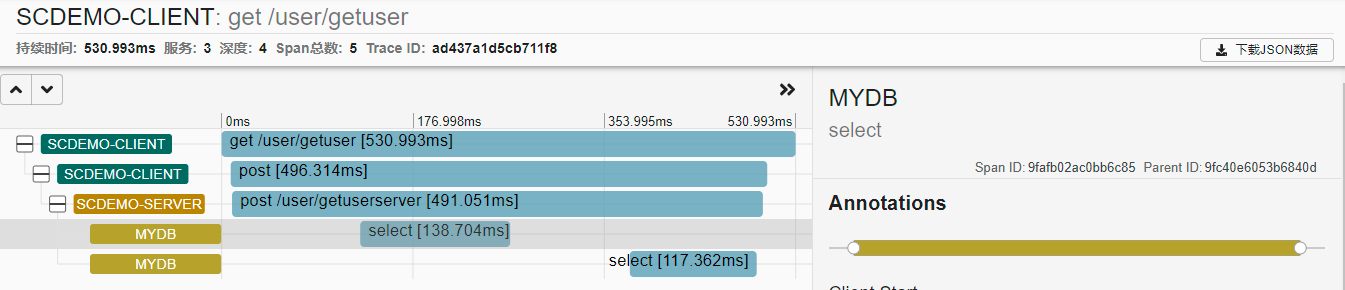
3、测试
前台访问 scdemo-client 服务,在 scdemo-client 中又调用 scdemo-server 服务,在 scdemo-server 执行了两次查询 MySQL 的操作。