

Python笔记(二):数据类型、字符编码
数据类型
float:浮点型
浮点数是属于有理数中某特定子集的数的数字表示,在计算机中用以近似表示任意某个实数。具体的说,这个实数由一个整数或定点数(即尾数)乘以某个基数的整数次幂得到,这种表示方法类似于基数为10的科学计数法。
整数和浮点数在计算机内部的存储方式是不同的,整数永远精确而浮点数运算可能有误差
Python默认17位精度,也就是小数点后16位,但是精度越往后越不准
str:字符串
用以存储和表示基本的文本信息,所有引号引起来的都是字符串
特性:
有序--有索引
不可变--所有对字符串的操作都是形成一个新的字符串
索引和切片
1 s = "abCde123asD5" 2 3 s1 = s[0] # 字符串有索引,从0开始 4 # a 5 s2 = s[-1] # 倒着取 6 # 5 7 s3 = s[0:3] # 取索引为0-3,不包括3,顾头不顾尾 8 # abC 9 s4 = s[0:-1] # 从头取到位,取不到最后一个 10 # abCde123asD 11 s5 = s[0:] # 从头取到尾,取所有 12 # abCde123asD5 13 s6 = s[:] # 取所有 14 # abCde123asD5 15 s7 = s[1:6:2] # 取2-6,步长为2 16 # bd1 17 s8 = s[-1:0:-1] # 倒着取,取不到索引为0的,顾头不顾尾 18 # 5Dsa321edCb 19 s9 = s[::-1] # 倒着取,取所有 20 # 5Dsa321edCba 21 s10 = s[-1:3:-2] # 倒着取,步长为2 22 # 5s31
字符串的操作
1 # 字符串的操作 2 s = "abCde123asD5" 3 4 s1 = s.capitalize() # 首字母大写 5 # Abcde123asd5 # 如果第一个字符不是字母,后面所有字母都变小写 6 s11 = s.title() # 每个被非字母字符隔开的单词首字母大写 7 # Abcde123Asd5 8 s12 = s.upper() # 全大写 9 # ABCDE123ASD5 10 s13 = s.lower() # 全小写 11 # abcde123asd5 12 s14 = s.swapcase() #大小写反转 13 # ABcDE123ASd5 14 15 s2 = s.isalnum() # 判断字符串是否由字母和数字组成,返回bool 16 # True 17 s21 = s.isalpha() # 判断字符串是否是纯字母 18 # False 19 s22 = s.isdigit() # 是否是纯数字 20 # False 21 s23 = s.istitle() # 是否每个隔开的单词首字母都是大写 22 # False 23 s24 = s12.isupper() # 是否全大写 24 # True 25 26 s3 = s.center(20) # 总长度20,字符串居中,两侧空格填充 27 # abCde123asD5 28 s31 = s.center(20,'*') # 填充字符可以设置 29 # ****abCde123asD5**** 30 31 s4 = s.find('s') # 通过元素找索引,第一个匹配的索引 32 # 9 33 s41 = s.find('k') # 找不到,返回-1 34 # -1 35 s42 = s.index('s') # 通过元素找索引,第一个匹配的索引 36 # 9 37 # s43 = s.index('k') # 找不到,报错 38 # print(s43) 39 40 s5 = s.startswith('a') # 判断字符串是否以a开头,返回bool 41 # True 42 s51 = s.startswith('b',3,6) # 可切片 43 # False 44 s52 = s.startswith('abc') 45 # False 46 s53 = s.endswith('5') # 判断是否以某元素结尾 47 # True 48 49 s6 = s.replace('a','9') # 替换 50 # 9bCde1239sD5 51 s7 = s.count('a') # 统计元素在字符串中出现的次数 52 # 2 53 s8 = len(s) # 字符串长度 54 # 12 55 56 57 s = " as1*fr 23d\tdb** " 58 59 s1 = s.expandtabs() # \t前面的补全 默认将一个tab键变成8个空格,若tab前不足8个,则补全8个,超过则补全为8的倍数 60 # as1*fr 23d db ** 61 s2 = s.strip() # 去除字符串两侧的空格 62 # as1*fr 23d db** 63 s21 = s.strip(' *') # 可以设置要去除的元素 64 # as1*fr 23d db 65 66 s3 = s.split() # 字符串以空格分割,形成列表 67 # ['as1*fr', '23d', 'db**'] 68 s31 = s.split('*') # 可以设置以某元素分割 69 # [' as1', 'fr 23d\tdb', '', ' '] 70 71 72 li = ['abc','qw23','alex'] 73 s1 = ''.join(li) # 列表转换字符串 74 # abcqw23alex 75 s2 = '_'.join(li) # 可以设置以某元素连接 76 # abc_qw23_alex
格式化输出 format()
1 name = input("名字:") 2 age = input("年龄:") 3 hob = input("爱好:") 4 s = "我叫{},今年{}岁,喜欢{},是的,我是{}".format(name,age,hob,name) 5 print(s) 6 s = "我叫{0},今年{1}岁,喜欢{2},是的,我是{0}".format(name,age,hob) 7 print(s) 8 9 s = "我叫{name},今年{age}岁,喜欢{hob},是的,我是{name}".format(hob='girl',name='alex',age='22') 10 print(s)
list:列表
列表是一个数据的集合,集合内可以放任何数据类型,可对集合进行方便的增删改查操作
创建
1 l1 = [] # 定义空列表 2 l2 = ['a','b','c','d'] # 创建列表,索引0,1,2,3 3 l3 = ['abc',['alex',1,2]] # 嵌套列表 4 5 l4 = list() # 创建空列表 6 print(l4) 7 []
查询
1 li = ['a','b','c',2,3,4,'d','a','e'] 2 3 l1 = li[0] # 通过索引取值 4 # a 5 l2 = li[-1] # 通过索引从右边开始找 6 # e 7 l3 = li[-2] 8 # a 9 l4 = li.index('a') # 返回指定元素的索引值,从左往右找,找到第一个匹配值 则返回 10 # 0 11 l5 = li.count('a') # 统计指定元素的个数 12 # 2
切片
1 li = ['a','b','c',2,3,4,'d','a','e'] 2 3 l1 = li[0:3] # 返回索引0-3的元素,不包括3,顾头不顾尾 4 # ['a', 'b', 'c'] 5 l2 = li[0:-1] # 返回索引从0至最后的元素,不包括最后一个 6 # ['a', 'b', 'c', 2, 3, 4, 'd', 'a'] 7 l3 = li[3:6] 8 # [2, 3, 4] 9 l4 = li[3:] # 返回索引0至最后所有元素 10 # [2, 3, 4, 'd', 'a', 'e'] 11 l5 = li[:3] # 返回索引0至3的元素,不包括3 12 # ['a', 'b', 'c'] 13 l6 = li[1:6:2] # 返回索引1-6的元素,步长为2(隔一个,取一个值) 14 # ['b', 2, 4] 15 l7 = li[:] # 返回所有 16 # ['a', 'b', 'c', 2, 3, 4, 'd', 'a', 'e'] 17 l8 = li[::2] # 按步长为2返回所有 18 # ['a', 'c', 3, 'd', 'e']
增加、修改
1 li = ['a','b',1,4,'e'] 2 3 li.append('A') # 列表尾部追加A 4 # ['a', 'b', 1, 4, 'e', 'A'] 5 li.insert(3,'E') # 在列表索引为3的位置 插入一个值 E 6 # ['a', 'b', 1, 'E', 4, 'e', 'A'] 7 li[3] = 'alex' # 把索引为3的元素改为alex 8 # ['a', 'b', 1, 'alex', 4, 'e', 'A'] 9 li[3:5] = 'alex' # 把索引3-5的元素改为alex,不够的元素自己增加 10 # ['a', 'b', 1, 'a', 'l', 'e', 'x', 'e', 'A']
删除
1 li = ['a', 'b', 1, 'a', 'l', 'e', 'x', 'e', 'A'] 2 3 li.pop() # 删除最后一个元素 4 # ['a', 'b', 1, 'a', 'l', 'e', 'x', 'e'] 5 li.remove('a') # 删除从左到右找到的第一个指定元素 6 # ['b', 1, 'a', 'l', 'e', 'x', 'e'] 7 del li[4] # 删除索引为4的元素 8 # ['b', 1, 'a', 'l', 'x', 'e'] 9 del li[3:5] # 删除多个元素 10 # ['b', 1, 'a', 'e']
循环
1 li = ['b', 1, 'a', 'l', 'x', 'e'] 2 for i in li: 3 print(i)
排序
1 li = ['b', 1, 'a', 'l', 'X', 'e'] 2 li.sort() # 不能对包含str和int的列表排序 3 # TypeError: unorderable types: int() < str() 4 5 li = ['b', '*', 'a', '$','l', 'X', 'e'] 6 li.sort() # 按ASCII排序 7 # ['$', '*', 'X', 'a', 'b', 'e', 'l'] 8 li.reverse() # 反转 9 # ['l', 'e', 'b', 'a', 'X', '*', '$']
其他用法
1 li = ['l', 'e', 'b', 'a', 'X', '*', '$'] 2 3 li.extend([1,2,3,4]) # 把一个列表扩展到li列表 4 # ['l', 'e', 'b', 'a', 'X', '*', '$', 1, 2, 3, 4] 5 6 li[2] = ['alex','rain','jack'] 7 # ['l', 'e', ['alex', 'rain', 'jack'], 'a', 'X', '*', '$', 1, 2, 3, 4] 8 l1 = li[2][1] # 嵌套列表取值 9 # rain 10 11 li.clear() # 清空列表 12 # []
tuple:元祖
又叫只读列表,一旦创建,就不能再修改
特性:
不可变
元组本身不可变,如果元组中还包含其他可变元素,这些可变元素可以改变
使用场景:
显示的告诉别人,此处数据不可修改
数据库连接配置信息等
1 tu = ('l', 'e', ['alex', 'rain', 'jack'], 'a', 'X', 3, 4) 2 3 # tu[0] = '123' # 报错,不可更改 4 tu[2][1] = '123' # 可以改 5 # ('l', 'e', ['alex', '123', 'jack'], 'a', 'X', 3, 4) 6 7 tu.index('a') 8 # 3 9 tu.count('a') 10 # 1 11 # 切片 #同列表一样
dict:字典
key-value结构
key必须可哈希、且必须为不可变数据类型、必须唯一
value可存放任意多个值、可修改、可以不唯一
无序
查找速度快
增删改查
1 info = { 2 "alex":[26,"技术部","工程师",12345], 3 "shanshan":[25,"公关部","夜魔",13579], 4 "龙庭":[22,"设计部","UI",23234] 5 } 6 7 info["jack"] = [23,"销售部","经理",45678] # 增加 8 print(info) 9 info["alex"][0] = 18 # 修改 10 # {'alex': [18, '技术部', '工程师', 12345], 'shanshan': [25, '公关部', '夜魔', 13579], 'jack': [23, '销售部', '经理', 45678], '龙庭': [22, '设计部', 'UI', 23234]} 11 12 print("alex" in info) # 查找 判断在不在字典里 13 # True 14 print(info.get("alex")) # 获取 15 # [18, '技术部', '工程师', 12345] 16 print(info["alex"]) # 获取 17 # [18, '技术部', '工程师', 12345] 18 # print(info["rain"]) # key不存在,会报错 19 print(info.get("rain")) # key不存在,返回None 20 # None 21 22 print(info.pop("alex")) # 删除,返回删除key所对应的value 23 # [18, '技术部', '工程师', 12345] 24 print(info.popitem()) # 随机删,返回元组 25 # ('jack', [23, '销售部', '经理', 45678]) 26 del info["alex"] # 删除,无返回值
嵌套
1 info = { 2 "alex": { 3 "age": 26, 4 "post": "工程师", 5 "Tel": 12345 6 }, 7 "shanshan": { 8 "age": 25, 9 "post": "夜魔", 10 "Tel": 13579 11 }, 12 } 13 14 info["alex"]["age"] = 18 15 print(info)
其他方法
1 info = { 2 "alex": [26, "工程师"], 3 "shanshan": [25, "夜魔"], 4 } 5 6 print(info.values()) 7 # dict_values([[26, '工程师'], [25, '夜魔']]) 8 print(info.keys()) 9 # dict_keys(['alex', 'shanshan']) 10 print(info.items()) 11 # dict_items([('alex', [26, '工程师']), ('shanshan', [25, '夜魔'])]) 12 13 info.setdefault("jack",22) # 显示”jack“的内容,字典没有,设置为22 14 # 22 15 print(info.setdefault("alex",22)) # 显示”alex“的内容,字典有,显示原值 16 # [26, '工程师'] 17 18 dic1 = {1:2,2:3,"alex":22} 19 info.update(dic1) # 更新,key不存在的添加,key存在的值覆盖 20 print(info) 21 22 info = info.fromkeys([1,2,3],"alex") # 通过一个列表生成默认字典 23 print(info)
循环
1 info = { 2 "alex": [26, "工程师"], 3 "shanshan": [25, "夜魔"], 4 } 5 # 循环 6 for k in info: # 只打印key 7 print(k) 8 9 for k in info: 10 print(k,info[k]) 11 12 for k,v in info.items(): # 低效 13 print(k,v)
set():集合
无序的,不重复的数据组合
作用:去重
关系测试 测试两组数据间交、差、并等关系
特性:
确定性 元素必须可哈希
互异性 去重
无序性
1 s = {} 2 print(type(s)) # 字典 3 s = {1} 4 print(type(s)) # 集合 5 s.pop() 6 print(s) 7 set() #空集合
增删改
1 s = {1,2,3,4,2,3,4} 2 3 # {1, 2, 3, 4} # 元素不重复 4 s.add(2) 5 # {1, 2, 3, 4} # 元素重复,添加不进去 6 s.add(22) # 增 7 # {1, 2, 3, 4, 22} 8 # s.add([5,6]) # 报错,只能添加不可变数据 9 10 s.update([4,5,6,7]) # 把多个值加入到集合 11 # {1, 2, 3, 4, 5, 6, 7, 22} 12 s.update({4,5,8,9}) 13 # {1, 2, 3, 4, 5, 6, 7, 8, 9, 22} 14 15 s.pop() # 随机删除元素,集合为空的话会报错 16 # {2, 3, 4, 5, 6, 7, 8, 9, 22} 17 s.discard(2) # 删除元素,没有也不报错 18 # {3, 4, 5, 6, 7, 8, 9, 22} 19 s.clear() # 清空集合 20 set() 21 s.remove(6) # 删除元素,不存在会报错
集合关系测试
1 s1 = {1,2,3,4} 2 s2 = {3,4,5,6} 3 4 s = s1.intersection(s2) 5 s = s1 & s2 # 交集 6 # {3, 4} 7 8 s = s1.difference(s2) 9 s = s1 - s2 # 差集 10 # {1, 2} 11 s = s2.difference(s1) 12 s = s2 - s1 13 # {5, 6} 14 15 s = s1.union(s2) 16 s = s1 | s2 # 并集 17 # {1, 2, 3, 4, 5, 6} 18 19 s = s1.symmetric_difference(s2) 20 s = s1 ^ s2 # 对称差集 21 s = (s1 | s2) - (s1 & s2) 22 # {1, 2, 5, 6} 23 24 s1.difference_update(s2) 25 print(s1) 26 # {1, 2} # 把s1中 也在s2中的元素 去掉
两个集合之间一般有三种关系,相交、包含、不相交
1 s1 = {1,2,3,4,5,6} 2 s2 = {1,2,3,4} 3 4 s1.issuperset(s2) 5 s1 >= s2 6 # True # s1是s2的超集 s1包含s2 7 s2.issubset(s1) 8 s2 <= s1 9 # True # s2是s1的子集 10 11 s1.isdisjoint(s2) 12 # False # 判断两个集合是不是不相交
基础数据类型总结
按储存空间的占用分(从低到高)
数字
字符串
集合:无序,无需存索引相关信息
元组:有序,需要存索引相关信息
不可变
列表:有序,需要存索引相关信息
可变,需要处理数据的增删改
字典:无序,需要存key与value映射的相关信息
可变,需要处理数据的增删改
按存值个数区分
标量/原子类型 数字,字符串
容器类型 列表,元组,字典
按可变不可变区分
可变 列表,字典
不可变 数字,字符串,元组,bool
按访问顺序区分
直接访问 数字
顺序访问(序列类型) 字符串,列表,元组
key值访问(映射类型) 字典
字符编码
电脑的传输,还有储存的实际上都是高低电平,对应01001001
# ASCII:美国标准信息交换代码, 只规定了英文字母数字和一些特殊字符
用8位二进制表示(一个字节)一个字符
最初只用了后7位,将拉丁文编码后占用了最高位
# Unicode:万国码 ,为解决传统的字符编码方案的局限而产生的,为每种语言的每个设定了统一并且唯一的二进制编码
最开始16位 之后32位 中文32位,4个字节
# utf-8:可变长 unicode transformation format 对unicode编码的压缩和优化
ascii 1个字节
欧洲 2个字节
亚洲 3个字节
# GBK:国内使用
英文 1个字节
中文 2个字节
windows系统默认编码GBK
Mac OS\Linux系统默认编码Utf-8
1、各个编码之间的二进制,是不能互相识别的,会产生乱码
2、文件的储存、传输,不能是unicode(只能是utf-8 utf-16 gbk gb2312 ascii等)
# 内存中统一采用unicode,浪费空间来换取可以转换成任意编码(不乱码),硬盘可以采用各种编码,如utf-8,保证存放于硬盘或者基于网络传输的数据量很小,提高传输效率与稳定性。
无论以什么编码在内存里显示字符,存到硬盘上都是二进制
存到硬盘上时是以何种编码存的,再从硬盘上读出来时,就必须以何种编码,要不然就乱了
python3的执行过程:
1、解释器找到代码文件,把代码字符串按文件头定义的编码加载到内存,转成unicode
2、把代码字符串按照语法规则进行解释
3、所有的变量字符都会以unicode编码声明
编码转换过程:
utf-8 --(decode解码)--> unicode --(encode编码)--> gbk
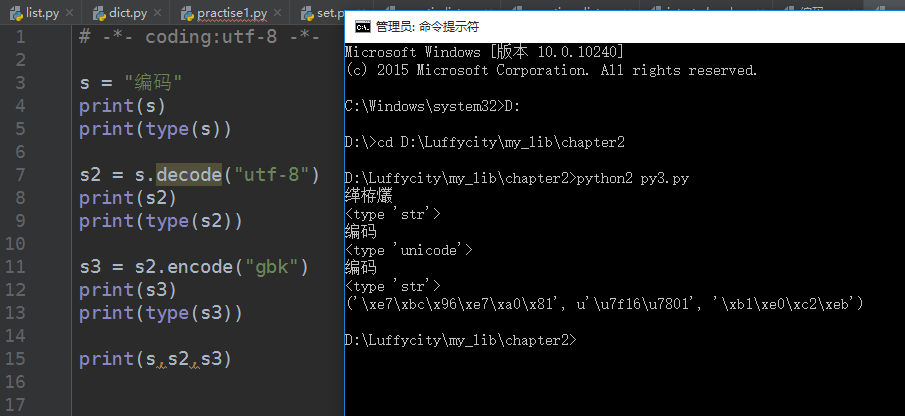
python的bytes类型:
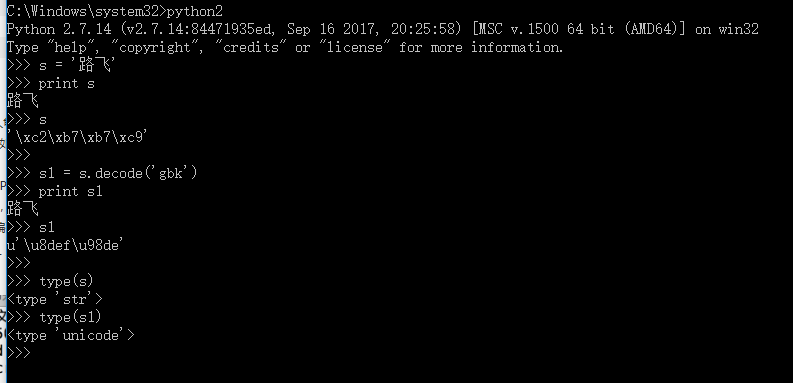
python2中的字符串更应该称为字节串。
python2中有str类型,bytes类型,unicode类型
str == bytes
str 解码后就会变成unicode类型
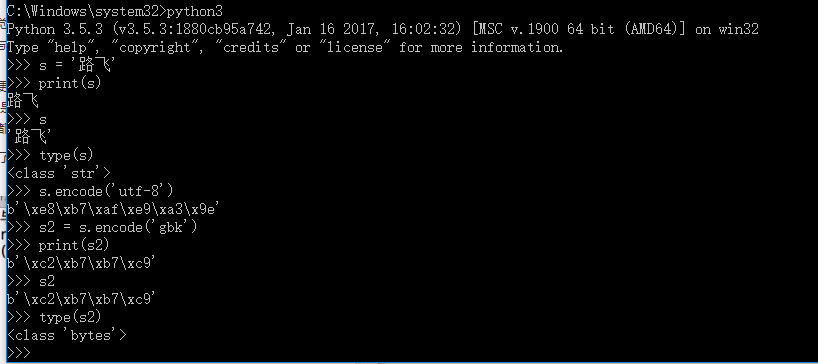
python3:默认编码utf-8,字符串是unicode类型
str 就是unicode格式的字符
bytes 就是单纯的二进制
(想在py3里看字符,必须是unicode编码,其他编码一律按bytes格式显示)
py2:以utf-8 or gbk.. 编码的代码,加载到内存中,并不会被转成unicode,编码依然是utf-8 or gbk
py3:以utf-8 or gbk.. 编码的代码,加载到内存中,会被自动转成unicode
python出现编码问题的原因:
python解释器的默认编码
python源文件文件编码
终端使用的编码
操作系统的语言设置
进制:
二进制:01
八进制:01234567
十进制:0123456789
十六进制:0123456789abcdef
1 a = 31 2 3 b = oct(a) 4 # 0o37 # 八进制 5 c = hex(a) 6 # 0x1f # 十六进制 7 d = bin(a) 8 # 0b11111 # 二进制
