


SpringCloud 入门实战(11)--Zipkin(1)--简介
Zipkin 是一款开源的分布式实时数据追踪系统,基于 Google Dapper 的论文设计而来,由 Twitter 公司开发贡献;其主要功能是聚集来自各个异构系统的实时监控数据。本文主要介绍下 Zipkin 的基本概念。
1、Zipkin 结构
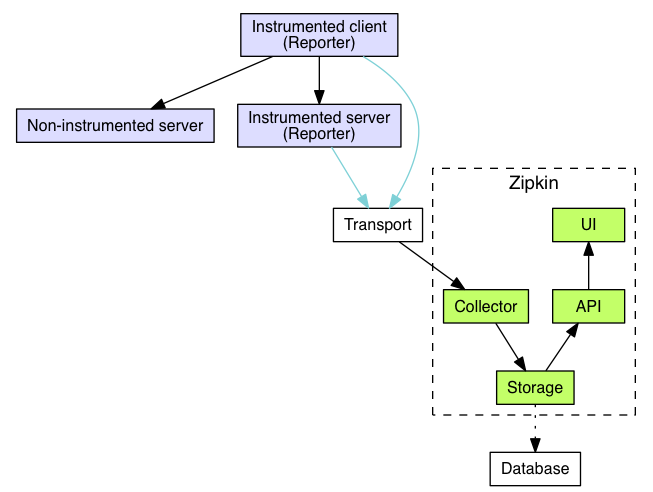
1.1、Zipkin 服务端
Zipkin 服务端由四部分组成:
Collector:收集器组件,处理从外部系统发送过来的跟踪信息,将这些信息转换为 Zipkin 内部的 Span 格式,以支持后续的存储、分析、展示等功能。
Storage:存储组件,存储收集器接收到的跟踪信息,默认会将这些信息存储在内存中;可以修改存储策略,把跟踪信息保存到 MySQL、cassandra、elasticsearch。
API:API组件,提供 API 接口供 UI 组件调用,外接系统访问该 API 实现定制化的监控。
UI:UI组件,基于 API 组件实现的上层应用;通过 UI 可以方便直观地查询和分析跟踪信息。
1.2、Zipkin 客户端
Brave 是 Zipkin 提供的 Java 版本的信息采集插件;提供了面向 Standard Servlet、Spring MVC、Http Client、JAX RS、Jersey、Resteasy 和 MySQL 等框架的采集能力,可以通过简单的配置和代码,让基于这些框架构建的应用向 Zipkin 报告数据。同时 Brave 也提供了非常简单且标准化的接口,在以上封装无法满足要求的时候可以方便扩展与定制。Brave 主要是利用拦截器在请求前和请求后分别埋点。例如 Spingmvc 监控使用 Interceptors,Mysql 监控使用 statementInterceptors。同理 Dubbo 的监控是利用 com.alibaba.dubbo.rpc.Filter 来过滤生产者和消费者的请求。
当然 Zipkin 也提供 其他语言的客户端:C#、Go、JavaScript、Ruby、Scala、PHP。
1.3、Transport
连接 Zipkin 服务端和客户端的数据传输通道(Transport) 可以为:Http, Kafka, Scribe。
支持的客户端及传输通道详情可参考官网:https://zipkin.io/pages/tracers_instrumentation.html
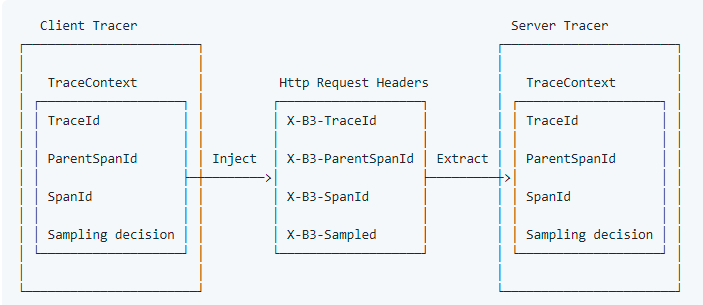
2、Zipkin 传播规范
当上游服务通过 HTTP 调用下游服务,如何将两个服务中的所有 span 串联起来,形成一个 trace,这就需要上游服务将 traceId 等信息传递给下游服务,而不能让下游重新生成一个 traceId。Zipkin 通过 B3 传播规范(B3 Propagation),将相关信息(如 traceId、spanId 等)通过 HTTP 请求 Header 传递给下游服务:
3、Zipkin 数据模型
[{ "traceId": "8cafeeba762c479e", "parentId": "c149cb2af458c95d", "id": "b5809e988d9b47f8", "kind": "CLIENT", "name": "post", "timestamp": 1623828578382618, "duration": 848226, "localEndpoint": {"serviceName": "scdemo-client"}, "remoteEndpoint": {"ipv4": "10.49.196.1", "port": 9001}, "tags": {"http.method": "POST", "http.path": "/user/getUserServer"} }, { "traceId": "8cafeeba762c479e", "parentId": "8cafeeba762c479e", "id": "c149cb2af458c95d", "kind": "CLIENT", "name": "post", "timestamp": 1623828578373868, "duration": 860200, "localEndpoint": {"serviceName": "scdemo-client"}, "tags": {"http.method": "POST", "http.path": "/user/getUserServer"} }, { "traceId": "8cafeeba762c479e", "id": "8cafeeba762c479e", "kind": "SERVER", "name": "get /user/getuser", "timestamp": 1623828578361068, "duration": 893538, "localEndpoint": {"serviceName": "scdemo-client"}, "remoteEndpoint": {"ipv6": "::1", "port": 65247}, "tags": { "http.method": "GET", "http.path": "/user/getUser", "mvc.controller.class": "UserController", "mvc.controller.method": "getUser" } }, { "traceId": "8cafeeba762c479e", "parentId": "b5809e988d9b47f8", "id": "872ba1f271335796", "kind": "CLIENT", "name": "select", "timestamp": 1623828579160625, "duration": 16508, "localEndpoint": {"serviceName": "scdemo-server"}, "remoteEndpoint": {"serviceName": "mydb", "ipv4": "10.48.196.10", "port": 3306}, "tags": {"sql.query": "select now()"} }, { "traceId": "8cafeeba762c479e", "parentId": "b5809e988d9b47f8", "id": "26f5a8fb4cfacdfc", "kind": "CLIENT", "name": "select", "timestamp": 1623828579198865, "duration": 5071, "localEndpoint": {"serviceName": "scdemo-server"}, "remoteEndpoint": {"serviceName": "mydb", "ipv4": "10.49.196.10", "port": 3306}, "tags": {"sql.query": "select version()"} }, { "traceId": "8cafeeba762c479e", "parentId": "c149cb2af458c95d", "id": "b5809e988d9b47f8", "kind": "SERVER", "name": "post /user/getuserserver", "timestamp": 1623828578523548, "duration": 709280, "localEndpoint": {"serviceName": "scdemo-server"}, "remoteEndpoint": {"ipv4": "10.49.196.1", "port": 65248}, "tags": { "http.method": "POST", "http.path": "/user/getUserServer", "mvc.controller.class": "UserController", "mvc.controller.method": "getUser" }, "shared": true }]
traceId 一次请求全局只有一个traceId。用来在海量的请求中找到同一链路的几次请求。比如servlet服务器接收到用户请求,调用dubbo服务,然后将结果返回给用户,整条链路只有一个traceId。开始于用户请求,结束于用户收到结果。
id 即spanId,一个链路中每次请求都会有一个spanId。例如一次rpc,一次sql都会有一个单独的spanId从属于traceId。
parentId 当前 Span 的父 Span id,通过 parentId 来确定 Span 之间的依赖关系,如果没有 parentId,表示当前 Span 为根 Span。
timestamp Span 创建时的时间戳,单位是微秒
duration 本次请求的持续时间,单位是微秒
annotations 用于记录请求的开始和结束:
cs Clent Sent 客户端发起请求的时间。
cr Client Receive 客户端收到处理完请求的时间。
ss Server Receive 服务端处理完逻辑的时间。
sr Server Receive 服务端收到调用端请求的时间。
sr - cs = 请求在网络上的耗时 ss - sr = 服务端处理请求的耗时 cr - ss = 回应在网络上的耗时 cr - cs = 一次调用的整体耗时
4、Zipkin 工作过程
当发起一次调用时,Zipkin 的客户端会在入口处为整条调用链路生成一个全局唯一的 trace id,并为这条链路中的每一次分布式调用生成一个 span id。span 与 span 之间可以有父子嵌套关系,代表分布式调用中的上下游关系。span 和 span 之间可以是兄弟关系,代表当前调用下的两次子调用。一个 trace 由一组 span 组成,可以看成是由 trace 为根节点,span 为若干个子节点的一棵树。
Zipkin 会将 trace 相关的信息在调用链路上传递,并在每个调用边界结束时异步的把当前调用的耗时信息上报给 Zipkin Server。Zipkin Server 在收到 trace 信息后,将其存储起来。随后 Zipkin 的 Web UI 会通过 API 访问的方式从存储中将 trace 信息提取出来分析并展示。
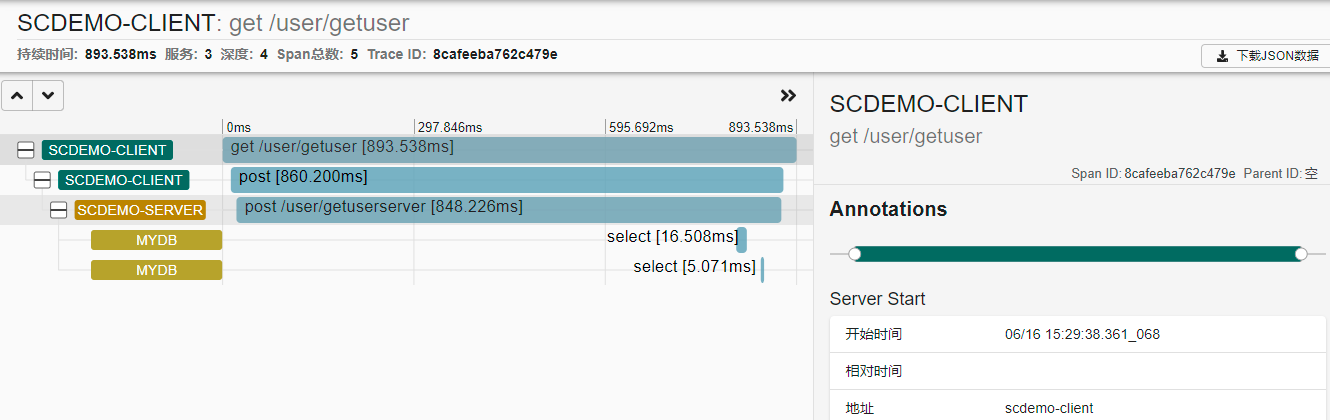
5、Zipkin 效果展示
Zipkin 可以查看一次请求的整个链路的调用情况:
也可以查看各模块之间的依赖情况:


