模型评价指标(混淆矩阵,AUC,ROC)
一、评价分类结果
分类算法的评价:仅仅使用分类准确度可靠吗?
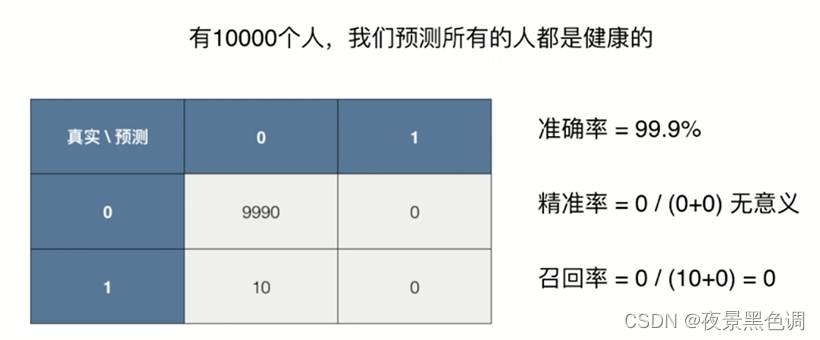
问题:有一个癌症预测系统,输入体检信息,可以判断是否有癌症。预测准确度:99.9%,是好?是坏?
假如癌症产生的概率只有0.1%,我们的系统预测所有人都是健康,即可达到99.9的准度率!
因此对于极度偏斜(Skewed Data)的数据,只是用分类准确度是远远不够的,可使用混淆矩阵做进一步分析,它可以衡量分类算法是否优秀及合理
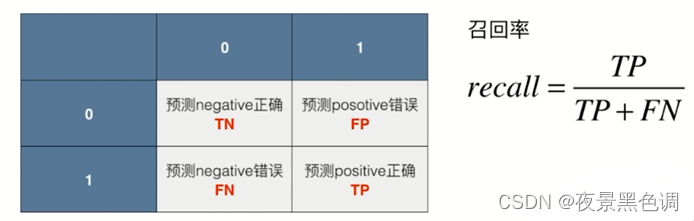
1.混淆矩阵(Confusion Matrix)
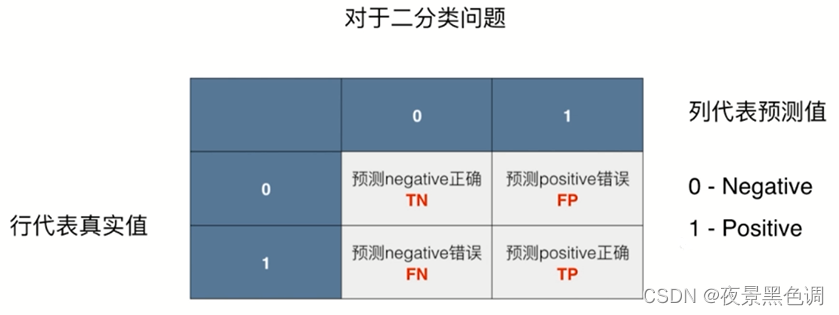
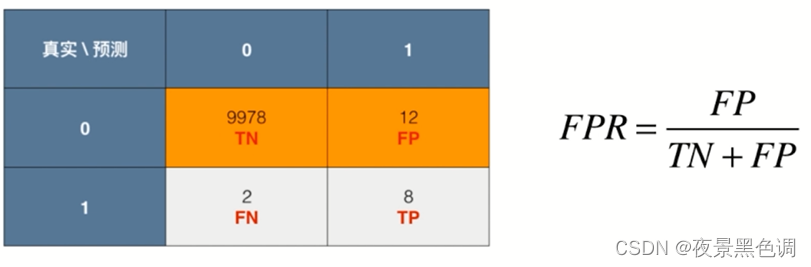
分类算法作用于一组数据如何得到混淆矩阵?针对二分类问题
行代表真实值,列代表预测值(0-Negative,1-Positive)
记忆:行相当于二维数组的第一个维度,列相当于二维数组的第二个维度,真实值要放在预测值的前面
2.精准率和召回率
正例:一般理解为研究者感兴趣或者关心的那个分类
精准率:正确的预测正例数在预测正例数中的比例
召回率:正确的预测正例数在实际正例数中的比例
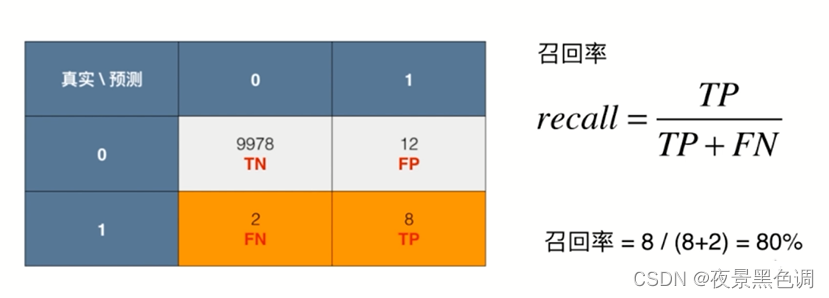
之前的问题:
3.F1 Score:二者兼顾
有时候我们注重精准率,如股票预测
我们做的未来股票会升的预测其中有多少是正确的,这时候我们不是很关心召回率( 因为召回率低意味着我们犯了FN的错误 :有多少只会升的股票我们给他预测成会降,因为即使我们预测错误了但是我们不会买);
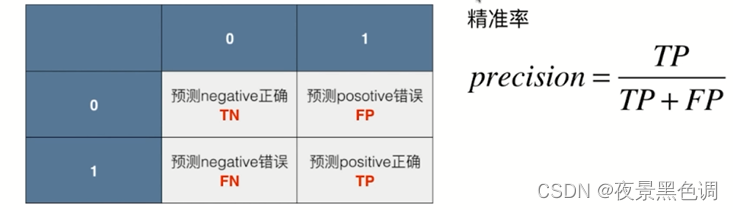
有时候我们注重召回率,如病人诊断。此时召回率低就意味着一个病人本来有病但是却被预测成没病会让病人病情恶化下去造成严重的后果,因此我们希望将所有有病的患者预测出来;此时精准率低一些没有什么关系,因为精准率低意味着我们犯了FP的错误(没病的人错误的预测为有病,让这类人进一步检查即可)
F1 Score是precision和recall的调和平均值
得到$$F1=\frac{2precisionrecall}{precision+recall}$$
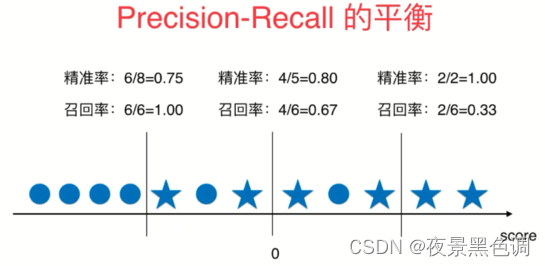
1)Precision-Recall的平衡
五角星代表1(positive),圆圈代表0(negative)
召回率:4/6=0.67(所有预测为1的样本中预测正确的概率)
2)P-R曲线(Precision-Recall Curve)
P-R曲线是描述精确率和召回率变化的曲线
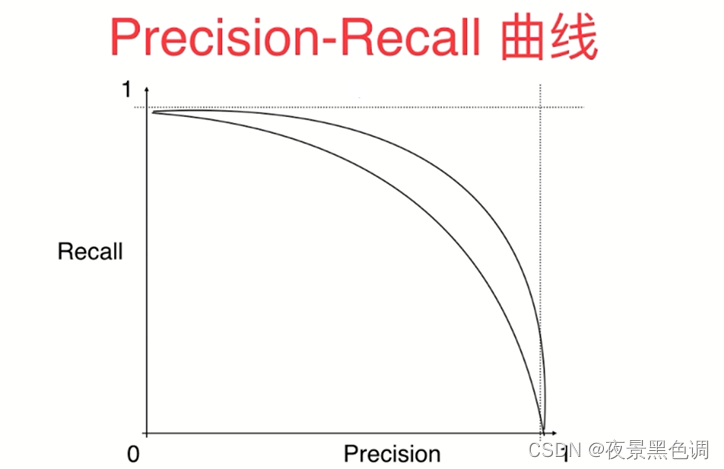
外面曲线的模型优于里面的曲线对应的模型。
4.ROC曲线
1)TPR:True Positive Rate
用TP除以真实值为1这一行所有的数字和
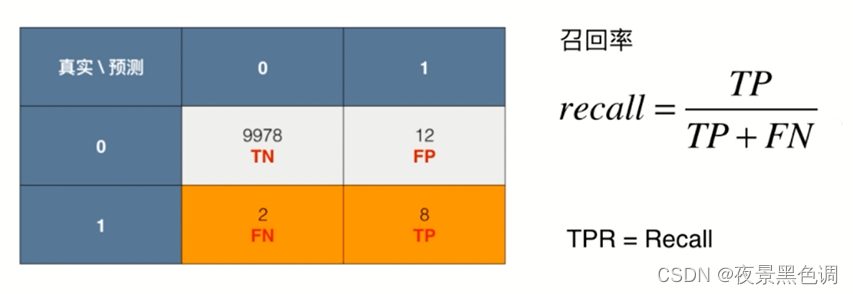
2)FPR:False Positive Rate
用FP除以真实值为0的这一行所有的数字和
3)TPR和FPR的关系
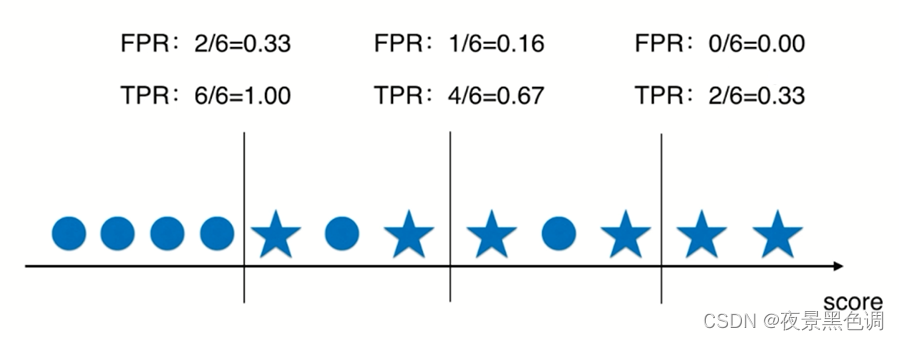
FPR是错误的预测为正的概率,TPR是正确的预测为正的概率。
FPR:错误的预测为正的数量/原本为负的数量;
TPR:正确的预测为正的数量/原本为正的数量;
逻辑回归默认以0作为基准进行分类
decision_scores=log_reg.decision_function(X_test)
4)ROC曲线
Receiver Operation Characteristic Cure,描述TRP和FPR之间的关系
from sklearn.metrics import roc_curve
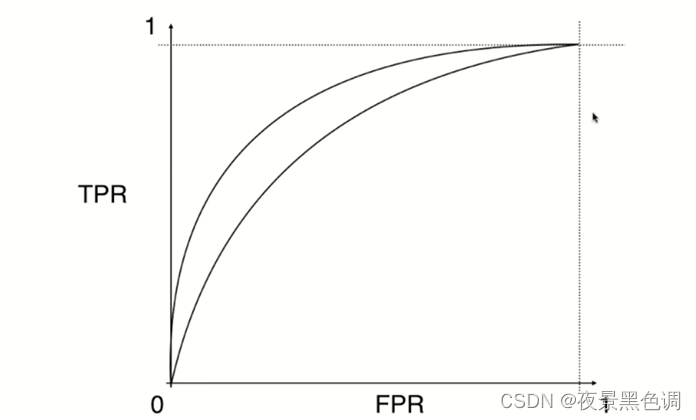
5)AUC
ROC曲线下的面积
from sklearn.metrics import roc_auc_score # 求面积
ROC和AUC应用场景:比较两个模型好坏
5.金融场景中的指标(KS,ROC,AUC)
KS:在风控中,KS常用于评估模型区分度。区分度越大,说明模型的风险排序能力(ranking ability)越强。 K-S曲线与ROC曲线类似,不同在于:
ROC曲线将真正例率和假正例率作为横纵轴;
K-S曲线将真正例率和假正例率都作为纵轴,横轴则由选定的阈值来充当。 公式如下$$KS=max(TPR-FPR)$$
KS不同代表的不同情况,一般情况KS值越大,模型的区分能力越强,但是也不是越大模型效果就越好,如果KS过大,模型可能存在异常,所以当KS值过高可能需要检查模型是否过拟合。以下为KS值对应的模型情况,但此对应不是唯一的,只代表大致趋势
| KS(%) | 好坏区分能力 |
|---|---|
| 20以下 | 不建议采用 |
| 20~40 | 较好 |
| 41~50 | 良好 |
| 51~60 | 很强 |
| 61~75 | 非常强 |
| 75以上 | 过高,疑似存在问题 |
FPR是错误的预测为正的概率,TPR是正确的预测为正的概率。
FPR:错误的预测为正的数量/原本为负的数量;
TPR:正确的预测为正的数量/原本为正的数量;
原文内容为我的CSDN博客

