
scrapy分布式爬虫
需要安装scrapy_redis .正常写入scrapy爬虫,写好后在setttings里面添加如下代码
# 1、使用scrapy_redis的调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 2、使用scrapy_redis的去重机制
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# 3、是否清除请求指纹,True:不清除 False:清除(默认)
SCHEDULER_PERSIST = True
# 4、(非必须)在ITEM_PIPELINES中添加redis管道
'scrapy_redis.pipelines.RedisPipeline': 200
# 5、定义redis主机地址和端口号,密码(没有可不写)
REDIS_HOST = '45.132.238.74'
REDIS_PORT = 6379
密码没有可不写
REDIS_PARAMS = {
'password': 'qwer123456',
}
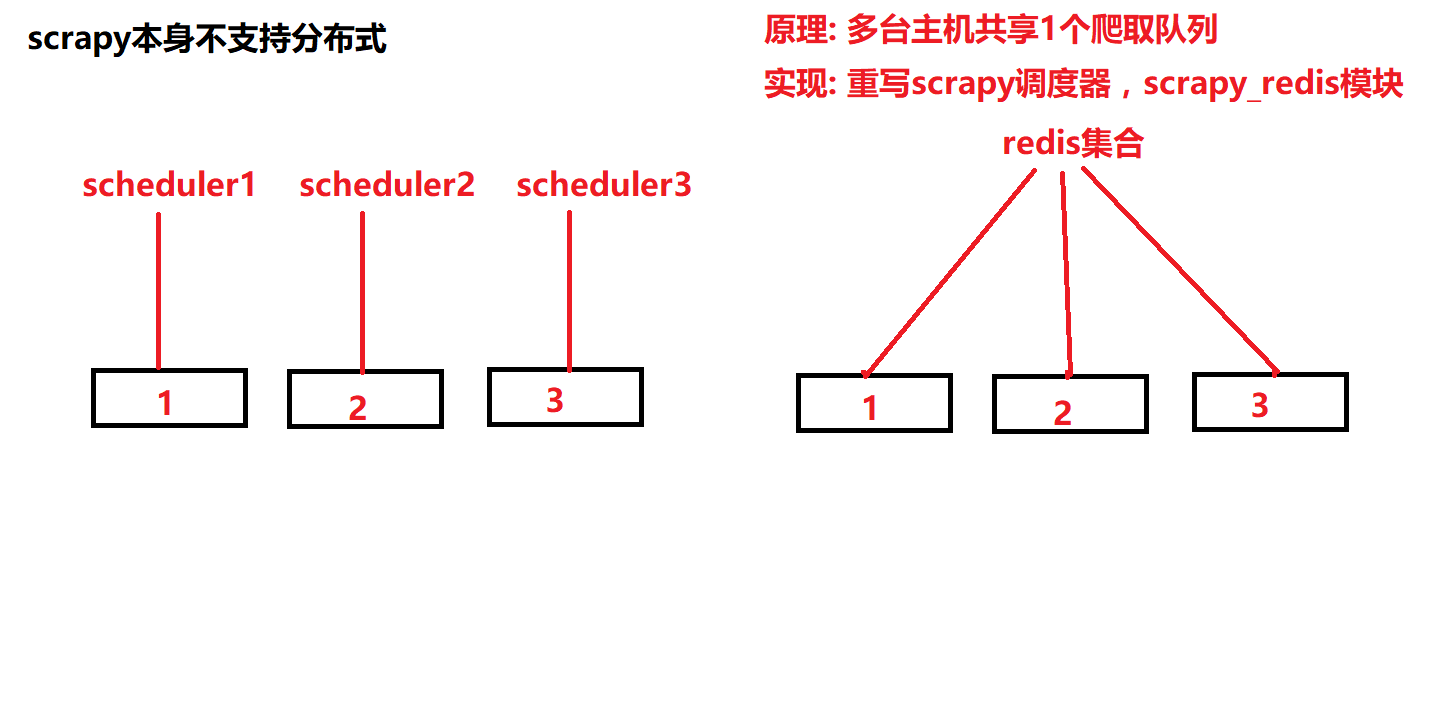
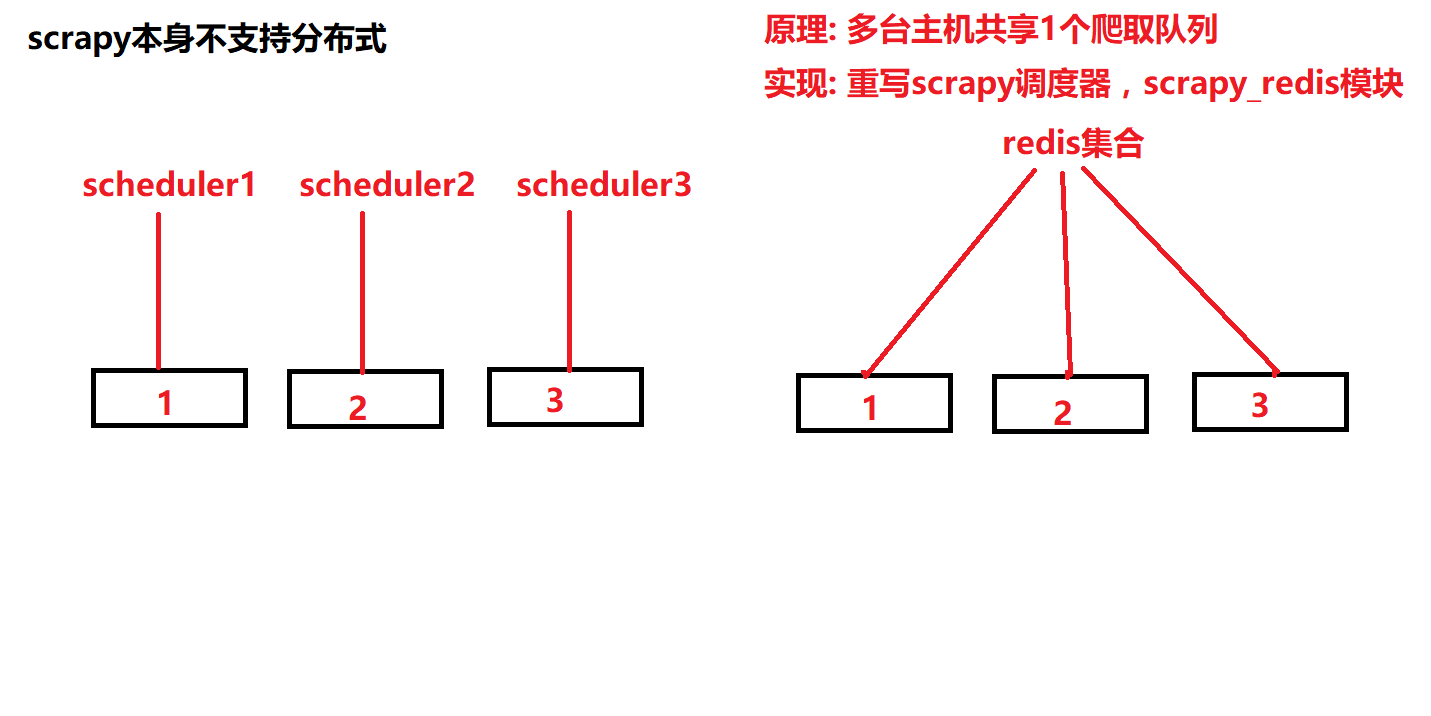
原理:多个服务器共享一个url队列,此队列存储在redis里面,爬取时会在指定的redis数据库中创建url队列,还有指纹信息,多个服务器请求时,redis分发url给不同的服务器,共同抓取数据,指纹信息默认不清除,
这样可以断点续爬。
redis命令:keys * 查看所有的健
lrang key 0 -1 显示所有的数据
llen key 显示数量
方法二
# 第一步: settings.py无须改动
settings.py和上面分布式代码一致
# 第二步:tencent.py
from scrapy_redis.spiders import RedisSpider
class TencentSpider(RedisSpider):
# 1. 去掉start_urls
# 2. 定义redis_key
redis_key = 'tencent:spider'
def parse(self,response):
pass
# 第三步:把代码复制到所有爬虫服务器,并启动项目
# 第四步
到redis命令行,执行LPUSH命令压入第一个要爬取的URL地址
>LPUSH tencent:spider 第1页的URL地址
# 项目爬取结束后无法退出,如何退出?
setting.py
CLOSESPIDER_TIMEOUT = 3600
# 到指定时间(3600秒)时,会自动结束并退出

