

Python之路(六)——Python 常用模块
本节内容
- time & datetime
- random
- os
- sys
- json & pickle & shelve
- xml处理
- configparser
- hashlib
- logging
- re正则表达式
一、time & datetime
基本概念
- UTC(Coordinated Universal Time)即格林威治天文时间,为世界标准时间 UTC+0。是以经度来区分,东部的国家早,西部的迟。中国北京为 UTC+8
- DST(Daylight Saving Time)即夏令时。大家都知道夏天白昼长,夜晚短。冬天反之。有些国家就实行DST ,例如夏天 本来现在是 7:00am,觉得和平时相比较应该 8:00am,所以+1。而我国已经暂停了DST,因为实行起来有难度
- 时间戳:指Unix诞生日(1970年01月01日00时00分00秒)到现在的毫秒数。
time表现形式
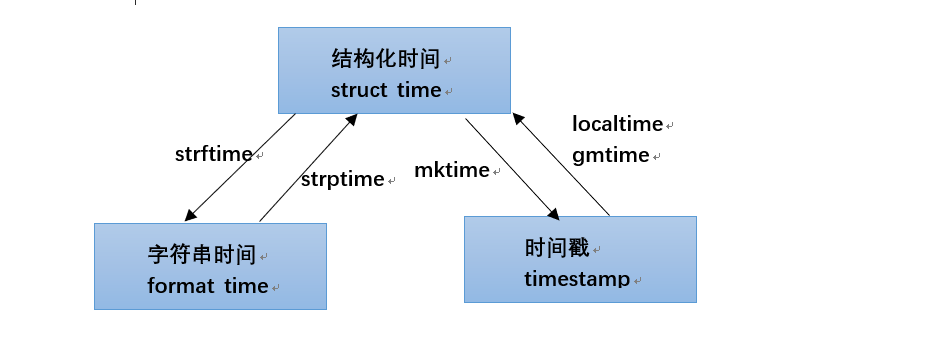
# 获取时间
import time
dt = time.time()
print(dt) # 1548070178.4083416
#时间戳转结构化时间
stru_dt =time.localtime(dt) #本地时间
time.gmtime(dt) #格林尼治时间
#tm_year :年
#tm_mon:月
#tm_mday:日
#tm_hour:小时
#tm_min:分
#tm_sec:秒
#tm_wday:一星期第几天 0:星期一
#tm_yday:一年第几天
#tm_isdst:是否采用夏时令
#结构化时间转字符串
print(time.strftime("%Y-%m-%d %X", stru_dt))#%X == %H:%M:%S
str = "2019-01-22 19:43:43"
stru_dt2 = time.strptime(str,"%Y-%m-%d %X")
time.mktime(stru_dt2)
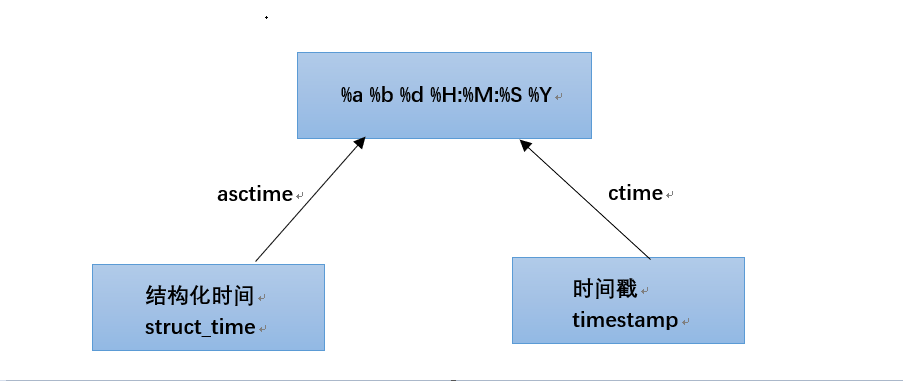
print(time.asctime()) # Mon Jan 21 20:05:40 2019
str = "Mon Jan 21 20:05:40 2019"
time.strptime(str,"%a %b %d %H:%M:%S %Y")
datetime
import datetime
print(datetime.datetime.now()) #2019-01-21 20:13:18.106940
dt = datetime.datetime.now()
print(dt.date())
print(dt.time())
print(dt.timetuple())
print(dt.strftime("%Y-%m-%d %X")) # 2019-01-21 20:15:45
二、random
# import random
# print(random.random()) #0<=n<1.0 小数
# print(random.randint(0,9))#0..9随机整数,含9
# print(random.randrange(0,9,2))#指定步长
#
# # 洗牌操作
# p=["pyhton","is","powerful","simple","and so on..."]
# random.shuffle(p)
# print(p)
#
# #一个序列随机选择
# print(random.choice(["JGood","is","a","handsome","body"])) #is
#
# #随机选择样本
# l = [1,2,3,4,5,6,7,8,9,10]
# print(random.sample(l, 5)) # [3, 10, 8, 5, 6]
#验证码
def code(num):
'''
生成num个符号的验证码,包含字母和数字
:param num: 验证码的个数
:return: 字符串
'''
import random
res = ''
for i in range(num):
n = random.random()
if n >=0.5:
res += str(random.randrange(0,9))
else:
res += chr(random.randrange(65,122))
return res
if __name__ == '__main__':
print(code(5))
三、os
操作系统环境信息
os.getcwd() # #获取当前工作目录,即当前python脚本工作的目录路径
# os.chdir("dirname") # # 改变当前脚本工作目录;相当于shell下cd
# os.curdir #返回当前目录: ('.')
# os.pardir #获取当前目录的父目录字符串名:('..')
# os.makedirs('dirname1/dirname2') # # 可生成多层递归目录
# os.removedirs('dirname1') # # 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
# os.mkdir('dirname') # # 生成单级目录;相当于shell中mkdir dirname
# os.rmdir('dirname') # # 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
# os.listdir('dirname') # # 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
# os.remove() # # 删除一个文件
# os.rename("oldname","newname") # # 重命名文件/目录
# os.stat('path/filename') # # 获取文件/目录信息
# os.sep #输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/"
# os.linesep #输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n"
# os.pathsep #输出用于分割文件路径的字符串
# os.name #输出字符串指示当前使用平台。win->'nt'; Linux->'posix'
# os.system("bash command") # # 运行shell命令,直接显示
# os.environ #获取系统环境变量
# os.path.abspath(path) # # 返回path规范化的绝对路径
# os.path.split(path) # # 将path分割成目录和文件名二元组返回
# os.path.dirname(path) # # 返回path的目录。其实就是os.path.split(path)的第一个元素
# os.path.basename(path) # # 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素
# os.path.exists(path) # # 如果path存在,返回True;如果path不存在,返回False
# os.path.isabs(path) # # 如果path是绝对路径,返回True
# os.path.isfile(path) # # 如果path是一个存在的文件,返回True。否则返回False
# os.path.isdir(path) # # 如果path是一个存在的目录,则返回True。否则返回False
# os.path.join(path1[, path2[, ...]]) # # 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
# os.path.getatime(path) # # 返回path所指向的文件或者目录的最后存取时间
# os.path.getmtime(path) # # 返回path所指向的文件或者目录的最后修改时间
四、sys
编译器环境
import sys
# sys.argv 命令行参数List,第一个元素是程序本身路径
# #sys.exit(n) 退出程序,正常退出时exit(0)
# sys.version 获取Python解释程序的版本信息
# sys.maxint 最大的Int值
# sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
# sys.platform 返回操作系统平台名称
sys.stdout.write('please:') #input
val = sys.stdin.readline()[:-1] #print
print(val)
五、json & pickle & shevle
这三个模块都是完成对象的序列化功能
序列化
简单来说 把一个实体对象变成字符串,用于保存、传输;反之获取到已序列化的字符串可以反推得到对象。
区别
- json 序列化后的串可以用于其他语言<推荐>
- pickle 功能类似json,适用于python程序间的序列化对象互传
- shelve python专用,采用其他形式的保存序列化对象
#1.python 与json 对象对应关系
# +-------------------+---------------+
# | Python | JSON |
# +===================+===============+
# | dict | object |
# +-------------------+---------------+
# | list, tuple | array |
# +-------------------+---------------+
# | str | string |
# +-------------------+---------------+
# | int, float | number |
# +-------------------+---------------+
# | True | true |
# +-------------------+---------------+
# | False | false |
# +-------------------+---------------+
# | None | null |
# +-------------------+---------------+
#2.演示序列化-dumps,反序列化-loads
import json
#序列化后写入文件
# data = {"name": 'alex', 'age':18}
# json_obj = json.dumps(data)
# with open("json.txt","w") as f:
# f.write(json_obj)
#从文件中反序列
# with open("json.txt","r") as f:
# json_obj = f.read()
# data = json.loads(json_obj)
# print(data['name']) #alex
#dump, load: 简化上述步骤
# data = {"name": 'alex', 'age':18}
# json.dump(data,open("json_test2.txt","w"))
data = json.load(open("json_test2.txt","r"))
print(data['age']) #18
六、xml处理
在老的软件系统中,软件与软件之间信息传递常用到xml标签语言来进行传输。缺点:体积大(类比json)
#一、解析xml countries举例 -查
#countries.xml 内容:
# <data>
# <country name="China">
# <year birth="1949"/>
# <population>150000</population>
# <rank updated="yes">1</rank>
# <subcontry name = "taiwang">
# <population>5000</population>
# </subcontry>
# </country>
# <country name="Japan">
# <year birth="2011"/>
# <population >20000</population>
# <rank updated="yes">52</rank>
# </country>
# </data>
#0. 使用第三方工具包ET 操作XML
import xml.etree.cElementTree as ET
#1. 加载文件到内存生成xml 树
# tree = ET.ElementTree(file='countries.xml')
#2. 获取根节点 对象
# root = tree.getroot()
# 3. 节点对象 -tag ,attrib text 属性
# print(root.tag) #data 根仅有tag
# 4. 查找特定标签
#找出树中的所有population节点,并打印节点名,节点内容
# for item in tree.iter(tag='population'): #没有参数遍历所有节点
# print(item.tag, item.text)
#5. 使用xpath查找节点
# #仅找country 下的population 节点
# for item in tree.iterfind('country/population'):
# print(item.tag, item.text)
#二、修改xml 内容 -改
#
#找到china rank值修改为No.1
# china_rank = root.find('country[@name="China"]/rank') #找到节点
# china_rank.text = 'No.2'
# china_rank.set("updated","no")
# tree.write("bak.xml") #保存文件
#三、删除某个元素
#删除rank ==1 的country节点(含子节点)
# for country in root.findall('country'):
# if country.find('rank').text == '1':
# root.remove(country)
#
# tree.write('bak2.xml')
# 四、构建xml
#
# #1. 创建根节点
root = ET.Element('namelist')
# #2. 创建子节点
child1 = ET.SubElement(root,"child1",attrib={"scrolled" : "yes"})
# #3. 属性,内容赋值
name1 = ET.SubElement(child1,"name",attrib={"updated" :"no"})
age1 = ET.SubElement(child1,"age")
age1.text = '20' #必须为字符串
child2 = ET.SubElement(root,"child2",attrib={"scrolled" : "yes"})
name2 = ET.SubElement(child2,"name",attrib={"updated" :"no"})
age2 = ET.SubElement(child2,"age")
age2.text = '18'
# #4.构建xml 内存对象
tree = ET.ElementTree(root)
#保存文件
tree.write("elem.xml",encoding="utf8",xml_declaration=True)
# #ele.xml内容:
# <?xml version='1.0' encoding='utf8'?>
# <namelist>
# <child1 scrolled="yes">
# <name updated="no"/>
# <age>20</age>
# </child1>
# <child2 scrolled="yes">
# <name updated="no"/>
# <age>18</age>
# </child2>
# </namelist>
七、configparser
软件配置文件模块。环境找不到
八、hashlib
基础概念
哈希(hash):把一组数据通过算法生成一组数据的过程。结果值也叫哈希值。特征如下:
- 不论原值多大,得到的哈希值都是固定长度大小
- 相同值得到的哈希值一定相同
- 不能通过哈希值得到原数据
加密/解密:把一串数字(明文)转化成另外一串数字(密文),反之亦然。特征如下:
- 密文长度非固定,往往和明文长度挂钩
- 可逆推,即:密文可以变为明文
两者区别与联系
- 都是原始数据与结果数据的对应关系。算法不相同:哈希算法、加解密算法;哈希没有逆对应关系
- 应用场景:不需要从结果值得到原始值的情况下可以用哈希(例:登陆验证),反之使用加解密
常用算法
- 对称加密算法:DES、3DES、DESX、Blowfish、IDEA、RC4、RC5、RC6和AES
- 非对称加密算法:RSA、ECC(移动设备用)、Diffie-Hellman、El Gamal、DSA(数字签名用)
- hash算法:MD2、MD4、MD5、HAVAL、SHA、SHA-1、HMAC、HMAC-MD5、HMAC-SHA1
Python中使用hash算法
import hashlib
s = 'amdin'
#一、构造hash工厂
#1.md5 工厂
# h_md5 = hashlib.md5()
# h_md5.update(s.encode("utf-8"))
# res = h_md5.hexdigest()
# print(res,len(res)) # eb184cc3e4469723f6afda6b176ebb49 32
#2.sha1工厂
# h_sha1 = hashlib.sha1()
# h_sha1.update(s.encode("utf-8"))
# res = h_sha1.hexdigest()
# print(res,len(res)) # b40d9e6bb64cb13283f6f193809757903f92fd27 40
#3.sha3_256工厂
# h_sha3_256 = hashlib.sha3_256()
# h_sha3_256.update(s.encode("utf-8"))
# res = h_sha3_256.hexdigest()
# print(res,len(res)) # b4a7baf8dec027efacaffb671aa31a3f93e09c9b8441dbf49015b1fc3c3e62bc 64
#结论:不同的hash 算法,哈希值长度不同
# 二、多次hash (举例:md5)
#1.md5 工厂
# h_md5 = hashlib.md5()
# #hash正式数据前先hash 一遍 ---二次hash解决撞库
# h_md5.update('猪'.encode("utf-8"))
# h_md5.update(s.encode("utf-8"))
# res = h_md5.hexdigest()
# print(res,len(res)) # faa81384ab8e45bcd69ca50976d8273d 32
九、logging
参看这篇文章 https://www.cnblogs.com/dkblog/archive/2011/08/26/2155018.html
十、re 正则表达式
本节引自《https://www.cnblogs.com/greatfish/p/7572131.html》
正则
对字符串进行模糊匹配,例如:判断身份证号是否有效;判断一个字符串是否是新浪邮箱..
语法
- 字符与字符类
特殊字符:\.^$?+*{}[]()|
以上特殊字符要想使用字面值,必须使用\进行转义
字符类
1. 包含在[]中的一个或者多个字符被称为字符类,字符类在匹配时如果没有指定量词则只会匹配其中的一个。
2. 字符类内可以指定范围,比如[a-zA-Z0-9]表示a到z,A到Z,0到9之间的任何一个字符
3. 左方括号后跟随一个^,表示否定一个字符类,比如[^0-9]表示可以匹配一个任意非数字的字符。
4. 字符类内部,除了\之外,其他特殊字符不再具备特殊意义,都表示字面值。^放在第一个位置表示否定,放在其他位置表示^本身,-放在中间表示范围,放在字符类中的第一个字符,则表示-本身。5. 字符类内部可以使用速记法,比如\d \s \w
速记法
. 可以匹配除换行符之外的任何字符,如果有re.DOTALL标志,则匹配任意字符包括换行
\d 匹配一个Unicode数字,如果带re.ASCII,则匹配0-9
\D 匹配Unicode非数字
\s 匹配Unicode空白,如果带有re.ASCII,则匹配\t\n\r\f\v中的一个
\S 匹配Unicode非空白
\w 匹配Unicode单词字符,如果带有re.ascii,则匹配[a-zA-Z0-9_]中的一个
\W 匹配Unicode非单子字符
- 量词
1. ? 匹配前面的字符0次或1次
2. * 匹配前面的字符0次或多次
3. + 匹配前面的字符1次或者多次
4. {m} 匹配前面表达式m次
5. {m,} 匹配前面表达式至少m次
6. {,n} 匹配前面的正则表达式最多n次
7. {m,n} 匹配前面的正则表达式至少m次,最多n次
注意点:
以上量词都是贪婪模式,会尽可能多的匹配,如果要改为非贪婪模式,通过在量词后面跟随一个?来实现
- 组与捕获
1. ()的作用:
1. 捕获()中正则表达式的内容以备进一步利用处理,可以通过在左括号后面跟随?:来关闭这个括号的捕获功能
2. 将正则表达式的一部分内容进行组合,以便使用量词 or |
2. 反响引用前面()内捕获的内容:
1. 通过组号反向引用
每一个没有使用?:的小括号都会分配一个组好,从1开始,从左到右递增,可以通过\i引用前面()内表达式捕获的内容
2. 通过组名反向引用前面小括号内捕获的内容
可以通过(?P<name>),尖括号中放入组名来为一个组起一个别名,后面通过(?P=name)来引用 前面捕获的内容。如(? P<word>\w+)\s+(?P=word)来匹配重复的单词。
3. 注意点:
反向引用不能放在字符类[]中使用。
- 断言与标记
断言不会匹配任何文本,只是对断言所在的文本施加某些约束
1. 常用断言:
1. \b 匹配单词的边界,放在字符类[]中则表示backspace
2. \B 匹配非单词边界,受ASCII标记影响
3. \A 在起始处匹配
4. ^ 在起始处匹配,如果有MULTILINE标志,则在每个换行符后匹配
5. \Z 在结尾处匹配
6. $ 在结尾处匹配,如果有MULTILINE标志,则在每个换行符前匹配
7. (?=e) 正前瞻
8. (?!e) 负前瞻
9. (?<=e) 正回顾
10.(?<!e) 负回顾 2. 前瞻回顾的解释 前瞻: exp1(?=exp2) exp1后面的内容要匹配exp2
负前瞻: exp1(?!exp2) exp1后面的内容不能匹配exp2
后顾: (?<=exp2)exp1 exp1前面的内容要匹配exp2
负后顾: (?<!exp2)exp1 exp1前面的内容不能匹配exp2
例如:我们要查找hello,但是hello后面必须是world,正则表达式可以这样写:"(hello)\s+(?=world)",用来匹配"hello wangxing"和"hello world"只能匹配到后者的hello
- 条件匹配
(?(id)yes_exp|no_exp):对应id的子表达式如果匹配到内容,则这里匹配yes_exp,否则匹配no_exp
- 正则表达式的标志
1. 正则表达式的标志有两种使用方法
1. 通过给compile方法传入标志参数,多个标志使用|分割的方法,如re.compile(r"#[\da-f]{6}\b", re.IGNORECASE|re.MULTILINE)
2. 通过在正则表达式前面添加(?标志)的方法给正则表达式添加标志,如(?ms)#[\da-z]{6}\b
2. 常用的标志
re.A或者re.ASCII, 使\b \B \s \S \w \W \d \D都假定字符串为假定字符串为ASCII
re.I或者re.IGNORECASE 使正则表达式忽略大小写
re.M或者re.MULTILINE 多行匹配,使每个^在每个回车后,每个$在每个回车前匹配
re.S或者re.DOTALL 使.能匹配任意字符,包括回车
re.X或者re.VERBOSE 这样可以在正则表达式跨越多行,也可以添加注释,但是空白需要使用\s或者[ ]来表示,因为默认的空白不再解释。如:
re.compile(r"""
<img\s +) #标签的开始
[^>]*? #不是src的属性
src= #src属性的开始
(?:
(?P<quote>["']) #左引号
(?P<image_name>[^\1>]+?) #图片名字
(?P=quote) #右括号
""",re.VERBOSE|re.IGNORECASE)
常用功能
1. rx.findall(s,start, end):返回一个列表,如果正则表达式中没有分组,则列表中包含的是所有匹配的内容,如果正则表达式中有分组,则列表中的每个元素是一个元组,元组中包含子分组中匹配到的内容,但是没有返回整个正则表达式匹配的内容
2. rx.finditer(s, start, end):
返回一个可迭代对象,对可迭代对象进行迭代,每一次返回一个匹配对象,可以调用匹配对象的group()方法查看指定组匹配到的内容,0表示整个正则表达式匹配到的内容
3. rx.search(s, start, end):
返回一个匹配对象,倘若没匹配到,就返回None。search方法只匹配一次就停止,不会继续往后匹配
4. rx.match(s, start, end):如果正则表达式在字符串的起始处匹配,就返回一个匹配对象,否则返回None
5. rx.sub(x, s, m):返回一个字符串。每一个匹配的地方用x进行替换,返回替换后的字符串,如果指定m,则最多替换m次。对于x可以使用/i或者/g<id>id可以是组名或者编号来引用捕获到的内容。 模块方法re.sub(r, x, s, m)中的x可以使用一个函数。此时我们就可以对捕获到的内容推过这个函数进行处理后再替换匹配到的文本。
6. rx.subn(x, s, m):与re.sub()方法相同,区别在于返回的是二元组,其中一项是结果字符串,一项是做替换的个数。
7. rx.split(s, m):分割字符串,返回一个列表,用正则表达式匹配到的内容对字符串进行分割
如果正则表达式中存在分组,则把分组匹配到的内容放在列表中每两个分割的中间作为列表的一部分,如:
rx = re.compile(r"(\d)[a-z]+(\d)")
s = "ab12dk3klj8jk9jks5"
result = rx.split(s)
返回['ab1', '2', '3', 'klj', '8', '9', 'jks5']
8. rx.flags():正则表达式编译时设置的标志
9. rx.pattern():正则表达式编译时使用的字符串
2.5 总结
1. 对于正则表达式的匹配功能,Python没有返回true和false的方法,但可以通过对match或者search方法的返回值是否是None来判断
2. 对于正则表达式的搜索功能,如果只搜索一次可以使用search或者match方法返回的匹配对象得到,对于搜索多次可以使用finditer方法返回的可迭代对象来迭代访问
3. 对于正则表达式的替换功能,可以使用正则表达式对象的sub或者subn方法来实现,也可以通过re模块方法sub或者subn来实现,区别在于模块的sub方法的替换文本可以使用一个函数来生成
4. 对于正则表达式的分割功能,可以使用正则表达式对象的split方法,需要注意如果正则表达式对象有分组的话,分组捕获的内容也会放到返回的列表中
匹配对象的属性与方法
01. m.group(g, ...)
返回编号或者组名匹配到的内容,默认或者0表示整个表达式匹配到的内容,如果指定多个,就返回一个元组
02. m.groupdict(default)
返回一个字典。字典的键是所有命名的组的组名,值为命名组捕获到的内容
如果有default参数,则将其作为那些没有参与匹配的组的默认值。
03. m.groups(default)
返回一个元组。包含所有捕获到内容的子分组,从1开始,如果指定了default值,则这个值作为那些没有捕获到内容的组的值
04. m.lastgroup()
匹配到内容的编号最高的捕获组的名称,如果没有或者没有使用名称则返回None(不常用)
05. m.lastindex()
匹配到内容的编号最高的捕获组的编号,如果没有就返回None。
06. m.start(g):
当前匹配对象的子分组是从字符串的那个位置开始匹配的,如果当前组没有参与匹配就返回-1
07. m.end(g)
当前匹配对象的子分组是从字符串的那个位置匹配结束的,如果当前组没有参与匹配就返回-1
08. m.span()
返回一个二元组,内容分别是m.start(g)和m.end(g)的返回值
09. m.re()
产生这一匹配对象的正则表达式
10. m.string()
传递给match或者search用于匹配的字符串
11. m.pos()
搜索的起始位置。即字符串的开头,或者start指定的位置(不常用)
12. m.endpos()
搜索的结束位置。即字符串的末尾位置,或者end指定的位置(不常用)
结论
- 对于正则表达式的匹配功能,Python没有返回true和false的方法,但可以通过对match或者search方法的返回值是否是None来判断
- 对于正则表达式的搜索功能,如果只搜索一次可以使用search或者match方法返回的匹配对象得到,对于搜索多次可以使用finditer方法返回的可迭代对象来迭代访问
- 对于正则表达式的替换功能,可以使用正则表达式对象的sub或者subn方法来实现,也可以通过re模块方法sub或者subn来实现,区别在于模块的sub方法的替换文本可以使用一个函数来生成
- 对于正则表达式的分割功能,可以使用正则表达式对象的split方法,需要注意如果正则表达式对象有分组的话,分组捕获的内容也会放到返回的列表中

 浙公网安备 33010602011771号
浙公网安备 33010602011771号