Hive(三)分组、聚合、排序、窗口函数
最近看了一遍hive的文档,本文是为了记录文档中将来会可用东西,并非最全的《文档》,望谅解
一:建表语句
drop table window_test;
create external table if not exists window_test
(
name string,
score string
)
row format delimited
fields terminated by '|'
location '/hive/table/window_test';
二:排序函数
| 关键字 | 含义 |
| sortby | 分区内有序 |
| orderby | 全局有序 |
| distrbuteby | 分区函数 |
| clusterby |
sortby distrbuteby字段相同 只能升序排列 |
三:函数操作
1.sum与over实现定制sum
//查询当前行和下两行score总分的数据
select name, score, sum(score)over(order by name rows between current row and 2 following) from window_test;
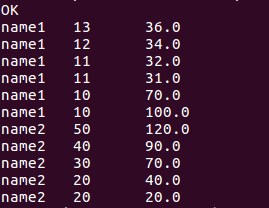
//查询当前行和上两行score总分的数据
select name, score, sum(score)over(order by name rows between 2 preceding and current row) from window_test;
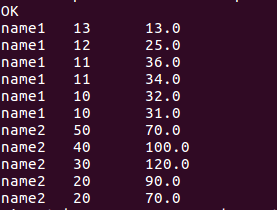
//查询当前行和以下行score总分的数据
select name, score, sum(score)over(order by name rows between current row and unbounded following) from window_test;
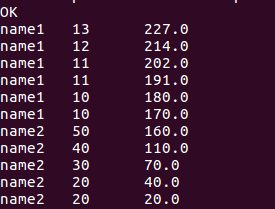
//查询当前行和以上行score总分的数据
select name, score, sum(score)over(order by name rows between unbounded preceding and current row) from window_test;
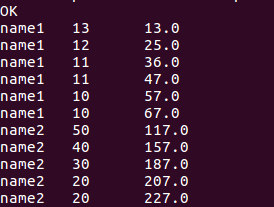
2.排序
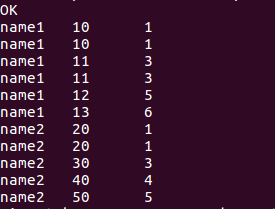
//排序函数 每一个name分组后从1开始排序,相同的数据列序号相同,后一个加一
select name, score, rank()over(partition by name order by score) from window_test;
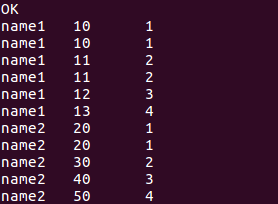
//排序函数 每一个name分组后从1开始排序,相同的数据列序号相同,后一个不加一
select name, score, dense_rank()over(partition by name order by score) from window_test;
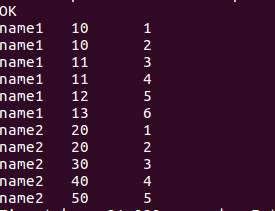
//排序函数 每一个name分组后从1开始排序,相同的数据列序号不相同
select name, score, row_number()over(partition by name order by score) from window_test;
3.第一个值、最后一个值
//分组内排正序取第一个score
select name, score, first_value(score)over(partition by name order by score) from window_test;
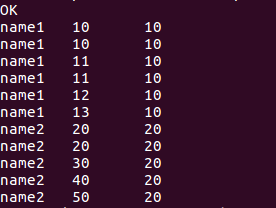
//分组内排正序取最后一个score
select name, score, last_value(score)over(partition by name order by score range between unbounded preceding and unbounded following) from window_test;
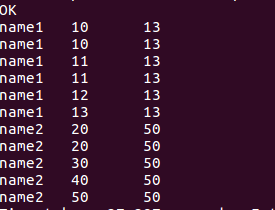
//函数的结果是错误的,必须要前面一大段
//select name, score, last_value(score)over(partition by name order by score) from window_test;
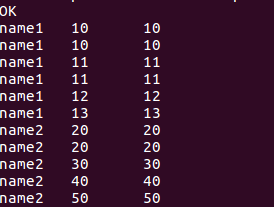
4.数据动态等级划分
//根据分数将数据分为三个区域
select name, score, ntile(3)over(order by score) from window_test;
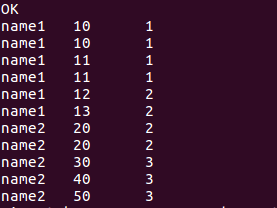
5.上一行、下一行
//下两行的score提过来,没有填充NULL
select name, score, lead(score,2)over(partition by name order by score) from window_test;
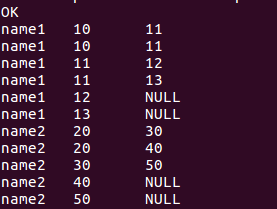
//上两行的score提过来,没有填充NULL
select name, score, lag(score,2)over(partition by name order by score) from window_test;
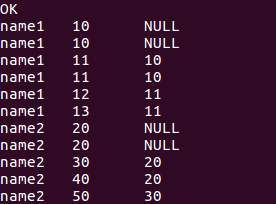
6.占比函数
//小于当前值SCORE的人数占总人数的占比(name分组)
select name, score, cume_dist()over(partition by name order by score) from window_test;
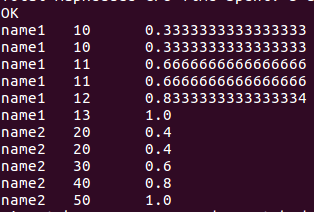
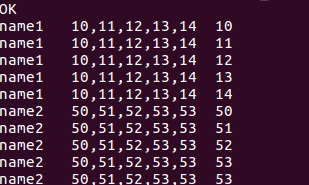
7.行列转
//行转列
select name,concat_ws(',',collect_list(score)) as score_value from window_test group by name;

//列转行
select name,score,score_value from window_test lateral view explode(split(score,','))num as score_value;
四:聚合函数
1.GROUPING SET、grouping__id
select grouping__id,month,day,count(1) from tranods_dev.user_detail group by month,day grouping sets((month,day),month,day,());

grouping__id:grouping sets()里面的值,0代表(month,day),1代表month,2代表day,3代表count(1)
2.with rollup
select grouping__id,month,day,count(1) from tranods_dev.user_detail group by month,day with rollup order by grouping__id ;

结果:all,group by month,group by month,day 以左边的数据为主,依次递减
3.cube
select grouping__id,month,day,count(1) from tranods_dev.user_detail group by cube(month,day) order by grouping__id ;

结果:全量维度数据group by
4.配置
set hive.new.job.grouping.set.cardinality = 30;
这条设置的意义在于告知解释器,group by之前,每条数据复制量在30份以内。2^维度数 大于5的时候就是32


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 探究高空视频全景AR技术的实现原理
· 理解Rust引用及其生命周期标识(上)
· 浏览器原生「磁吸」效果!Anchor Positioning 锚点定位神器解析
· DeepSeek 开源周回顾「GitHub 热点速览」
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· AI与.NET技术实操系列(二):开始使用ML.NET
· 单线程的Redis速度为什么快?