

js一些简单逆向题目实战
http://match.yuanrenxue.com/match/12
直接分析charles抓包,然后对抓到的包进行重放攻击,发现依旧可以获取访问的数据
对比参数变化,没有变化, 现在我们进行翻页。发现唯一变化的就是url后面带的m
直接在网页里面全局搜索m的不大现实,由于网页是xhr动态加载的,m的生成应该和在加载有关,所有我们此时在xhr打上断点
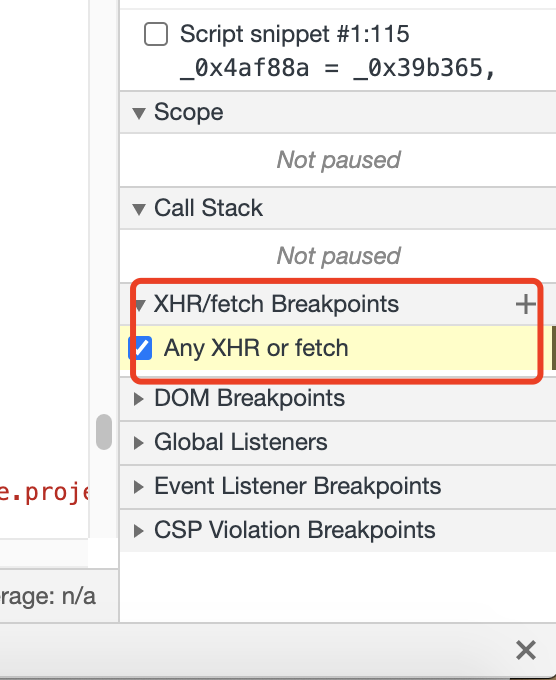
然后我们进行翻页, 查看调用堆栈信息
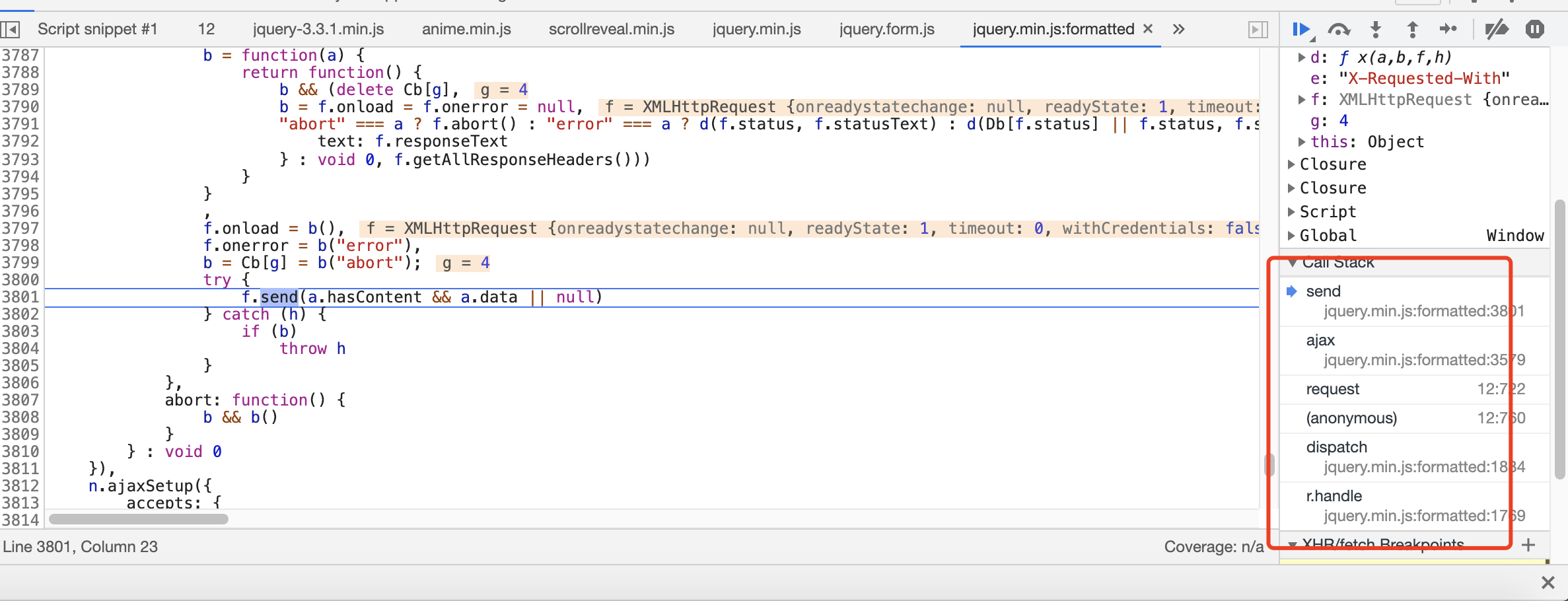
这下面的一个个的点点看,找找是否有m
找到了

我们断点调试查看是否验证是否和charles抓包的一样,验证正确
第二题
http://match.yuanrenxue.com/match/13
我们对他进行重发攻击,发现不不行
这种的话就可能是cookie加密,先用js代码生成cookie,再刷新网页调用
我们用charles找找其他的url,看看有没有js代码
找到了
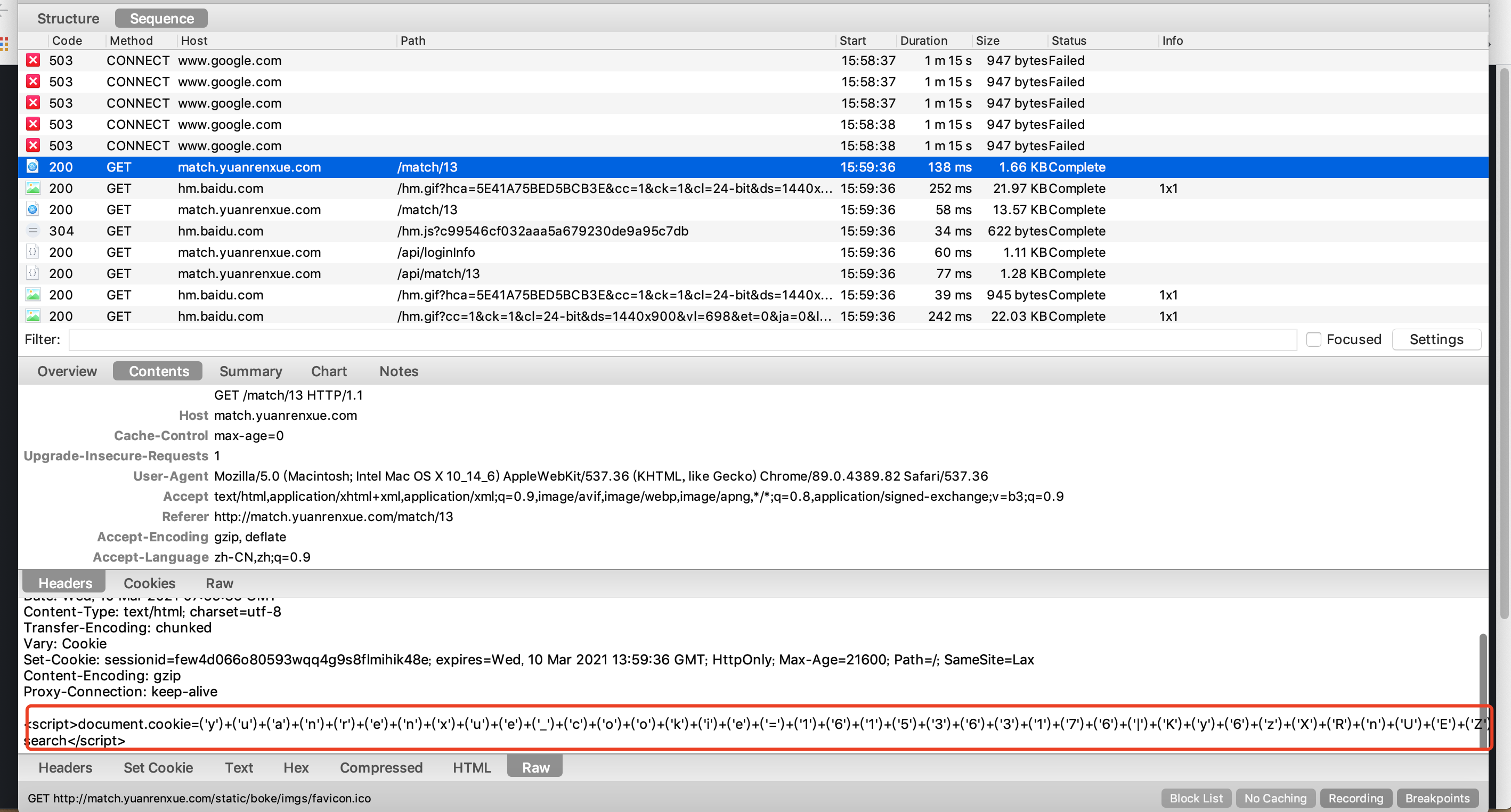
我们把复制,放到控制台进行打印输出,看结果

发现这个代码就是生成cookie的必要代码,而后面的locaktion.href的操作是将网页刷新。
我们想先把生成cookie的js文件请求现在,放到execjs里面 进行执行,然后吧生成的cookie带到api json接口操作就可以了
import execjs
import requests
import re
cookies = {
'sessionid': 'few4d066o80593wqq4g9s8flmihik48e',
'Hm_lvt_c99546cf032aaa5a679230de9a95c7db': '1615262985',
'Hm_lvt_9bcbda9cbf86757998a2339a0437208e': '1615282305',
'qpfccr': 'true',
'no-alert2': 'true',
'm': '155',
'Hm_lpvt_9bcbda9cbf86757998a2339a0437208e': '1615360803',
'yuanrenxue_cookie': '1615362909|lKmD2PHdafvtklyM85tn1R0SK6ZT4dvLS8BJ4G0vVvgrhhTFwOajq4HWJoWrd10pR8wLUjkxyaJV7cgofqqew8rFt7IFNGx4IL8Y4',
'Hm_lpvt_c99546cf032aaa5a679230de9a95c7db': '1615362920',
}
headers = {
'Host': 'match.yuanrenxue.com',
'Cache-Control': 'max-age=0',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Referer': 'http://match.yuanrenxue.com/match/13',
'Accept-Language': 'zh-CN,zh;q=0.9',
}
response = requests.get('http://match.yuanrenxue.com/match/13', headers=headers, cookies=cookies)
# print(response.text)
regex="<script>document.cookie=(.*?)</script>"
pat=re.compile(regex,re.S)
dd_list=pat.findall(response.text)
js_f='document.cookie='+dd_list[0].split(';')[0]+';'+dd_list[0].split(';')[1]
#仅仅针对访问路径而言,实际上cookie用不到这一段
# print(js_f)
jscode=f"""
document = new Object();
location = new Object();
function result() {{
{js_f};
return document.cookie
}}
"""
cookie=execjs.compile(jscode).call('result')
cookie=cookie.split('=')[1].split(';')[0]
cookies = {
'sessionid': 'few4d066o80593wqq4g9s8flmihik48e',
'Hm_lvt_c99546cf032aaa5a679230de9a95c7db': '1615262985',
'Hm_lvt_9bcbda9cbf86757998a2339a0437208e': '1615282305',
'qpfccr': 'true',
'no-alert2': 'true',
'm': '155',
'Hm_lpvt_9bcbda9cbf86757998a2339a0437208e': '1615360803',
'yuanrenxue_cookie': cookie,
'Hm_lpvt_c99546cf032aaa5a679230de9a95c7db': '1615365577',
}
headers = {
'Proxy-Connection': 'keep-alive',
'Pragma': 'no-cache',
'Cache-Control': 'no-cache',
'Accept': 'application/json, text/javascript, */*; q=0.01',
'User-Agent': 'yuanrenxue.project',
'X-Requested-With': 'XMLHttpRequest',
'Referer': 'http://match.yuanrenxue.com/match/13',
'Accept-Language': 'zh-CN,zh;q=0.9',
}
data_List=[]
for page in range(1,6):
params = (
('page', page),
)
response = requests.get('http://match.yuanrenxue.com/api/match/13', headers=headers, cookies=cookies, params=params,verify=False)
dd_list=[]
for i in response.json()['data']:
value=int(i['value'])
dd_list.append(value)
data_List.append(sum(dd_list))
print(sum(data_List))
代码操作

