第10章 评价分类结果
分类算法的评价
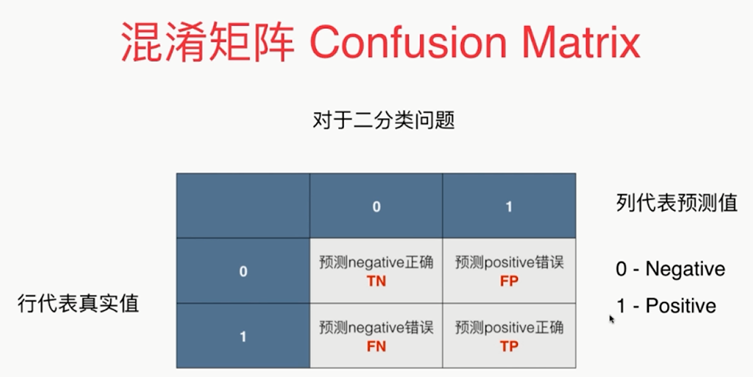
分类准确度的问题
 ,
,
 ,
,
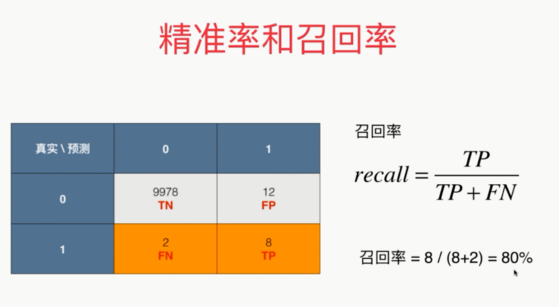
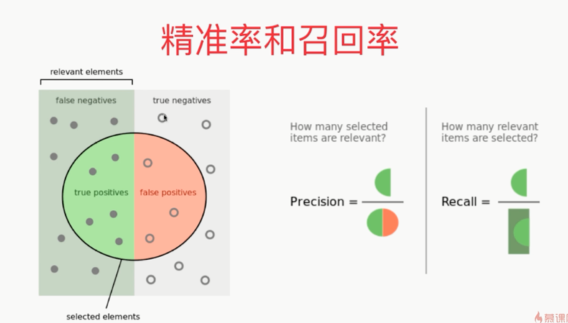
精准率和召回率
 ,
,
 ,
,
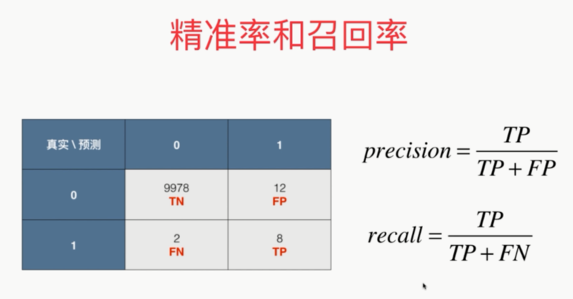 ,
,

 ,
,
 ,
,
 ,
,
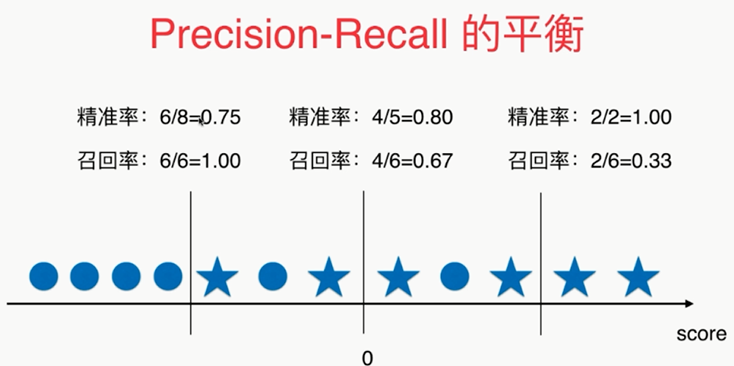
Precision和Recall的平衡
 ,
,
 ,
,
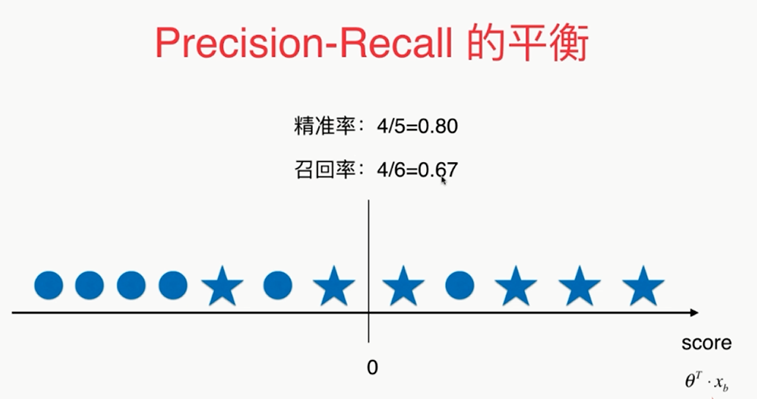 ,
,
 ,
,
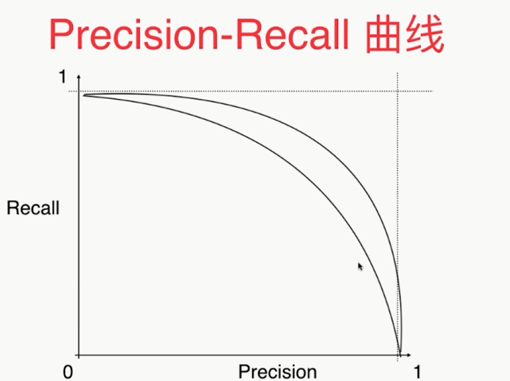 ,
,  ,
,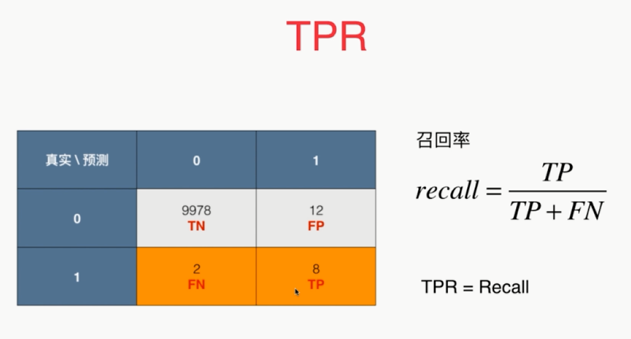 ,
,  ,
,
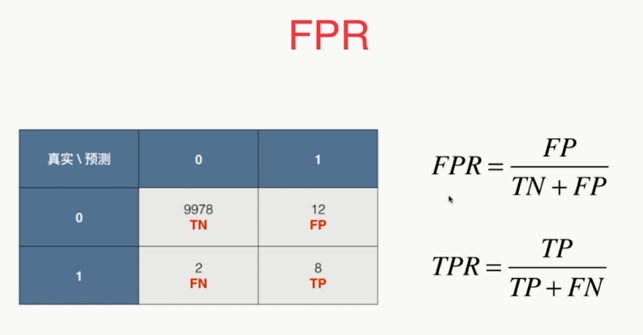 ,
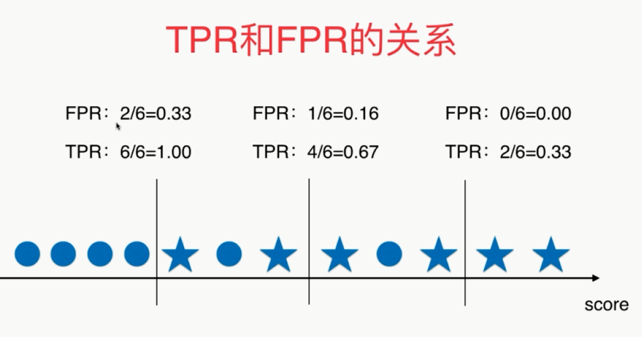
,
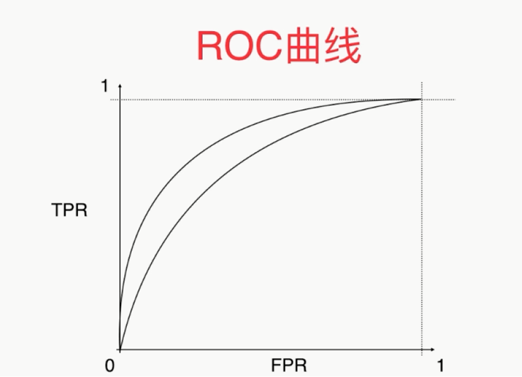
ROC,AUC用来比较两个模型的优劣


import numpy as np from sklearn import datasets digits=datasets.load_digits() X=digits.data y=digits.target.copy() y[digits.target==9]=1 y[digits.target!=9]=0 #由此变成了极度偏斜的数据问题(skewed data) from sklearn.model_selection import train_test_split X_train,X_test,y_train,y_test=train_test_split(X,y,random_state=666) from sklearn.linear_model import LogisticRegression log_reg=LogisticRegression() log_reg.fit(X_train,y_train) log_reg.score(X_test,y_test) y_log_predict=log_reg.predict(X_test) def TN(y_true,y_predict): assert len(y_true)==len(y_predict) return np.sum((y_true==0)&(y_predict==0)) TN(y_test,y_log_predict) def FP(y_true,y_predict): assert len(y_true)==len(y_predict) return np.sum((y_true==0)&(y_predict==1)) FP(y_test,y_log_predict) def FN(y_true,y_predict): assert len(y_true)==len(y_predict) return np.sum((y_true==1)&(y_predict==0)) FN(y_test,y_log_predict) def TP(y_true,y_predict): assert len(y_true)==len(y_predict) return np.sum((y_true==1)&(y_predict==1)) TP(y_test,y_log_predict) def confusion_matrix(y_true,y_predict): return np.array([ [TN(y_true,y_predict),FP(y_true,y_predict)], [FN(y_true,y_predict),TP(y_true,y_predict)] ]) confusion_matrix(y_test,y_log_predict) def precision_score(y_true,y_predict): tp=TP(y_true,y_predict) fp=FP(y_true,y_predict) try: return tp/(tp+fp) except: return 0.0 precision_score(y_test,y_log_predict) def recall_score(y_true,y_predict): tp=TP(y_true,y_predict) fn=FN(y_true,y_predict) try: return tp/(tp+fn) except: return 0.0 recall_score(y_test,y_log_predict) # scikit-learn中的混淆矩阵,精准率和召回率 from sklearn.metrics import confusion_matrix confusion_matrix(y_test,y_log_predict) from sklearn.metrics import precision_score precision_score(y_test,y_log_predict) from sklearn.metrics import recall_score recall_score(y_test,y_log_predict) ### 两者兼顾:(召回率和精准率)F1 Score def f1_score(precision,recall): try: return 2*precision*recall/(precision+recall) except: return 0.0 precision=0.5 recall=0.5 f1_score(precision,recall) # scikit-learn中的F1 Score from sklearn.metrics import f1_score f1_score(y_test,y_log_predict) # 精准率和召回率的平衡 decision_scores=log_reg.decision_function(X_test) y_predict_2=np.array(decision_scores>=5,dtype='int') confusion_matrix(y_test,y_predict_2) recall_score(y_test,y_predict_2) from sklearn.metrics import precision_score from sklearn.metrics import recall_score precisions=[] recalls=[] thresholds=np.arange(np.min(decision_scores),np.max(decision_scores),0.1) for threshold in thresholds: y_predict=np.array(decision_scores>=threshold,dtype='int') precisions.append(precision_score(y_test,y_predict)) recalls.append(recall_score(y_test,y_predict) plt.plot(thresholds,precisions) plt.plot(thresholds,recalls) plt.show() ### Precision-Recall 曲线 plt.plot(precisions, recalls) plt.show() ### scikit-learn中的Precision-Recall曲线 from sklearn.metrics import precision_recall_curve precisions,recalls,thresholds=precision_recall_curve(y_test,decision_scores) plt.plot(thresholds,precisions[:-1]) plt.plot(thresholds,recalls[:-1]) plt.show() plt.plot(precisions,recalls) plt.show() # ROC曲线 from playML.metrics import FPR,TPR fprs=[] tprs=[] thresholds=np.arange(np.min(decision_scores),np.max(decision_scores),0.1) for threshold in thresholds: y_predict=np.array(decision_scores>=threshold,dtype='int') fprs.append(FPR(y_test,y_predict)) tprs.append(TPR(y_test,y_predict)) plt.plot(fprs, tprs) plt.show() ### scikit-learn中的ROC曲线 from sklearn.metrics import roc_curve fprs, tprs, thresholds = roc_curve(y_test, decision_scores) plt.plot(fprs,tprs) plt.show() from sklearn.metrics import roc_auc_score # 求面积 roc_auc_score(y_test,decision_scores) 多分类问题中的混淆矩阵 import numpy as np import matplotlib.pyplot as plt from sklearn import datasets digits=datasets.load_digits() X=digits.data y=digits.target from sklearn.model_selection import train_test_split X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.8,random_state=666) from sklearn.linear_model import LogisticRegression log_reg=LogisticRegression() log_reg.fit(X_train,y_train) log_reg.score(X_test,y_test) y_predict=log_reg.predict(X_test) from sklearn.metrics import precision_score precision_score(y_test,y_predict,average="micro") # 解决多分类问题 from sklearn.metrics import confusion_matrix confusion_matrix(y_test,y_predict) cfm=confusion_matrix(y_test,y_predict) plt.matshow(cfm,cmap=plt.cm.gray) plt.show() row_sums=np.sum(cfm,axis=1) err_matrix=cfm/row_sums np.fill_diagonal(err_matrix,0) err_matrix plt.matshow(err_matrix,cmap=plt.cm.gray) plt.show()

