模型评估方法:ROC,KS曲线
混淆矩阵:
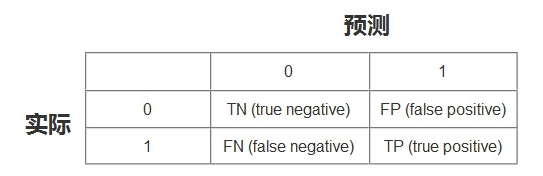
其中
- TN:将负类预测为负类(真负类)
- FN:将正类预测为负类(假负类)
- TP:将正类预测为正类(真正类)
- FP:将负类预测为正类(假正类)
准确率 (Accuracy)
测试样本中正确分类的样本数占总测试的样本数的比例。
精确率 (Precision)
准确率又叫查准率,测试样本中正确分类为正类的样本数占分类为正类样本数的比例。
召回率 (Recall)
召回率又称查全率,测试样本中正确分类为正类的样本数占实际为正类样本数的比例。
F1 值
F1 值是查准率和召回率的加权平均数。F1 相当于精确率和召回率的综合评价指标,对衡量数据更有利,更为常用。
真正类率(TPR)
预测的正类中实际正实例占所有正实例的比例。(跟召回率一样的计算公式)
负正类率(FPR)
预测的正类中实际负实例占所有负实例的比例。
KS曲线
我们训练出来的模型,一般不是直接给出是正类还是负类的结果,给的是为正类的概率,我们还需要选择一个阈值,实例通过模型得到的概率大于阈值,判断为正类,小于阈值判断为负类。也就是说阈值的不同,以上的各个指标的值也是不同的。把阈值看成自变量,以上TPR、和FPR看成因变量,在二维坐标系里面做关系曲线,这就是KS曲线。
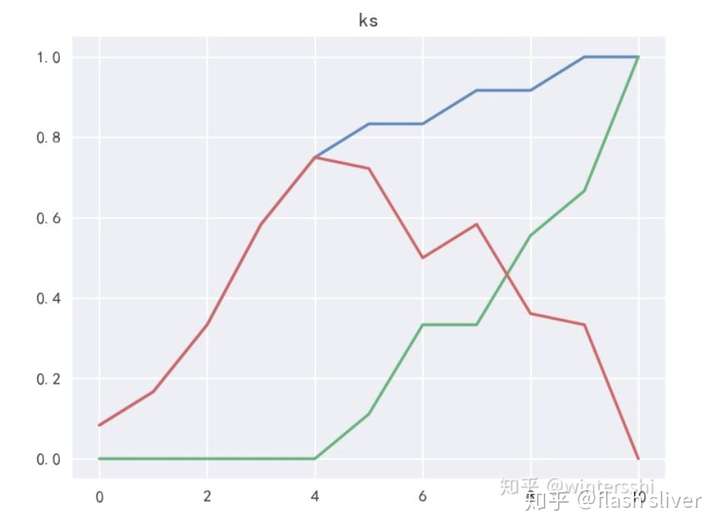 蓝色线:TPR;绿色线:FPR;红色线:TPR - FPR
蓝色线:TPR;绿色线:FPR;红色线:TPR - FPR
KS值
我们想要评估模型的能力,在阈值不同的情况下,TPR和FPR 又不一样,突然迷惘起来,这个时候,需要找到一个唯一评判标准,最值有唯一性,上图红色部分表示TPR-FPR,那我们就用最高点作为模型能力的评估标准吧!!对,没有错,最高点就是所谓的KS值,我们用KS值来作为评估模型区分能力的指标,KS值越大,模型的区分能力越强。公式如下:
ROC 曲线
ROC的全称是“受试者工作特征”(Receiver Operating Characteristic)曲线,首先是由二战中的电子工程师和雷达工程师发明的,用来侦测战场上的敌军载具(飞机、船舰),也就是信号检测理论。之后很快就被引入了心理学来进行信号的知觉检测。此后被引入机器学习领域,用来评判分类、检测结果的好坏。
还是以上的TPR和FPR值,以上我们知道了KS值能表示模型的区分能力,我们只在阈值等于KS值时,觉得模型是好的,这样忽视掉了阈值取其他值的情景,有没有一种评估标准,无关阈值的取值呢?
在实际应用场景中,模型预测了一个样本集,在预测为正类中,我们当然希望的是,预测为正类的样本中,实际也为正类样本的比例越高越好,预测为正类的样本中,实际为负类样本的比例越小越好,也就是说,TPR越大越好,最好等于1,FPR越小越好,最好等于0,可是没有这么完美的事情,TPR变大的同时,FPR也会变大。数学家是聪明的,同时变化是吧,变化的速度总是有区别的吧?
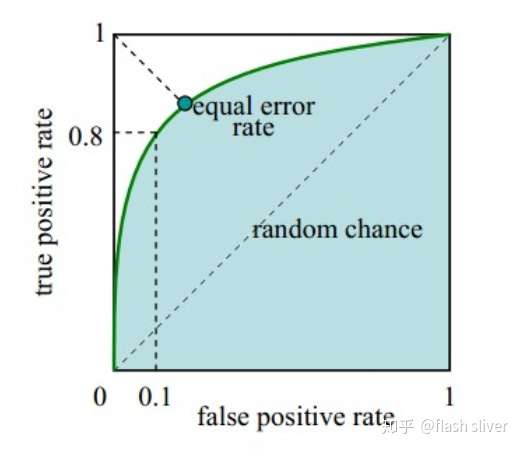
我们随机取很多阈值,得到很多FPR和TPR。用 X轴表示FPR,Y轴表示TPR,绘制上图曲线,这个曲线就是ROC曲线。(0,0)和(1,1)这两个坐标点根据实际情况,我们知道是固定的,假如两者的变化率是一样的,也就是说是一条过(0,0) 和(1,1) 的直线,此时斜率为1,也就是说随着阈值的变化,FPR和TPR 都同等程度变化。绘制出了曲线,是否可以用曲线的特性来表示模型的能力呢?我们希望得到的是:
- FPR 变化快的时候,TPR变化慢.
- FPR变化慢的时候,变化快。
到这里,我们又找到了一个评估模型的指标,对,就是图中的阴影面积,观察发现,我们可以用这个阴影面积的大小,来反应上面我们希望得到的特性,这个阴影面积的大小叫做AUC值。
AUC
AUC(Area Under Curve) 被定义为ROC曲线下的面积,因为ROC曲线一般都处于y=x这条直线的上方,所以取值范围在0.5和1之间,使用AUC作为评价指标是因为ROC曲线在很多时候并不能清晰地说明哪个分类器的效果更好,而AUC作为一个数值,其值越大代表分类器效果更好。需要注意的是AUC是一个概率值,当随机挑选一个正样本以及一个负样本,当前的分类算法根据计算得到的分数将这个正样本排在负样本前面的概率就是AUC值。所以,AUC的值越大,当前的分类算法越有可能将正样本排在负样本值前面,既能够更好的分类。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号