

Hierarchical Clustering-based Personalized Federated Learning for Robust and Fair Human Activity Recognition-2023
任务:人类活动识别任务Human Activity Recognition----HAR
指标:系统准确性、公平性、鲁棒性、可扩展性
方法:1. 提出一个带有层次聚类(针对鲁棒性和公平的HAR)个性化的FL框架FedCHAR;通过聚类(利用用户之间的内在相似关系)提高模型性能的准确性、公平性、鲁棒性。
2. 提高FedCHAR的可扩展性:提出FedCHAR-DC一个可扩展和自适应的FL框架——动态聚类、自适应新客户端的加入、针对现实场景不断变化的数据集。
问题:1. 用户之间的数据异构性导致不公平的模型性能,因为单个全局模型不能同时适合所有用户的数据分布。
2. FL训练过程容易受到中毒攻击,导致模型性能显著下降(拜占庭攻击)。
3. FL系统的可扩展性不足,难以适应新client的加入和数据集的变化,从而不能扩展到大规模用户训练场景。
4. 全局模型可能只学习一般特征,无法学习用户特定的特征。
公平性:1. 性能公平性:client之间具有相似的模型精度。(数据异质性导致一小部分用户的模型性能低于平均模型性能)
2. 贡献公平性:贡献度量算法(基于声誉....)。
个性化FL(针对数据异质性):聚类、FL迁移学习、元学习、FL多任务学习——大多数方法仅限于特定场景,泛化能力较差。
一. 引言
Ⅰ. 针对性能公平性:
现有方法:为性能低的用户分配更大的权重。
问题:如果恶意节点上传的中毒模型被错误分配了更大的权重,对FL训练过程产生负面影响。
Ⅱ. 针对鲁棒性:
现有方法:通过鲁棒聚合算法——会过滤掉有价值的信息——产生性能的不公平性。
两个关键观察:
1. 通过聚类来减少不同用户之间的干扰。
2. 不同的用户数据分布导致不同的用户模型参数的更新方向。——通过计算用户模型参数更新方向的余弦相似度来度量用户间的相似度。
此外:恶意节点上传的模型参数往往与良心用户不同。
——层级聚类:创建一个层次的集群(自适应)
1. 使具有相似数据分布的多个用户能够共享模型参数。
2. 抵抗对模型聚合的恶意攻击(标签翻转、模型中毒攻击)
二. 相关工作
Ditto:仅对有限类型的攻击具有鲁棒性,并且对内积操纵攻击的鲁棒性较差。
[50]搭便车攻击:操纵用户设备上传从均匀分布中随机抽取的梯度。
三. 动机
1. 用户之间数据分布的内在相似性。
2. 用户模型之间优化路径的差异。数据越多,batch越多,朝目标精度走的步数越多。
此外,在经典的FedAvg算法中,具有大量样本的用户将在全局模型聚合中被分配更大的权重。权值越大,全局模型的更新方向越受其支配,这将不利于样本量较小的用户参与协同训练。他们最终模型的准确性远低于平均水平,甚至比本地训练更差,导致用户之间的模型性能不公平。
图2的左侧示出了不同用户在每个通信回合中的模型参数的优化方向。我们可以注意到,随着通信轮数的增加,不同集群中用户的模型参数的更新方向会变得越来越相反(即,不同簇中的两个用户的模型更新参数的余弦值将从正变为负)。
四. 系统概述
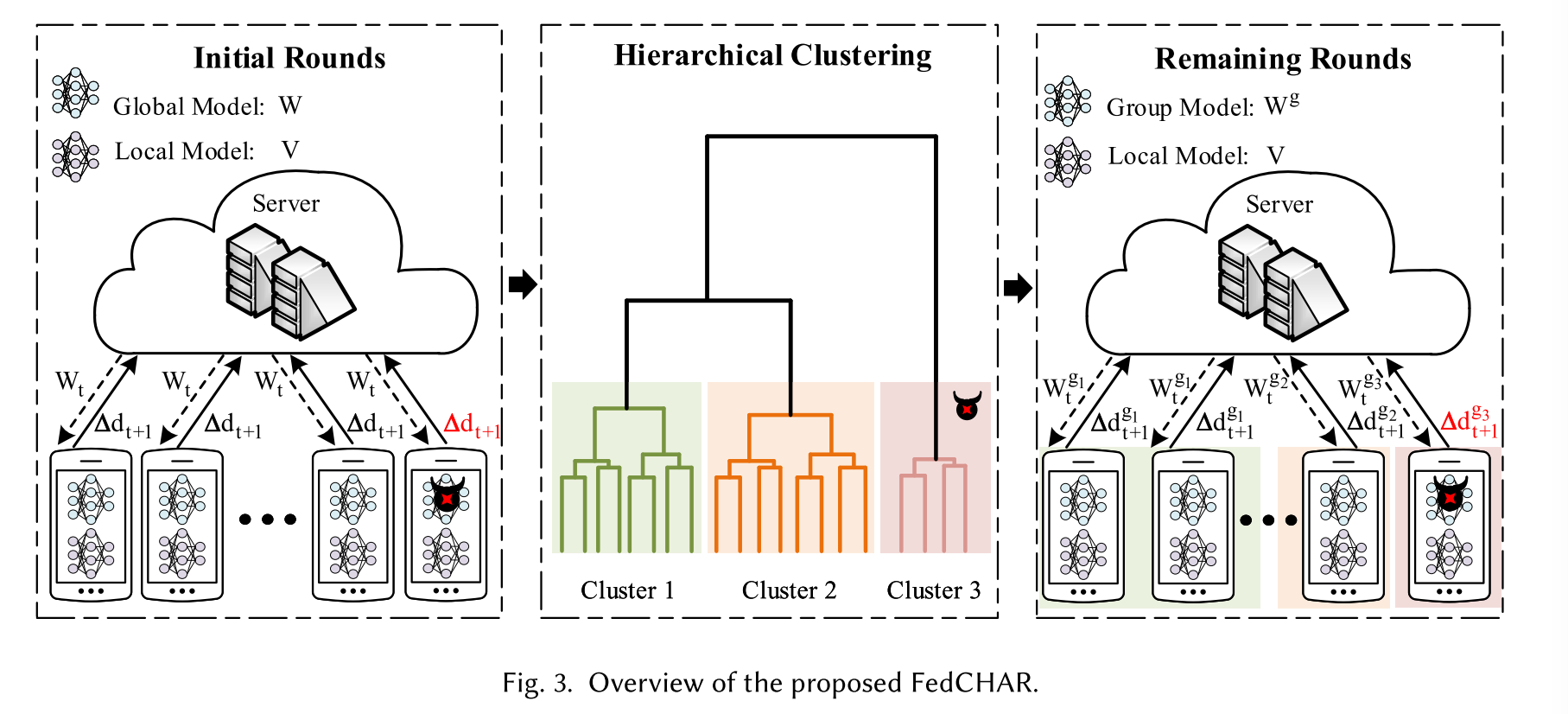
将通信轮次分为三个阶段,包括初始通信轮次、分簇阶段和分簇后的剩余通信轮次。
在FedCHAR框架中,每个用户每轮需要交替训练两个模型。一种是用户个性化模型,另一种是首轮或剩余轮对应的全局模型或分组模型。
1. 最初的几轮包括三个步骤:首先,随机选择的用户将模型更新上载到服务器。其次,服务器对用户上传的模型更新进行聚合。最后,服务器将更新后的全局模型发送给用户。
2. 在初始通信轮次后,服务器通过计算用户模型更新参数之间的余弦相似度来对用户进行聚类,该相似度反映了用户之间数据分布的相似性。服务器根据聚类结果聚合同一簇内用户的模型更新参数,然后将分组模型发送给对应的用户。
3. 在集群之后,只有同一集群中的用户可以在剩余的通信轮次中共享参数。此外,为了适应用户活动的动态变化,可以使用最近收集的数据周期性地(例如,每天)重复集群阶段。
五. 系统模型
Ⅰ. 定义
鲁棒性:1. 标签中毒攻击A1;2. 模型中毒攻击A2,A3,A4。 攻击率:20%,50%(探索抵抗攻击的能力的上限)
A1:随机标签翻转攻击;A2:添加高斯噪声;A3:模型替换攻击(默认放大10倍);A4:内积操作(恶意节点将模型更新参数的倒数上传到服务器,使得错误聚合模型更新,并且与正确模型更新之间的内积为负,从而使全局模型的优化路径偏离正确的优化路径)
公平性:在FL设置中,公平性的定义通常与用户之间的非IID数据、客户端选择和模型异构性等特征相关。
当用户样本数量不一致时,样本数量多的用户对全局模型的训练会有更多的贡献或偏移,导致全局模型的更新由样本数量多的用户主导。针对HAR中用户数据的异构性,通过FL训练得到的全局模型可以很好地拟合某些具有共同特征的用户数据,这体现在用户模型的高精度上。然而,全局模型并不适合其他用户的数据(具有更多独特特征),并且用户模型的准确性低于平均值,甚至比局部训练更差。
指标:通过计算良性client之间准确性的方差来衡量公平性。
Ⅱ. 问题公式化
non-iid:1. 特征分布偏斜:p(x)不同,即使p(y|x)相同;
2. 标签分布偏斜:p(y)不同,即使p(x|y)相同;
3. 概念漂移:p(x|y)不同,即使p(y)相同;
4. 观念转变:p(y|x)不同,即使p(x)相同;
5. 数量偏斜
Ⅲ. FedCHAR目标
受FL多任务学习的启发:提出了一种层次聚类的个性化FL框架。
在每个集群中考虑两个任务:
①. 优化分组的目标(分组的聚合函数)来更新分组聚合模型。
②. 优化局部目标函数,更新用户个性化模型。
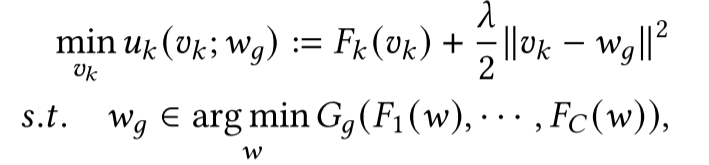
正则化系数控制个性化模型与分组聚合模型之间的距离:体现个性化程度。正则化系数越大,个性化程度越小。
Ⅳ. 求解FedCHAR目标的算法

层次聚类(Agglomerate clustering)
聚合聚类是一种分层聚类算法,迭代地合并类似的聚类以形成更大的聚类,该算法从每个对象的单独聚类(叶节点)开始,然后在每一步将两个相似的聚类合并。
层次:某种距离定义(本文:余弦相似度)。目的:消除类别的数量。树状图。
常用的距离度量是 "cosine distance",它等于 1 减去余弦相似度。因此,余弦相似度越大,对应的余弦距离越小,表示两个簇越相似。
连接函数(linkage function):将样本进行分组形成层次聚类数,距离相近的样本会链接在一起。
需要决定在什么地方将层次聚类树截断成多个聚类。
参数:1. linkage:

2. n_clusters:整数类型,指定簇的数量。
3. affinity:字符串或者可调用对象,用于计算距离。'euclidean'(欧式距离) 'l1' 'l2' 'manhattan' 'cosine'(余弦距离) 'precomputed' 'cityblock'(曼哈顿距离)
Ⅵ. FedCHAR-DC
FL系统的可扩展性和自适应性:动态聚类和适应新用户的加入或客户端数据的变化,对FedCHAR的聚类和第三阶段进行优化,第一阶段初始训练不变。

·聚类阶段:与FedCHAR(|K|都参与聚类)的不同是选择用户的一个子集(|Kt|)来参与聚类
·剩余阶段:首先初始化一个长度为K且值为0的state数组,用来记录client为被选择的轮次(has not been selected in a row),其次在每一轮开始,中心服务器首先确定client是否已经具有其所属的集群,(如果已经属于某个集群)并且确定该client不参与训练的连续轮次小于R——则认为该client属于之前的集群(the previous cluster)。服务器将分组模型(the grouping model)Wgt分发给属于该集群的client(满足前面两个条件)。
若是不满足这两个条件,中心服务器触发新用户机制来确定用户所属的集群,连续轮次的值决定服务器是否为client重新分配所属的集群。
Ⅶ. 新用户机制
首先,服务器将初始轮次得到的全局模型Wt0分发给新用户k,计算初始平均分组模型更新值的余弦相似度值,获得最小余弦值min,可以作为阈值来决定是否应该将用户分配到已存在的集群。然后再获与初始平均分组模型计算余弦,得最大余弦值max。
如果,max大于等于min,则服务器将分组模型分发给新用户k,并更新聚类结构。如果max<min,服务器为该新用户分配一个新的集群,更新集群结构,将初始轮次得到的全局模型分发给该用户作为该新集群的初始化分组模型,.....
总结:
1. 都是基于明文梯度值计算余弦值。
2. 不能保证贡献公平性。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?