
基于用户的推荐系统
推荐系统
-
意义
-
构成
- 用户建模模块
- 推荐对象建模模块
- 推荐算法模块
-
- 基于内容的推荐算法
- 协同过滤推荐
- 基于关联规则推荐
- 基于知识推荐
- 组合推荐
-
着重讲 协同过滤算法(基于用户的协同过滤)

-
购买手机数据 结构如下:
1,华为p30,2.0 1,三星s10,5.0 1,小米9,2.6 2,华为p30,1.0 2,vivo,5.0 2,htc,4.6 3,魅族,2.0 3,iphone,5.0 3,pixel2,2.6 -
将数据转成字典格式
{ '1': { '华为p30': '2.0', '三星s10': '5.0', '小米9': '2.6' }, '2': { '华为p30': '1.0', 'vivo': '5.0', 'htc': '4.6' }, '3': { '魅族': '2.0', 'iphone': '5.0', 'pixel2': '2.6' } }# 读数据 content = [] with open('./phone.txt',encoding='utf-8') as fp: content = fp.readlines() # 拼结构 data = {} for line in content: line = line.strip().split(',') #如果字典中没有某位用户,则使用用户ID来创建这位用户 if not line[0] in data.keys(): data[line[0]] = {line[1]:line[2]} #否则直接添加以该用户ID为key字典中 else: data[line[0]][line[1]] = line[2] -
计算欧式距离 公式为
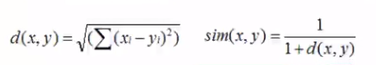
from math import * def Euclid(user1,user2): #取出两位用户购买过的手机和评分 user1_data=data[user1] user2_data=data[user2] distance = 0 #找到两位用户都购买过的手机,并计算欧式距离 for key in user1_data.keys(): if key in user2_data.keys(): #注意,distance越大表示两者越相似 distance = pow(float(user1_data[key])-float(user2_data[key]),2) return 1/(1+sqrt(distance))#这里返回值越小,相似度越大 -
计算当前用户和其他用户的相似度,这个我们可以循环比较,并升序排列
def top_simliar(userID): res = [] for userid in data.keys(): #排除与自己计算相似度 if not userid == userID: simliar = Euclid(userID,userid) res.append((userid,simliar)) # (1,0.57) res.sort(key=lambda val:val[1]) return res -
获取推荐的信息
def recommend(user): #相似度最高的用户 top_sim_user = top_simliar(user)[0][0] #相似度最高的用户的购买记录 items = data[top_sim_user] recommendations = [] #筛选出该用户未购买的手机并添加到列表中 for item in items.keys(): if item not in data[user].keys(): recommendations.append((item,items[item])) recommendations.sort(key=lambda val:val[1],reverse=True)#按照评分排序 return recommendations -
测试
print(recommend('1')) -
获取推荐的商品信息
[('vivo', '5.0'), ('htc', '4.6')]
-


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 因为Apifox不支持离线,我果断选择了Apipost!
· 通过 API 将Deepseek响应流式内容输出到前端