无监督学习
分类和回归都属于监督学习,特点就是他们都有一个标注,而标注的存在就是给分类任务或者回归任务一个指引,告诉算法,具备什么样特征的数据是什么样的标注,也就是它叫什么名字,哪些数据是一样的,哪些数据是不一样的,都是通过标注来区分的。
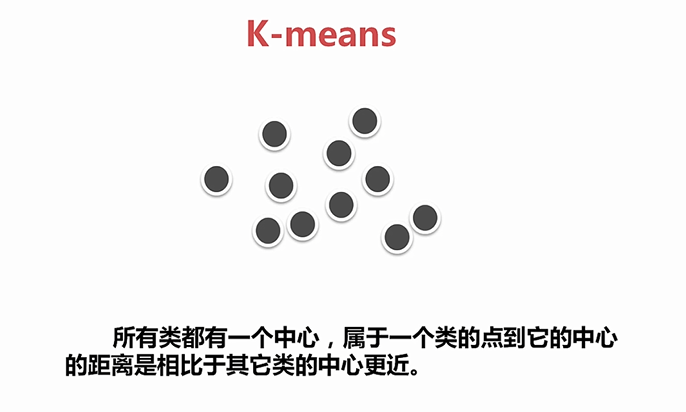
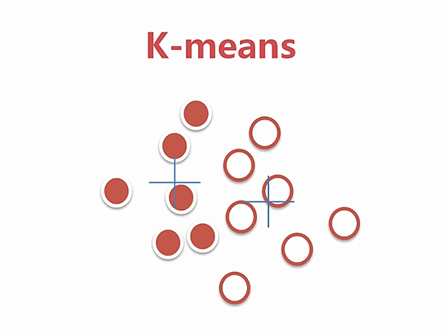
无监督学习:没有标注,目的就是试图给这些数据加上标注,而打标注并不是随便打的,有一个原则和假设就是我们希望给没有标注的数据加上标注以后,同一个标注内的数据尽可能的相似,而不同标注内的数据应该尽可能不同。
无监督学习用的最多的是两种算法:1.聚类,2.关联规则
 ,
, 
 ,
, 
 ,
,
 , 问题:对异常值也很敏感,
, 问题:对异常值也很敏感,
 ,
, 
 ,
, 
置信度:购买了X的情况下购买了Y的概率(类似条件概率)

提升度意义:分子:购买X的情况下购买Y的概率;分母:购买Y 的概率。在购买X的情况下购买Y的概率大于了本身Y的概率,那我们就认为购买X对购买Y有提升作用,若小于1,则认为购买X对购买Y没有起到提升作用,他们两个其实可以认为是相斥的(买了X就不买Y了)
 ,
, 
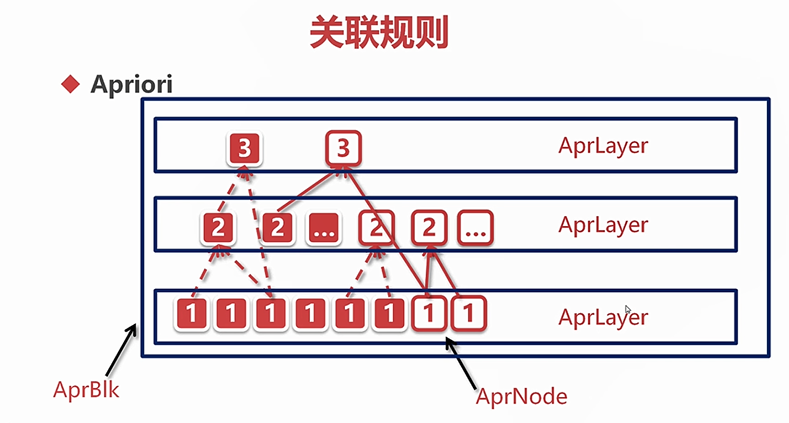
用低阶频繁项集和阈值找到高阶频繁项集,直到找打最高阶的
 ,
, 

 浙公网安备 33010602011771号
浙公网安备 33010602011771号