Mongodb(五):Mongodb的增删改查(4)----查询详解(下)
(1) $all查询:用于查询数组,匹配数组中的元素,要全部匹配才能有结果:示例:

现在我如果写成这个样子: db.customer.find({"books":{"$all":["java", "jQuery"]}}),那么是查不出结果的,因为
在document中匹配不到结果,只有将["java", "jQuery"]在document中全部匹配到,才能查询出来。它与sql语句中的in类似,
但是必须满足所有的条件。
(2) 在查询数组的时候,这样也是可以查出结果的:db.customer.find({"books":"java"}),如下:

我就一直觉得奇怪,明明是数组,怎么用这种方式去匹配也能够成功?不伦不类。暂且这样理解吧:在数组中,每一个元素都是整个
键的值。
当然,查询全部的数组元素肯定是可行的。如下:

但是请注意:一定是要精确的匹配才行,写成这样: db.customer.find({"books":["java","c"]})是查不出结果的,写成这样:
db.customer.find({"books":["java","c++","c"]})也是查不出结果的,就是说,连顺序都不能变。这更加深了我的疑问,怎
么db.customer.find({"books":"java"})这样匹配就行了?先这样记着吧。
(3) index的用法:一个问题:现在想查询第二本书 C 的document,该怎么办呢?现在就可以用到数组的下标了,如下:

数组下标是从0开始的。books.1就代表第二个元素
(4) $size:查询指定长度的数组,比如:现在要查询有3本书的记录,可以这样:db.customer.find({"books":{"$size":3}})

有一点要注意:$size只能精确的查询,不能做范围查询。
(5) $silce查询:返回一个数组的子集,一看就明白:

说明:db.customer.find({"_id":1}, {"name":1, "books":{"$slice":1}}):显示数组第一个元素(说得更准确点应该是显
示数组的前几个元素,从第一个元素开始取。也就是说,如果{"$slice":2}),结果就是:["java", "c"].
db.customer.find({"_id":1}, {"name":1, "books":{"$slice":[1,2]}}):显示数组区间1--2的元素
db.customer.find({"_id":1}, {"name":1, "books":{"$slice":-1}}):显示数组最后一个元素(说得更准确点应该是显示数
组的后几个元素)。看下面就明白了:

(6) 查询内嵌的document:
准备数据:{"_id":1, "name":"zhangsan","address":{"province":"hunan","city":"changsan"}},现在c
我想查找province为hunan的数据,可以这样做,利用 " . "进行查找:如下:
db.customer.find({"address.province":"hunan"})

注意:db.customer.find({"address":{"province":"hunan"}})这样写是查不出数据的,除非写成是完全匹配的形式:
db.customer.find({"address":{"province":"hunan", "city":"changsan"}}),这样是可以查出数据的。前者查不出
数据也很好理解, "address"这个键对应的值是{"province":"hunan", "city":"changsan"},而不是{"province":"hunan"},
同样 db.customer.find({"address.province":"hunan"})可以查出数据是因为"address.province"这个键对应的value就
是"hunan".
*****注意:进行绝对匹配是顺序一定不能乱。也不能有比较操作符。
(7) $elemMatch查询:相对上面来说复杂一点的内嵌document:准备数据如下:
{
"_id":2,
"name":"lisi",
"grade":
[
{"course":"math", "score":60, "flag":1},
{"course":"chinese","score":80, "flag":2},
{"course":"english","score":75, "flag":3}
]
}
现在我想找出course为math,score大于60的记录,应该怎样做? 按理说上面这条记录是查不出来的,因为不符合要求。
首先的思路可能是这样的:
db.stu.find({"grade":{"course":"math", "score":{"$gt":60}}}),这样肯定是不行的,原因上面已经说过。
那这样写呢?
db.stu.find({"grade.course":"math", "grade.score":{"$gt":60}}),看着应该可以,但实际上还是不行,这样
查的话,可以将上面那条记录查询出来。如下:
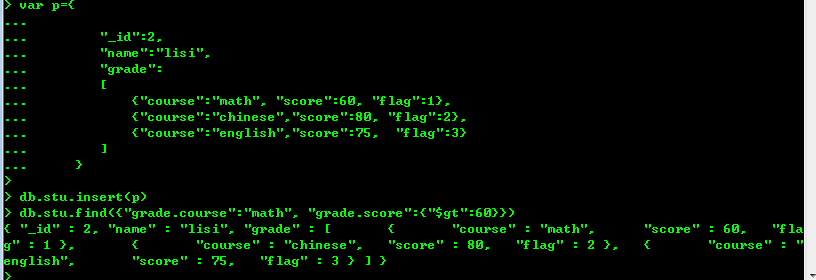
但实际上是不应该查询出来的。这是为什么?因为{"grade.course":"math", "grade.score":{"$gt":60}}不是一个整体,它可能
会分开进行匹配。即可能course匹配了math,但score匹配的是80或者75,这样数据就出来了。
那应该怎样做呢?如下所示:
db.stu.find({"grade":{"$elemMatch":{"course":"math", "score":{"$gt":60}}}})。
也就是说,$elementMatch是将该条件绑成一个整体,然后再进行匹配。
说明:"$elemMatch"将限定条件进行分组,仅当需要对一个内嵌文档的多个键操作时才会用到.
(8)"$where"查询:这是个万能的查询,因为是我们自己通过代码来进行控制的。写起来也比较容易,就是JS代码。示例如下:
查询name为zhangsan的用户的记录:如下:

可以这样理解:$where也是一个特殊的键,但它的值是一个函数(这种写法是符合JS的语法格式的)。然后在函数中做我们想做的
事情。它是怎样执行的呢?我的理解是每查询一条document,就会执行这个函数。函数中的this就代表当前正在进行匹配的docum
ent对象,然后通过this取出对象中的属性进行判断,如果符合要求就返回true,否则返回false, 一旦返回true,就说明这条记录
是符合要求的。至于这个例子,当然用其它的查询也很容易做到。这里是为了演示方便,就弄得很简单。$where查询方式适用于复杂
的的查询。功能很强大,但是不建议使用,说是会牺牲性能,不过这个我也没体会过。至于有什么补充的,后面想到再说吧。
(9) limit()函数:取多少条记录。比如:db.customer.find().limit(5),就是取前面的5条记录
(10)skip()函数:跳过多少条记录。比如:db.customer.find().skip(5):就是跳过5条记录,从6条记录开始取。
说明:db.collections名.find().skip(n):跳过n条记录,从第n+1条记录开始显示.
(11)sort()函数:进行排序。语法:db.collections名.find().sort(进行排序的字段:1), 其中1表示升序,如果是-1就是降序.

在sort中还可以指定多个进行排序的字段 如: db.persons.find().sort({"age":1, "_id":-1}):就是先按年龄升序,然后
按照_id降序.
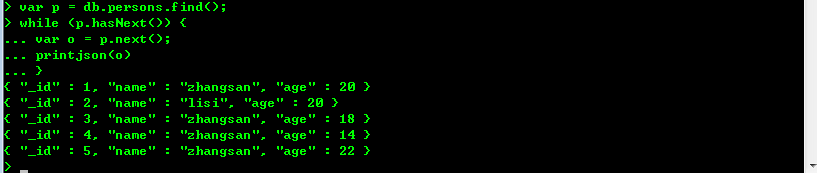
(12)游标:这个比较容易理解,db.persons.find()就是返回一个指向结果集的游标。比如我们可以这样来操作数据:
var p = db.persons.find()
while(p.hasNext()){
var o = persons.next();
printjson(o);
}
结果如下:
注意:游标几个销毁条件 1.客户端发来信息叫他销毁 2.游标迭代完毕 3.默认游标超过10分钟没用也会别清除

 浙公网安备 33010602011771号
浙公网安备 33010602011771号