FLAC: Federated Learning with Autoencoder Compression and Convergence Guarantee-2022
目的:减少通信量(成本),例如VGGNet架构具有大约1.38亿个参数(4264 Mb)
方法:具有自动编码器压缩(Autoencoder Compression)且具有收敛保证(Convergence Guarantee);利用冗余信息(the redundant information)和FL的迭代纠错能力(iterative error-correcting capability of FL)来压缩client的模型,从而减少用户上传模型的通信成本。(适应资源受限、通信资源受限的用户设备:带宽小......)
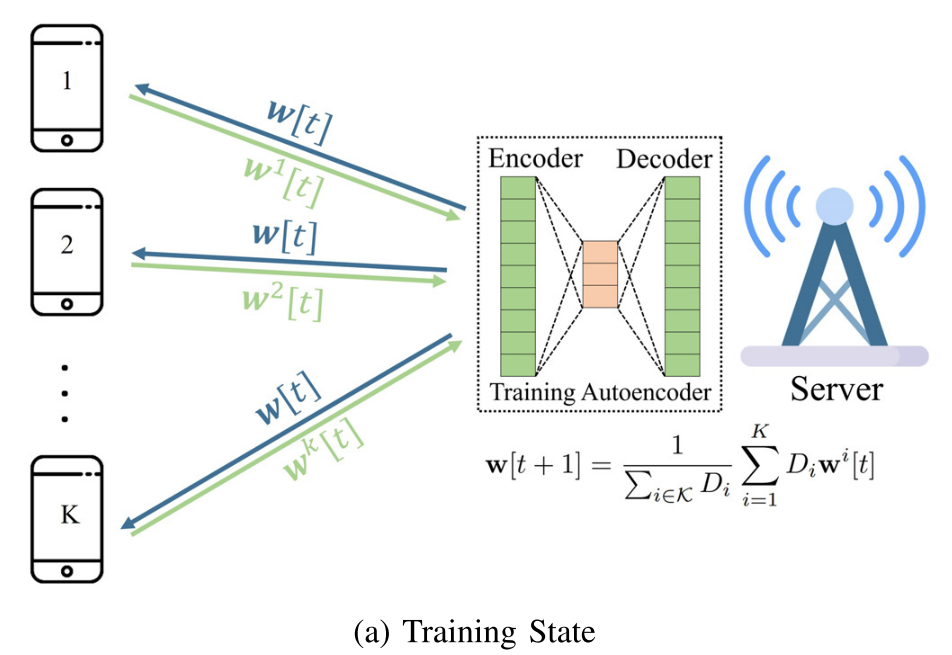
1. 在训练阶段,训练自动编码器以在服务器端对用户的模型进行编码(encode)和解码(decode)。
2. 在压缩阶段,将自动编码器发送给用户,用户通过自动编码器中的编码器压缩本地模型。服务器在利用解码器来解码用户压缩过的局部模型。以额外的计算成本为代价。
3. 为了保证FL的收敛,FLAC通过在训练状态和压缩状态之间切换来动态地控制自动编码器误差,以及,基于FL系统的误差容忍(error tolerance)(由学习率来确定)来调整其压缩率。
问题:在资源受限的网络上进行FL,通信问题是FL的根本瓶颈,从而限制了ML模型的复杂度和用户的参与。
直观:降低通信成本:显著方法:梯度压缩(gradient compression),目前有:①.稀疏化(sparsification)②.量化(quantization)是预先固定的方法,没有考虑模型参数、client数据....以及训练过程中冗余信息(迭代次数.....)
一. 引言
·FL的纠错特性来自于用户使用的SGD算法是一个固有的噪声过程,SGD可以在每次迭代中补偿一些误差。
·FL的冗余信息特性是由于用户间数据的相关性,这也导致了FL的模型参数和迭代之间的相关性。

二. 相关工作
减少通信成本的四种方法:
1. 减少传输频率(reducing the frequency of transmissions):减少用户和客户端之间的通信次数,fedavg:以计算资源为代价,观察到该方法不会显著影响FL模型的收敛速度。然而,在实践中,很难选择适当的局部轮数,因为不同的模型可能会有很大的差异。
2. 稀疏化(Sparsification)
3. 量化(Quantization)
4. 模型压缩(Model Compression):知识蒸馏、dropout通用性不强,因为根据不同的模型重建的小模型不同。
三. 系统模型
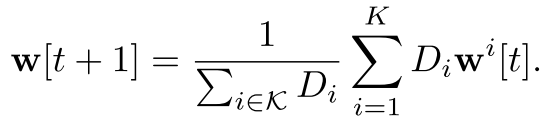
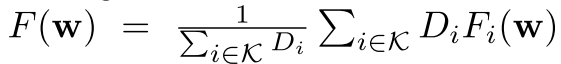
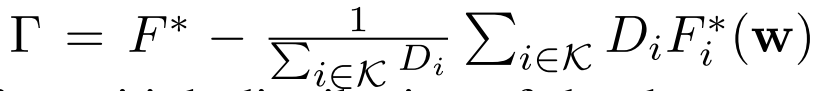
第三个公式量化non-iid程度
四. FLAC自动编码器
使用单个自动编码器来编码和学习用户本地模型的特征。自动编码器包括编码器和解码器,
编码器具体公式如下所示:
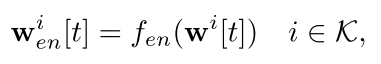
解码器具体公式如下所示:
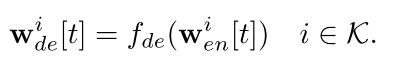
中心服务器通过解码器解码出的用户本地模型来聚合全局模型:
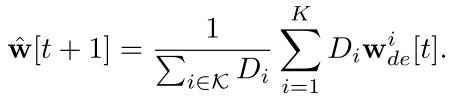
使用2范数训练自动编码器:
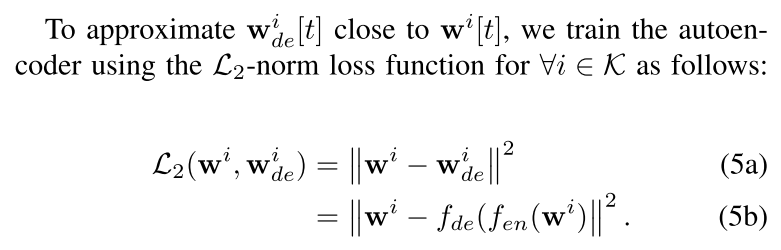
采用了一个完全连接的自动编码器(full connected autoencoder),它有一个隐藏层和一个ReLU激活函数,其大小根据全局模型大小|W|动态调整。
将压缩率称为C,其定义为:
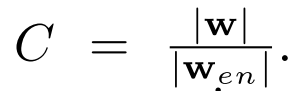
隐藏层的大小决定了压缩率,并且可以根据压缩目标动态调整。增加压缩率C会增加信息的丢失,并降低模型准确重建输入的能力。
在解码过程,可以让选择训练客户端的子集来上传他们没被压缩过的本地模型来辅助服务器能更加精确解码出被压缩过的本地模型。

训练自动编码器的时候就上传一些没被压缩的本地模型,
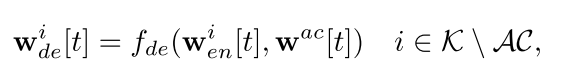

增加模型准确性
本节中描述的自动编码器压缩方法本质上是一种有损压缩方法,其误差取决于压缩率、准确用户的数量和训练过程(解决优化问题(5))。然而,FL可以容忍一些错误,由于其纠错迭代性质,因为它在每个全局轮中重新最小化全局损失函数。因此,问题是FL可以容忍多少误差,以及我们如何基于此tolerance调整压缩误差,以保证FL过程与自动编码器压缩的收敛。
误差小于用户的学习速率,并且FL可以补偿该误差。
为了计算整个FL过程中的自动编码器误差,我们考虑瞬时误差并将用户i中的误差定义如下:
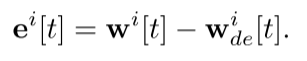
为了保证FL与自动编码器在统计上的收敛,我们需要确保自动编码器满足以下条件: