
记一次hadoop伪分布式环境搭建(Linux)
1、准备工作
1.1 给虚拟机取个 hostname。 而且配置 hosts。如果要和win做联合开发的话,和win的hosts文件,做一样的域名映射。
# 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
# ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.241.128 master
1.2 做免密配置
[root@master opt]# ssh-keygen -t rsa
[root@master opt]# ssh-copy-id -i ~/.ssh/id_rsa.pub root@master
[root@master opt]# ssh root@master
1.3 安装 dk
vim /etc/profile
export JAVA_HOME=/usr/local/java/jdk1.8.0_221
export CLASSPATH=.:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar
export PATH=$JAVA_HOME/bin:$PATH
2、hadoop
配置文件
hadoop-env.sh
export JAVA_HOME=/usr/local/java/jdk1.8.0_221
core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-2.7.7/tmp</value>
</property>
hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
maper-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
yarn-site.xml
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
环境变量
export HADOOP_HOME=/opt/hadoop-2.7.7
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
格式化namenode。一旦格式化后,不能重复格式化。
[root@master ~]# hdfs namenode -format
启动
start-all.sh
[root@master ~]# start-all.sh This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh Starting namenodes on [master] master: starting namenode, logging to /opt/hadoop-2.7.7/logs/hadoop-root-namenode-master.out localhost: starting datanode, logging to /opt/hadoop-2.7.7/logs/hadoop-root-datanode-master.out Starting secondary namenodes [0.0.0.0] 0.0.0.0: starting secondarynamenode, logging to /opt/hadoop-2.7.7/logs/hadoop-root-secondarynamenode-master.out starting yarn daemons starting resourcemanager, logging to /opt/hadoop-2.7.7/logs/yarn-root-resourcemanager-master.out localhost: starting nodemanager, logging to /opt/hadoop-2.7.7/logs/yarn-root-nodemanager-master.out [root@master ~]# jps 4081 DataNode 4853 Jps 4728 NodeManager 4409 ResourceManager 3947 NameNode 4252 SecondaryNameNode
验证
http://master:50070/ , 这是 hdfs(hadoop)的 web页面。

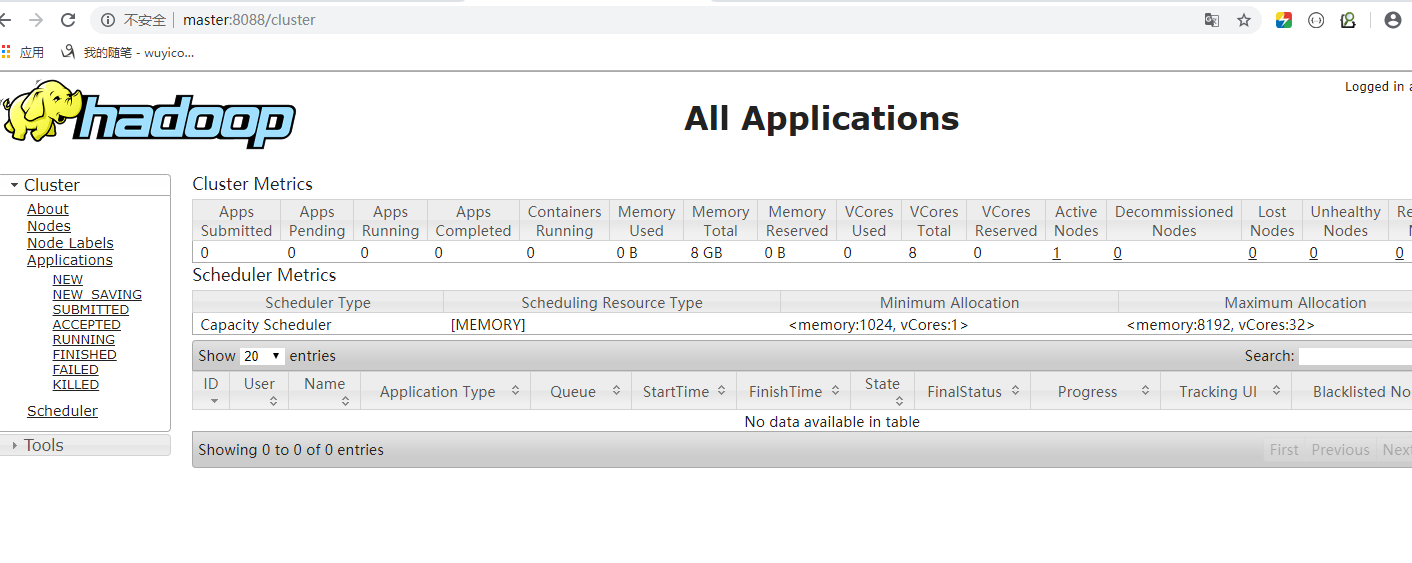
http://master:8088/ , 是yarn 资源调度的web页面。
开启 历史服务器
yarn.site.xml
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
maper-site.xml
<!-- 设置jobhistoryserver 没有配置的话 history入口不可用 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<!-- 配置web端口 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
<!-- 配置正在运行中的日志在hdfs上的存放路径 -->
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>/history/done_intermediate</value>
</property>
<!-- 配置运行过的日志存放在hdfs上的存放路径 -->
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>/history/done</value>
</property>
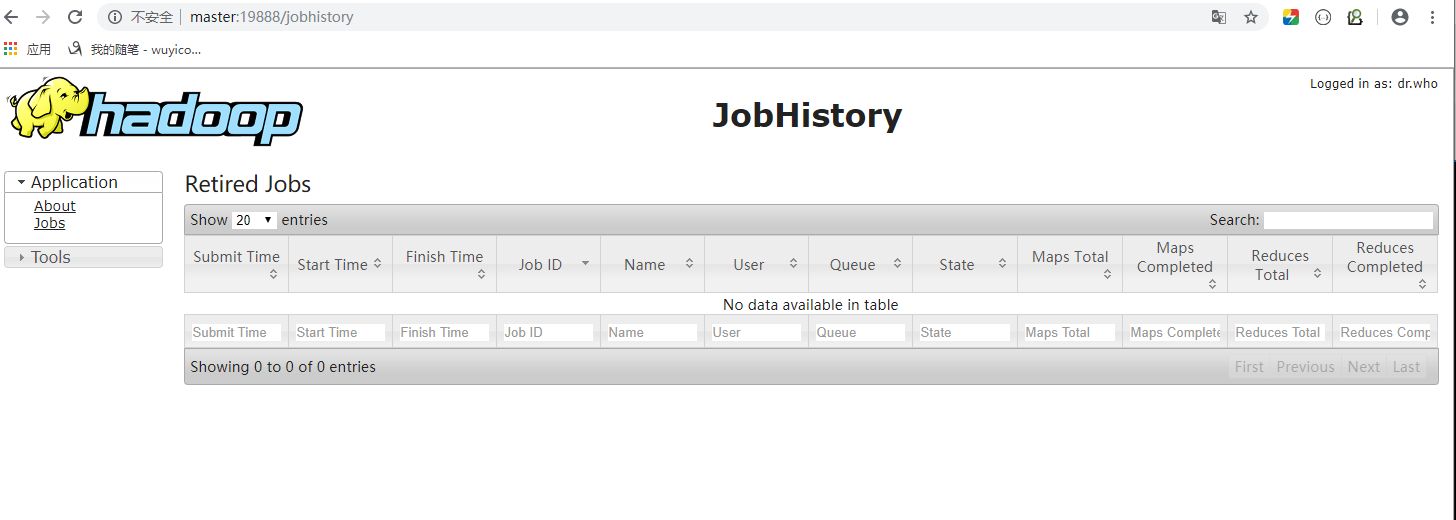
启动 , mr-jobhistory-daemon.sh start historyserver , 网页端口号是 19888
参考 https://blog.csdn.net/xiaoduan_/article/details/79689882
3、Hbase
配置文件
hbase-env.sh
export JAVA_HOME=/usr/local/java/jdk1.8.0_221
export HBASE_MANAGES_ZK=false
我这里使用,自己安装的 zookeeper , 不用hbase自带的 zk。
hbase-site.xml
<property>
<name>hbase.rootdir</name>
<value>hdfs://master:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>master:2181</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/opt/zookeeper-3.4.5/tmp</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
regionservers, 写上主机名 hostname 。
master
启动
先启动 zookeeper 。
root@master bin]# ./zkServer.sh start JMX enabled by default Using config: /opt/zookeeper-3.4.5/bin/../conf/zoo.cfg Starting zookeeper ... STARTED
[root@master bin]# ./zkServer.sh status
JMX enabled by default
Using config: /opt/zookeeper-3.4.5/bin/../conf/zoo.cfg
Mode: standalone
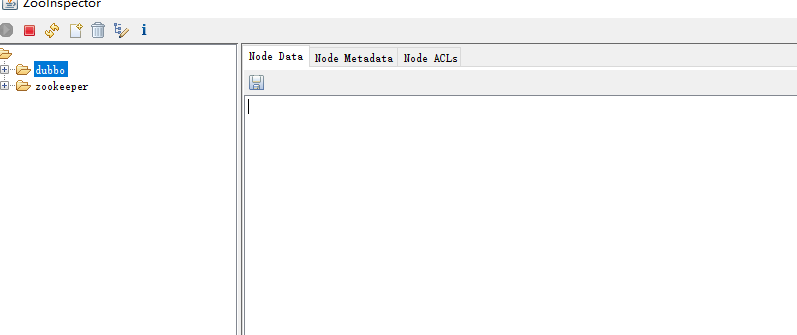
使用工具 ZooInspector 连接看看。 连接成功, 这里的 dubbo,是我之前做 dubbo服务的注册 , 和hbase 没关系,忽略即可。
设置环境变量
export HBASE_HOME=/opt/hbase-2.0.0
export PATH=$HBASE_HOME/bin:$PATH
web端口是 16010
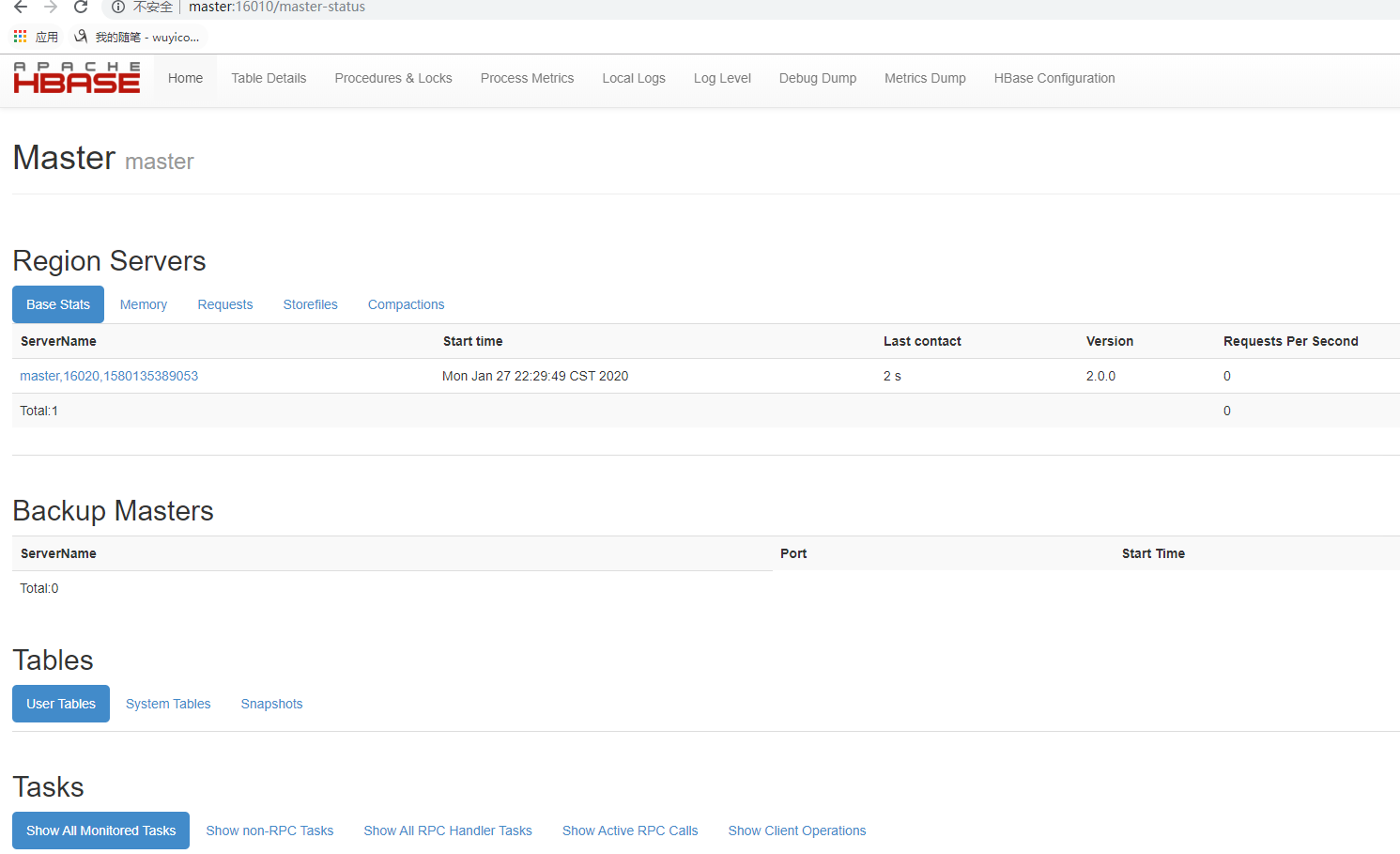
4、Hive
首先要安装mysql。
创建一个新的数据库:create database hive;
这个数据库hive,存放的是 hive的元数据。
为了hive,新建一个用户。
创建一个新的用户:
create user 'hiveowner'@'%' identified by 'Welcome_1';
给该用户授权
grant all on hive.* TO 'hiveowner'@'%'; grant all on hive.* TO 'hiveowner'@'localhost' identified by 'Welcome_1';
接下来,修改hive的配置文件。
# Set HADOOP_HOME to point to a specific hadoop install directory
HADOOP_HOME=/opt/hadoop-2.7.7
# Hive Configuration Directory can be controlled by:
export HIVE_CONF_DIR=/opt/hive-2.3/conf
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hiveowner</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>Welcome_1</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://bigdata112:3306/hive?createDatabaseIfNotExist=true&useSSL=false</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>datanucleus.schema.autoCreateAll</name>
<value>true</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>bigdata112</value>
</property>
</configuration>
[root@bigdata112 hive-2.3]# ./bin/schematool -dbType mysql -initSchema
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/hive-2.3/lib/log4j-slf4j-impl-2.6.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/hadoop-2.7.7/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Metastore connection URL: jdbc:mysql://bigdata112:3306/hive?createDatabaseIfNotExist=true&useSSL=false
Metastore Connection Driver : com.mysql.jdbc.Driver
Metastore connection User: root
Starting metastore schema initialization to 2.3.0
Initialization script hive-schema-2.3.0.mysql.sql
Initialization script completed
schemaTool completed
添加环境变量
# hive
export HIVE_HOME=/opt/hive-2.3
export PATH=$HIVE_HOME/bin:$PATH
export HADOOP_CLASSPATH=$HIVE_HOME/lib/*:$CLASSPATH
测试看看。创建表。
[root@bigdata112 hive-2.3]# ./bin/hive
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/hive-2.3/lib/log4j-slf4j-impl-2.6.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/hadoop-2.7.7/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Logging initialized using configuration in jar:file:/opt/hive-2.3/lib/hive-common-2.3.0.jar!/hive-log4j2.properties Async: true
Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
hive> create table student(sid int, sname string);
OK
Time taken: 6.304 seconds
hive>
试试启动hiveserver2,用beeline连接。
给hadoop的配置文件 core-site.xml添加内容。
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
重启hadoop。并且 把 hadoop存文件的目录,开放所有权限。
[root@bigdata112 hadoop-2.7.7]# chmod -R 777 ./tmp/
[root@bigdata112 hive-2.3]# ./bin/hiveserver2 &
[root@bigdata112 hive-2.3]# jps
1570 DataNode
2514 Jps
2010 NodeManager
1436 NameNode
2332 RunJar
1741 SecondaryNameNode
1902 ResourceManager
[root@bigdata112 hive-2.3]# ./bin/beeline
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/hive-2.3/lib/log4j-slf4j-impl-2.6.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/hadoop-2.7.7/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Beeline version 2.3.0 by Apache Hive
beeline> !connect jdbc:hive2://bigdata112:10000/
Connecting to jdbc:hive2://bigdata112:10000/
Enter username for jdbc:hive2://bigdata112:10000/: hiveowner
Enter password for jdbc:hive2://bigdata112:10000/: *********
Connected to: Apache Hive (version 2.3.0)
Driver: Hive JDBC (version 2.3.0)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://bigdata112:10000/>
连接成功。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号