
《手牵手带你走进python世界》系列四
一、numpy
-
什么是numpy,一个高性能的科学计算和数据分析基础包,和numpy,matplotlib并称数学三剑客
-
开胃菜
# 计算执行时间 # 第一种普通程序猿执行方式 def func(values): s_list = [] for i in range(values): s_list.append(i**2) %timeit func(10000) # 第二种 数据分析师执行方式 import numpy as np arr = np.arange(10000) %timeit arr*arr ''' 第一种用时 976 µs ± 30.2 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each) 第二种用时 5.86 µs ± 208 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each) ''' -
numpy常用的方法
-
array 将列表转成数组
import numpy as np t = np.array([1,2,3,4,5]) print(t) # array([1,2,3,4,5]) -
arange('start','end','step') 相当于python的range()函数,顾头不顾尾
import numpy as np t = np.arange(1.0,10,0.2) print(t) -
linspace(start,end,step) 相当于python的range()函数,但是这个顾头又顾尾,并且是等份的。
import numpy as np t = np.linspace(1,20,8) print(t) -
zeros([行,列]) 生成一个以0为基准的多行多列数组
import numpy as np t = np.zeros([3,4]) print(t) -
ones([行,列]) 生成一个以1为基准的多行多列数组
import numpy as np t = np.ones([2,4]) print(t)
-
-
numpy常用的属性
-
T 数组的转置,说的通俗一点就是行和列互换
import numpy as np li1 = [ [1,2,3], [4,5,6] ] a = np.array(li1) a.T -
dtype 返回当前数据的类型
import numpy as np arr = np.arange(10) arr.dtype -
size 返回当前数组内部的元素的个数
import numpy as np l1 = [[[1,2,3], [4,5,6]], [[7,8,9], [1,5,9] ]] arr1 = np.array(l1) arr1.size -
ndim 返回当前数组维度
import numpy as np l1 = [[[1,2,3], [4,5,6]], [[7,8,9], [1,5,9] ]] arr1 = np.array(l1) arr1.ndim-
shape 返回数组维度大小
l1 = [[[1,2,3,4], [4,5,6,5], [6,8,3,6]], [[7,8,9,7], [1,5,9,7], [4,6,8,4] ]] arr1 = np.array(l1) t = arr1.shape ''' 结果:(2,3,4) 最终三个参数代表的含义依次为:二维维度,三维维度,每个数组内数据大小 '''
-
二、pandas
-
当大家谈论到数据分析时,提及最多的语言就是Python和SQL,而Python之所以适合做数据分析,就是因为他有很多强大的第三方库来协助,pandas就是其中之一,它是基于Numpy构建的,正因pandas的出现,让Python语言也成为使用最广泛而且强大的数据分析环境之一。
-
安装和使用
- pip install pandas
- import pandas as pd
-
开胃菜
-
Series
-
是一种类似于一维数组的对象,由一组数据和一组与之相关的数据标签(索引)组成。在数据分析的过程中非常常用,对于Series,其实我们可以认为它是一个长度固定且有序的字典,因为它的索引和数据是按位置进行匹配的,像我们会使用字典的上下文,就肯定也会使用Series
import pandas as pd t = pd.Series([1,2,3,4,5]) print(t) ''' 结果: 0 1 1 2 2 3 3 4 4 5 dtype: int64 '''# 设置索引 t = pd.Series([1,2,3,4,5],index=['n1','n2','n3','n4','n5']) ''' 结果: n1 1 n2 2 n3 3 n4 4 n5 5 dtype: int64 '''
-
-
DataFrame
-
DataFrame是一个表格型的数据结构,相当于是一个二维数组,含有一组有序的列。他可以被看做是由Series组成的字典,并且共用一个索引。接下来就一起来见识见识DataFrame数组的厉害吧!!!
-
生成一个行列
import pandas as pd t = pd.DataFrame({'one':[1,2,3,4],'two':[4,3,2,1]}) ''' 结果: one two 0 1 4 1 2 3 2 3 2 3 4 1 ''' -
添加指定列名
import numpy as np data = pd.DataFrame({'one':[1,2,3,4],'two':[4,3,2,1]}) pd.DataFrame(data,columns=['two','one']) ''' 结果: two one 0 4 1 1 3 2 2 2 3 3 1 4 ''' -
获取index
import numpy as np data = pd.DataFrame({'one':[1,2,3,4],'two':[4,3,2,1]}) data.index ''' 结果: RangeIndex(start=0, stop=4, step=1) ''' -
获取columns
import numpy as np data = pd.DataFrame({'one':[1,2,3,4],'two':[4,3,2,1]}) data.columns ''' 结果: Index(['one', 'two'], dtype='object') ''' -
T 转置
import numpy as np data = pd.DataFrame({'one':[1,2,3,4],'two':[4,3,2,1]}) data.T ''' 结果: 0 1 2 3 one 1 2 3 4 two 4 3 2 1 ''' -
获取values索引值
import numpy as np data = pd.DataFrame({'one':[1,2,3,4],'two':[4,3,2,1]}) data.values ''' 结果: array([[1, 4], [2, 3], [3, 2], [4, 1]]) ''' -
获取快速统计 describe
import numpy as np data = pd.DataFrame({'one':[1,2,3,4],'two':[4,3,2,1]}) data.describe ''' 结果: <bound method NDFrame.describe of one two 0 1 4 1 2 3 2 3 2 3 4 1> '''
-
-
三、matplotlib(绘图)
-
数据可视化,数据可视化在量化分析当中是一个非常关键的辅助工具,往往我们需要通过可视化技术,对我们的数据进行更清晰的展示,这样也能帮助我们理解交易、理解数据。通过数据的可视化也可以更快速的发现量化投资中的一些问题,更有利于分析并解决它们。接下来我们主要使用的可视化工具包叫
Matplotlib,它是一个强大的Python绘图和数据可视化的工具包。 -
安装和使用
- pip install matplotlib
- import matplotlib.pyplot as plt
-
绘图方法和显示图像
- plt.plot() # 绘图函数
- plt.show() # 显示图像
-
开胃菜
import matplotlib.pyplot as plt import matplotlib as mpl import numpy as np np.random.seed(1000) y = np.random.standard_normal(20) # 生成正态分布的随机数 x = range(len(y)) plt.plot(x,y) -
图样实例
-
饼图
import matplotlib.pyplot as plt plt.pie([10,20,30,40],labels=list('abcd'),autopct="%.2f%%",explode=[0.1,0,0,0]) # 饼图 plt.axis("equal") plt.title('absd') plt.show()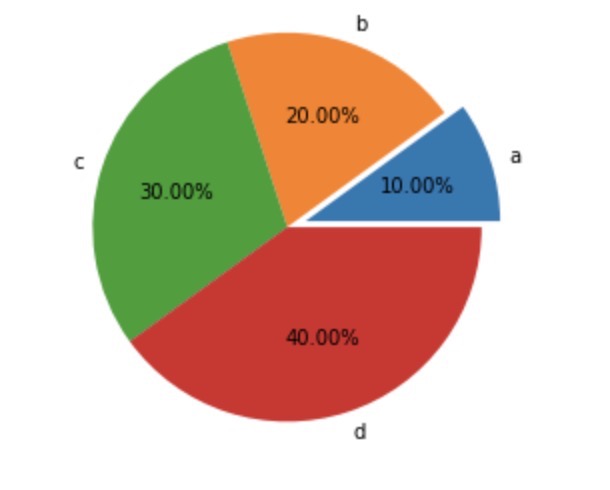
-
柱图
import matplotlib.pyplot as plt plt.figure(figsize=(7,4)) plt.hist(y,label=['1st','2nd'],bins=25) plt.grid(True) # 网格设置 plt.legend(loc=0) # 图例标签位置设置 plt.axis("tight") plt.xlabel('index') plt.ylabel('frequency') plt.title("test6")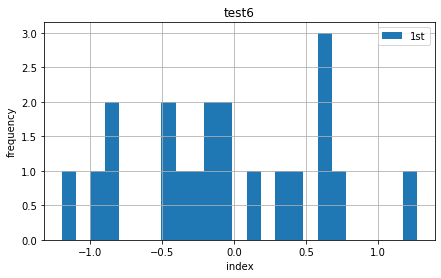
-
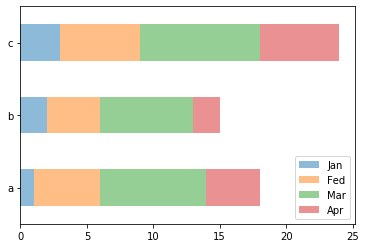
柱图
# DataFrame数组图 import matplotlib.pyplot as plt import pandas as pd df = pd.DataFrame({ 'Jan':pd.Series([1,2,3],index=['a','b','c']), 'Fed':pd.Series([4,5,6],index=['b','a','c']), 'Mar':pd.Series([7,8,9],index=['b','a','c']), 'Apr':pd.Series([2,4,6],index=['b','a','c']) }) df.plot.bar() # 水平柱状图,将每一行中的值分组到并排的柱子中的一组 df.plot.barh(stacked=True,alpha=0.5) # 横向柱状图,将每一行的值堆积到一起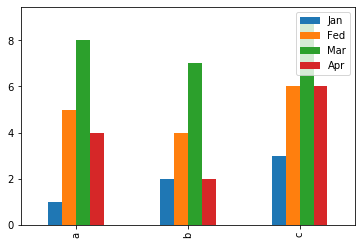
-
折线图
import matplotlib.pyplot as plt import numpy as np np.random.seed(1000) y = np.random.standard_normal(20) # 生成 x = range(len(y)) plt.plot(x,y) plt.title('yes') plt.xlabel('x--') plt.ylabel('y--') # plt.xlim(0,50) plt.xticks([1,2,3,4,5,6,7,8,9])
-

 浙公网安备 33010602011771号
浙公网安备 33010602011771号