Hadoop——基础练习题
一、Wordcount练习
1.需求:通过hadoop分析文件中单词总数
1.要被分析的文件内容如图所示,每个单词之间以空格分开
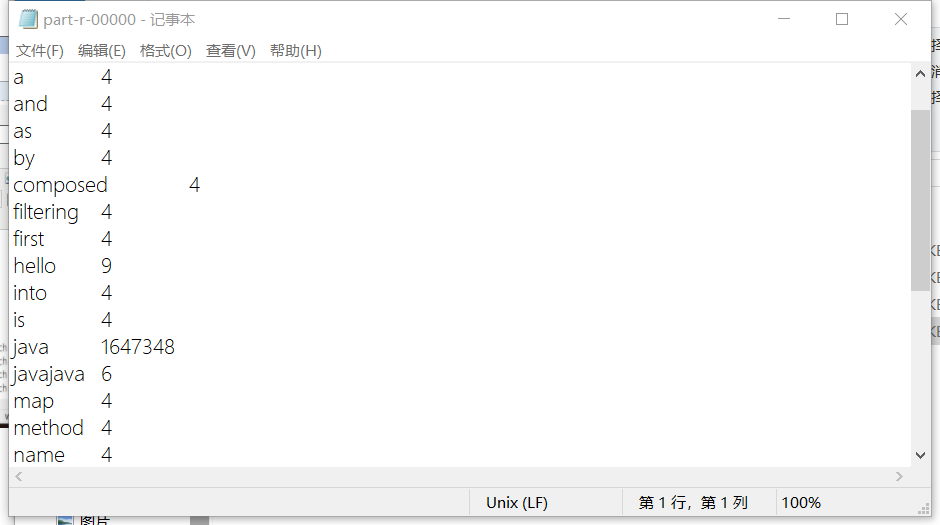
2.实现的效果如图
2.代码实现
1.解决数据倾斜问题
考虑到在机器运行过程中 Reduce阶段每个相同的Key会由一个ReduceTask来处理,而java共有十六万个,其他的单词只有几个,分出的ReduceTask处理少的单词很快就完成,但是处理的java的单词会用一些时间才处理完,这就造成了严重的数据倾斜的状况,所以在这种情况下应该创建多个分区,将整个数据分到不同的分区中, 然后分区中在处理的java单词数量就会大大减少工作时间,然后将各个分区的统计在相加得出最终结果.具体实现看代码
2.编写代码
package com.wxw.superwc; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Partitioner; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; import java.util.Random; /*在Hadoop中想要实现数据整合就必须有类去继承 Mapper 和 Reduce 这两个类 Map主要用于数据的拆分后 以键值对的形式向Reduce输出 在继承Mapper中 需要填入泛型约束他的参数类型 Mapper<LongWritable, Text,Text, IntWritable> 第一个参数类型 只能为LongWritable表示读入文件的偏移量 这个偏移量是读入行的Key 第二个参数类型 表示传进来的每一行数据 这一行数据内容是读入文件的值 第三个参数类型 表示出入的Key的类型 第四个参数类型 标书输出的Value的类型 继承Mapper后需要重写方法 map(LongWritable key, Text value, Context context) map方法中的参数为Mapper的前两个参数类型 context表示上下文 输出给Reduce 在文件读出的每一行都要去调用一次map方法 Reduce主要用于数据的计算 计算的类继承Reduce后需要填入他的泛型 Reduce<Text,IntWritable,Text,IntWritable> 表示<从Mapper接受他输出Key的类型,从Mapper接受的value的数据类型,从Reduce输出到文件Key的类型,从Reduce输出到文件Value的类型> 重写reduce方法reduce(Text key, Iterable<IntWritable> values, Context context) 在Reduce是处理的相同键不同值的value结合 创建继承分区Partitioner的类 并重写方法 getPartition(Text text, IntWritable intWritable, int i) 三个参数表示从Mapper接受的键和值的类型及在主程序中设置的分区个数的值 */ public class SuperWc { public static class SupWcMa extends Mapper<LongWritable, Text,Text, IntWritable>{//编写继承Mapper的类用于拆分 //重写map方法 @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String[] s = value.toString().split(" ");//将读取到的每一行数据按照空格拆分成数组 for (String name ://利用循环 让每一单词作为键值为1去输出 s) { context.write(new Text(name),new IntWritable(1)); } } } public static class SpuWcRe extends Reducer<Text,IntWritable,Text,IntWritable>{//编写继承Reduce的类实现计算 //重写reduce方法 @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum=0;//生成一个计数器 for (IntWritable writable :values//遍历得相同键的值的集合 得到他们的值并通过sum计数统计出数量 ) { sum+=writable.get(); } context.write(key,new IntWritable(sum)); } } public static class fenqu extends Partitioner<Text,IntWritable> {//编写一个分区类 这个类在Mapper之后 Reduce之前运行 //重写分区的方法 @Override public int getPartition(Text text, IntWritable intWritable, int i) { Random random = new Random(); return random.nextInt(i);//在主程序中已经设好分区的个数为5 然后随机的将map得来的值分到不同的区中,减少数据倾斜的弊端 } } public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { //添加驱动 Configuration configuration = new Configuration();//声明驱动类 Job job = Job.getInstance(configuration);//声明配置类 job.setMapperClass(SupWcMa.class);//设置运行Mapper的类 job.setReducerClass(SpuWcRe.class);//设置运行Reduce的类 job.setJarByClass(SuperWc.class);//设置在Linux的运行Jar包的类 一般为程序的主类 //设置分区 job.setPartitionerClass(fenqu.class);//加载 写好的分区类 job.setNumReduceTasks(5);//设置分区的个数 这个个数是设置分区随机数传的参 //设置Mapper类输入出类型参数 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); //设置Reduce的输出类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); //设置文件读取的路径 最好是绝对值 FileInputFormat.setInputPaths(job,new Path("E:\\wordcountdemo\\superWc\\input")); //加载驱动 FileSystem fs = FileSystem.get(configuration); //设置输出路径 Path outPath = new Path("E:\\wordcountdemo\\superWc\\output"); if (fs.exists(outPath)){ fs.delete(outPath,true); } FileOutputFormat.setOutputPath(job,outPath); //提交文件 job.submit(); } }
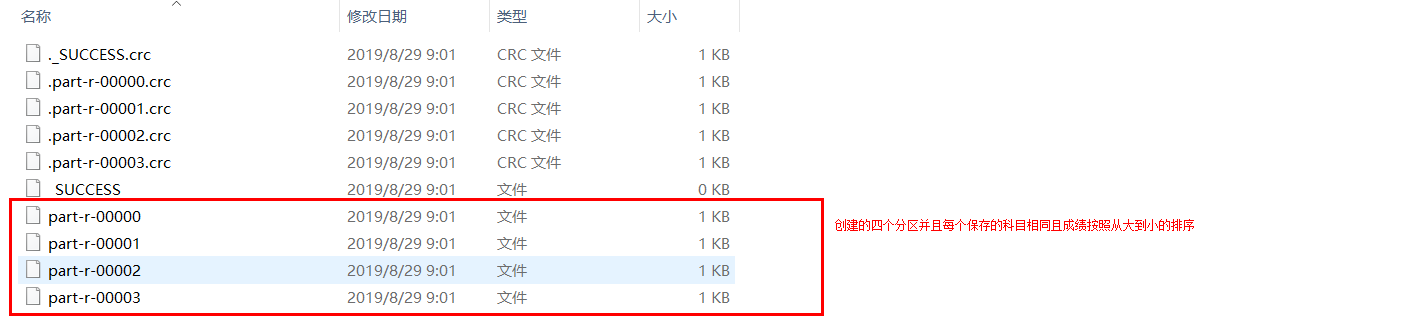
每个分区会生成一个文件结果如下
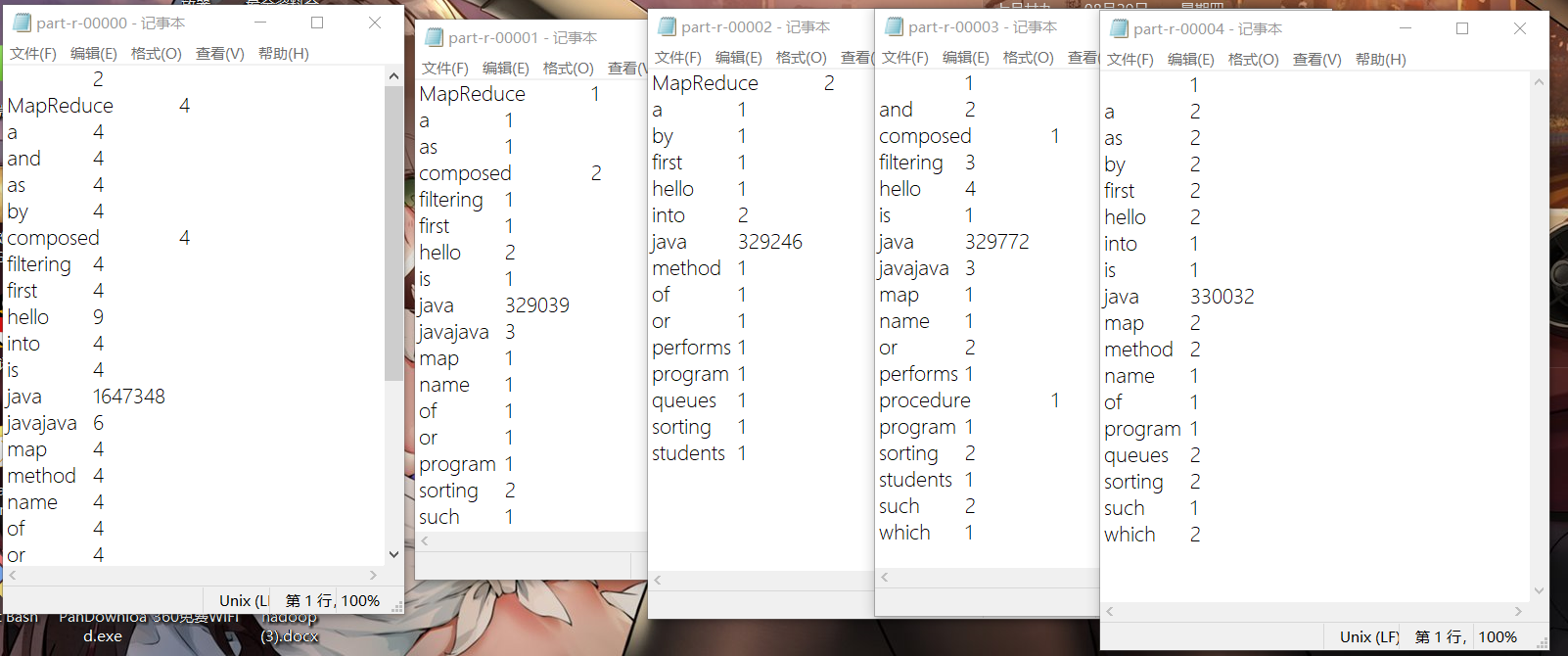
再次编写代码整合每个分区的文件
package com.wxw.superwc; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; public class SuperWC2 { public static class SupWcMa extends Mapper<LongWritable, Text,Text, IntWritable> { @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //分割读取的文件 String[] s = value.toString().split("\t"); //输出得到文件的内容 context.write(new Text(s[0]),new IntWritable(Integer.valueOf(s[1]))); } } public static class SpuWcRe extends Reducer<Text,IntWritable,Text,IntWritable> { @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { //将相同键的值相加 int sum=0; for (IntWritable writable :values ) { sum+=writable.get(); } context.write(key,new IntWritable(sum)); } } public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { //添加驱动 Configuration configuration = new Configuration(); Job job = Job.getInstance(configuration); job.setMapperClass(SupWcMa.class); job.setReducerClass(SpuWcRe.class); job.setJarByClass(SuperWC2.class); //设置输入出 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); //设置文件加载 FileInputFormat.setInputPaths(job,new Path("E:\\wordcountdemo\\superWc\\output\\part*")); FileSystem fs = FileSystem.get(configuration); //设置输出路径 Path outPath = new Path("E:\\wordcountdemo\\superWc\\output2"); if (fs.exists(outPath)){ fs.delete(outPath,true); } FileOutputFormat.setOutputPath(job,outPath); job.submit(); } }
最终结果为
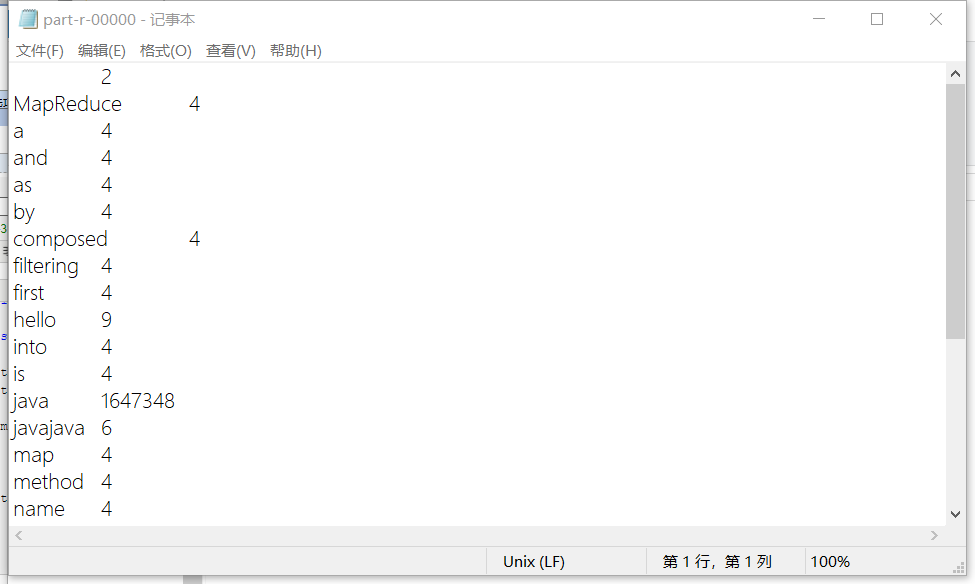
二、共同好友问题

1.先求出谁都有A的好友
package com.wxw; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; public class friend { //处理map public static class FDMapper extends Mapper<LongWritable, Text,Text,Text>{ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { if (key.get()!=0){ String fridens[]=value.toString().split(":"); String user=fridens[0]; String friendss[]=fridens[1].split(","); System.out.println(111); for (String f :friendss){ context.write(new Text(f),new Text(user)); System.out.println(f); } } } } //处理reduce public static class FDReduce extends Reducer<Text,Text,Text,Text>{ @Override protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException { StringBuffer stringBuffer=new StringBuffer(); for (Text item : values) { stringBuffer.append(item).append(","); } context.write(key,new Text(stringBuffer.toString())); System.out.println(stringBuffer); } } //添加主程序 public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Configuration conf = new Configuration(); Job job = Job.getInstance(conf); job.setJarByClass(friend.class); job.setMapperClass(FDMapper.class); job.setReducerClass(FDReduce.class); //指定map和reduce输出数据的类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(Text.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class); FileInputFormat.setInputPaths(job,new Path("E:\\wordcountdemo\\friend\\input")); FileSystem fs = FileSystem.get(conf); Path outPath = new Path("E:\\wordcountdemo\\friend\\output"); if (fs.exists(outPath)){ fs.delete(outPath,true); } FileOutputFormat.setOutputPath(job,outPath); job.submit(); } }
效果如下
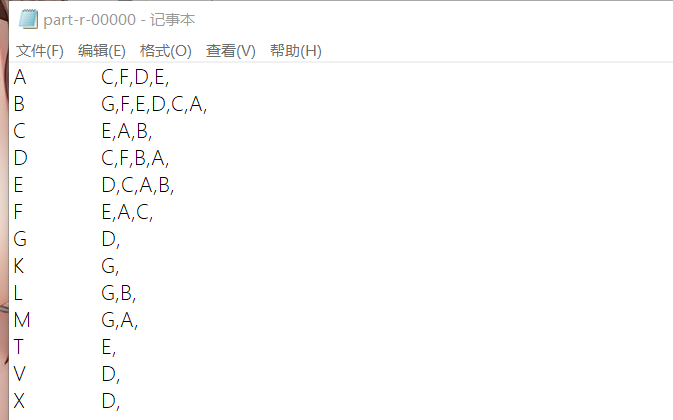
2.将得出的结果再次遍历 产看两两结果的交集
package com.wxw; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; import java.util.Arrays; public class friend2 { public static class Fd2Mapper extends Mapper<LongWritable, Text,Text,Text>{ protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String user=value.toString().split("\t")[0]; String[] aa =value.toString().split("\t")[1].split(","); Arrays.sort(aa); for (int i=0;i<aa.length-1;i++) { for (int j=i+1;j<aa.length;j++){ context.write(new Text(aa[i]+"-"+aa[j]),new Text(user)); } } } } public static class FD2Reduce extends Reducer<Text,Text,Text,Text>{ @Override protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException { StringBuffer stringBuffer=new StringBuffer(); for (Text te:values ) { stringBuffer.append(te).append(","); } context.write(key,new Text(stringBuffer.toString())); } } public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Configuration conf = new Configuration(); Job job = Job.getInstance(conf); job.setJarByClass(friend2.class); job.setMapperClass(Fd2Mapper.class); job.setReducerClass(FD2Reduce.class); //指定map和reduce输出数据的类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(Text.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class); FileInputFormat.setInputPaths(job,new Path("E:\\wordcountdemo\\friend\\output\\")); FileSystem fs = FileSystem.get(conf); Path outPath = new Path("E:\\wordcountdemo\\friend\\output2"); if (fs.exists(outPath)){ fs.delete(outPath,true); } FileOutputFormat.setOutputPath(job,outPath); job.submit(); } }
运行效果:
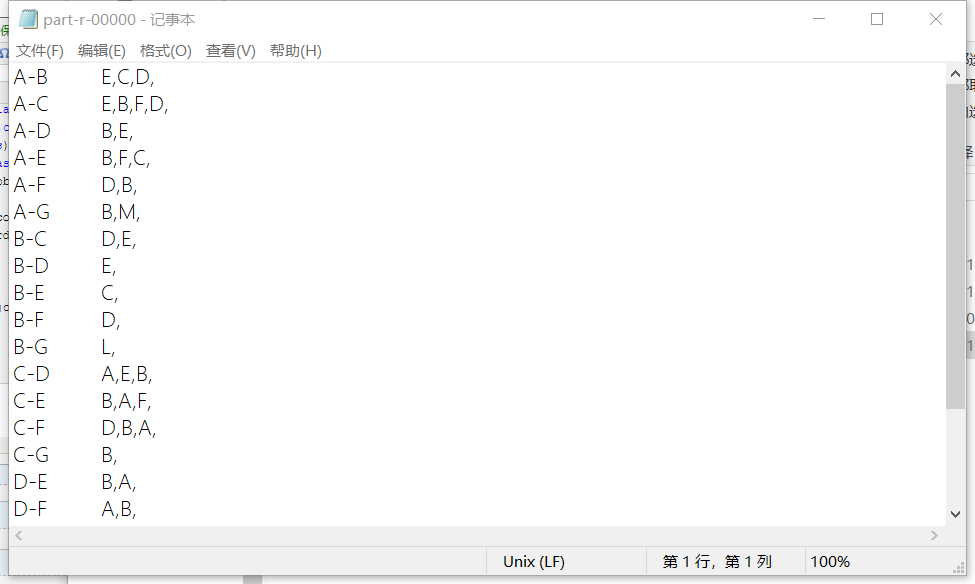
三、通过JSON文件读取并输出对象
1.将如下JSON转成对象输出

2.题意分析 :本次练习只需要读取文件并输出,因此并不需要通过Reduce计算 代码如下
创建实体类
package com.wxw.phone; import org.apache.hadoop.io.Writable; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; //想要在Mapper中出现该类需要实现Writable的类 并且 实现Writable的两个方法 public class Phone implements Writable { private String uid; private String phone; private String addr; @Override public String toString() { return "Phone{" + "uid='" + uid + '\'' + ", phone='" + phone + '\'' + ", addr='" + addr + '\'' + '}'; } public String getUid() { return uid; } public void setUid(String uid) { this.uid = uid; } public String getPhone() { return phone; } public void setPhone(String phone) { this.phone = phone; } public String getAddr() { return addr; } public void setAddr(String addr) { this.addr = addr; } @Override public void write(DataOutput dataOutput) throws IOException { dataOutput.writeUTF(this.uid); dataOutput.writeUTF(this.phone); dataOutput.writeUTF(this.addr); } @Override public void readFields(DataInput dataInput) throws IOException { this.uid=dataInput.readUTF(); this.phone=dataInput.readUTF(); this.addr=dataInput.readUTF(); } }
创建操作类
package com.wxw.phone; import org.apache.commons.lang.ObjectUtils; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.htrace.fasterxml.jackson.databind.ObjectMapper; import java.io.IOException; public class PhoneMR { //本题只是让map输出对象 因此将输出的Key设置为Phone对象 它的值为空 public static class PhoneMap extends Mapper<LongWritable, Text,Phone, NullWritable>{ //从写map @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //将读取的数据转换格式防止输出文件时出错 String line=new String(value.getBytes(),0,value.getLength(),"GBK"); //声明解析Json格式的类 ObjectMapper obj=new ObjectMapper(); //实例化要输出的对象并通过解析将数据按照对象的类型写入 Phone phone=obj.readValue(line,Phone.class); //输出 context.write(phone, NullWritable.get()); } } public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Configuration conf = new Configuration(); Job job = Job.getInstance(conf); job.setJarByClass(PhoneMR.class); job.setMapperClass(PhoneMap.class); //只需设置MAp的输出类型 job.setOutputKeyClass(Phone.class); job.setOutputValueClass(NullWritable.class); //没有reduce的操作所以就要将它的ReduceTask设置为0为了避免出错 job.setNumReduceTasks(0); FileInputFormat.setInputPaths(job,new Path("E:\\wordcountdemo\\phone\\input")); FileSystem fs = FileSystem.get(conf); Path outPath = new Path("E:\\wordcountdemo\\phone\\output"); if (fs.exists(outPath)){ fs.delete(outPath,true); } FileOutputFormat.setOutputPath(job,outPath); boolean b = job.waitForCompletion(true); System.exit(b?0:1); } }
四、两表连接
1.如果要操作两个表,那么就可以先将小的文件加载在缓存中,在Mapper操作中一起读写操作,这样就可以完成两个表的操作 如图 将两张表的数据整合到一张。

2.代码编写
package com.wxw.join; import org.apache.commons.lang.StringUtils; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.BufferedReader; import java.io.FileReader; import java.io.IOException; import java.util.HashMap; import java.util.Map; //用于两表联合 主要是将小的表加载到内存中 连接到大的数据表 public class joinmap { public static class joinMap extends Mapper<LongWritable, Text,Text, NullWritable>{ //定义集合 Map map=new HashMap<String,String>(); //次方法在本类中只执行一次 可以用于优化 @Override protected void setup(Context context) throws IOException, InterruptedException { //创建缓冲池 读取较小的文件 BufferedReader br = new BufferedReader(new FileReader("E:\\wordcountdemo\\join\\input\\gou.txt")); String line=" "; while(StringUtils.isNotBlank(line=br.readLine())){ //将读取的文件存在集合中 方便在Mapper类中调用 String[] split = line.split("\t"); map.put(split[0],split[1]); } } @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //设置字符编码 String line=new String(value.getBytes(),0,value.getLength(),"GBK"); String[] split1 =line.split("\t"); //通过if判断达到数据清洗的效果 if (split1.length>=2){ System.out.println(split1[0]+" "+split1[1]+" "+map.get(split1[0])); //直接输出 context.write(new Text(split1[0]+split1[1]+" "+map.get(split1[0])),NullWritable.get()); } } } public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { //添加配置类 Configuration conf=new Configuration(); Job job = Job.getInstance(conf); job.setJarByClass(joinmap.class); job.setMapperClass(joinMap.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(NullWritable.class); //设置分区个数 job.setNumReduceTasks(0); //设置文件读取输出配置 FileInputFormat.setInputPaths(job,new Path("E:\\wordcountdemo\\join\\input\\guc.txt")); FileSystem fs = FileSystem.get(conf); Path outPath = new Path("E:\\wordcountdemo\\join\\output"); if (fs.exists(outPath)){ fs.delete(outPath,true); } FileOutputFormat.setOutputPath(job,outPath); job.submit(); } }
五、按照某种条件分区的练习
1.根据科目分区,将学生的其平均成绩求出如图
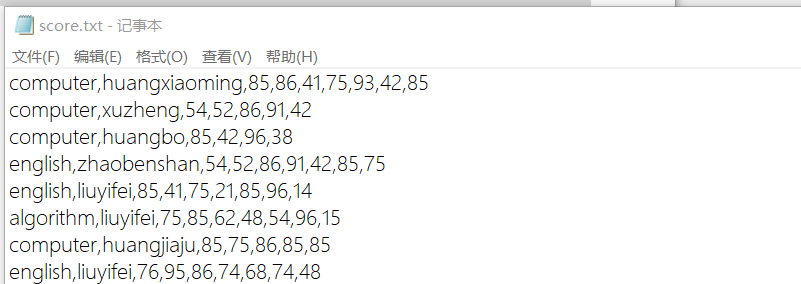
2.代码实现
创建学生类
package com.wxw.score; import org.apache.hadoop.io.WritableComparable; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; //实现WritableComparable 实现排序的方法 public class student implements WritableComparable <student> { private String name; private String subject; private double avg; public String getName() { return name; } public void setName(String name) { this.name = name; } public String getSubject() { return subject; } public void setSubject(String subject) { this.subject = subject; } public double getAvg() { return avg; } public void setAvg(double avg) { this.avg = avg; } @Override public void write(DataOutput dataOutput) throws IOException { dataOutput.writeUTF(this.name); dataOutput.writeUTF(this.subject); dataOutput.writeDouble(this.avg); } @Override public void readFields(DataInput dataInput) throws IOException { this.name=dataInput.readUTF(); this.subject=dataInput.readUTF(); this.avg=dataInput.readDouble(); } //自定义排序 @Override public int compareTo(student o) { if (o.getAvg() == this.getAvg()){ return o.getName().compareTo(this.name); }else { return o.getAvg() >this.getAvg()?1:-1; } } @Override public String toString() { return "student{" + "name='" + name + '\'' + ", subject='" + subject + '\'' + ", avg=" + avg + '}'; } }
编写代码
package com.wxw.score; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Partitioner; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; import java.util.HashMap; public class scoreTest { //创建分区的类 public static class parnt extends Partitioner<student, NullWritable> { HashMap<String, Integer> map = new HashMap<>(); @Override public int getPartition(student student,NullWritable s, int i) { //自定义一个分区的集合 根据map传过来的值并且自动分区 map.put("computer",0); map.put("english",1); map.put("algorithm",2); map.put("math",3); return map.get(student.getSubject()); } } public static class scoreMap extends Mapper<LongWritable, Text,student, NullWritable> { //map操作 @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //切分 String[] split = value.toString().split(","); //实例化总分 Double sum=0.0; //实例化科目数 int num=split.length-2; //实例化avg Double avg=0.0; //实例化学生对象 student student=new student(); student.setName(split[1]); student.setSubject(split[0]); for (int i=2;i<split.length;i++){ sum += (Double) Double.valueOf(split[i]); } avg = sum/num*1.0; student.setAvg(avg); context.write(student,NullWritable.get()); } } public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { //添加驱动 Configuration configuration = new Configuration(); Job job = Job.getInstance(configuration); job.setJarByClass(scoreTest.class); job.setMapperClass(scoreMap.class); //设置分区 job.setPartitionerClass(parnt.class); job.setNumReduceTasks(4); //设置输入出 job.setOutputKeyClass(student.class); job.setOutputValueClass(NullWritable.class); //设置文件加载 FileInputFormat.setInputPaths(job,new Path("E:\\wordcountdemo\\score\\input")); FileSystem fs = FileSystem.get(configuration); Path outPath = new Path("E:\\wordcountdemo\\score\\output"); if (fs.exists(outPath)){ fs.delete(outPath,true); } FileOutputFormat.setOutputPath(job,outPath); job.submit(); } }
实现效果